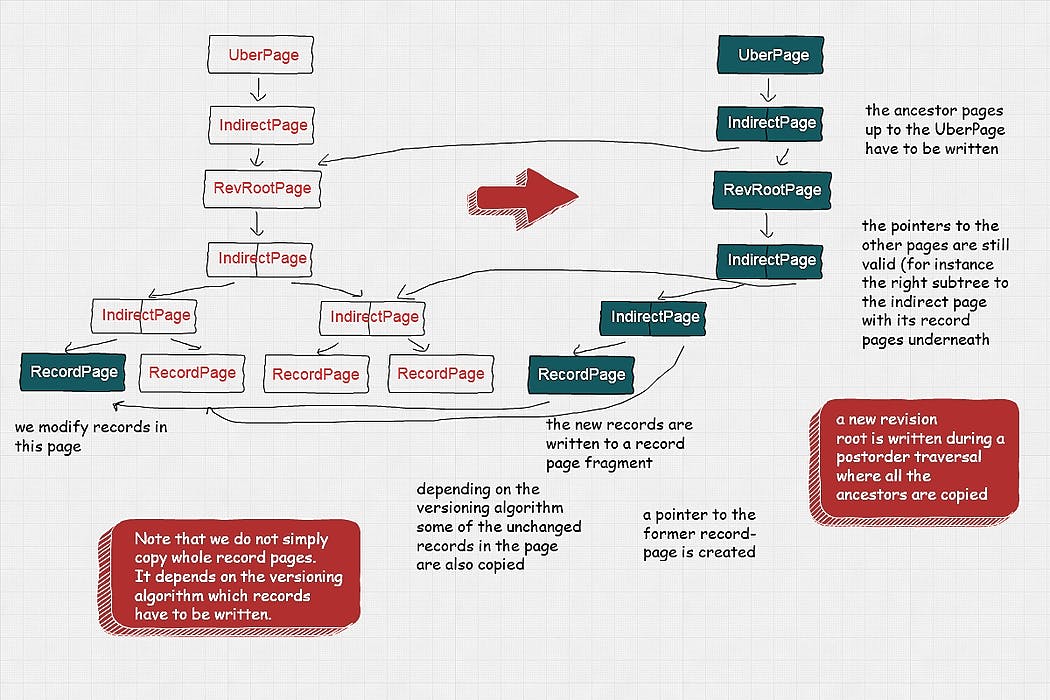
How we built an asynchronous, temporal RESTful API for Sirix.io (Open Source) Interactive Visualization — Uses Hierarchical Edge Bundles to visualize moved nodes. Why storing historical data becomes feasible nowadays Life is subdued to constant evolution. So is our data, be it in research, business or personal information management. As such it’s surprising that databases usually just keep the current state. With the advent, however of flash drives as for instance SSDs, which are much faster in randomly accessing data in stark contrast to spinning disks and not very good at erasing or overriding data, we are now capable of developing clever versioning algorithms and storage systems to keep past states while not impeding efficiency/performance. Search/insertion/deletion-operations should therefore be in logarithmic time (O(log(n)), to compete with commonly used index structures. The temporal storage system SirixDB is a versioned, temporal storage system, which is log-structured at its very core. Sirix We support transactions, which are bound to a (each transaction might be started on any past revision) to transaction on a single resource. Our system thus is based on . The write-transaction can revert the most recent revision to any past revision. Changes to this past revision can then be commit to create a new snapshot and therefore a new revision. N read-only single revision concurrently one write snapshot isolation Writes are batched and synced to disk in a post-order traversal of the internal index tree-structure, during a transaction commit. Thus we are able to store hashes of the pages in parent-pointers just like . ZFS for future integrity checks Snapshots, that is new revisions are created during every commit. Apart from a numerical , the is serialized. A revision can afterwards be opened either by specifying the ID or the timestamp. Using a timestamp involes a binary-search on an array of timestamps, stored persistently in a second file and loaded in memory on startup. The search ends if either the exact timestamp is found or the closest revision to the given point in time. Data is never written back to the same place and thus not modified in-place. . It’s thus especially well suited for flash-based drives as for instance SSDs. Changes to a resource within a database occur within the aforementioned resource-bound single write-transaction. Therefore, first a ResourceManager has to be opened on the specific resource to start single resource-wide transactions. Note, that we already started work on database wide transactions :-) revision-ID timestamp Instead, Sirix uses copy-on-write (COW) semantics at the record-level (creates page-fragments and usually doesn’t copy whole pages). Everytime a page has to be modified records, which have changed as well as some of the unchanged records are written to a new location. Which records exactly are copied depends on the versioning algorithm used We recently wrote another with much more background information on the principles behind Sirix. article Simple, transaction cursor based API The following shows a simple Java code to create a database, a resource within the database and the import of an XML-document. It will be shredded to our internal representation (which can be thought of as a persistent DOM implementation, thus both an in-memory layout as well as a binary serialization format is involved). The native storage of JSON will be the next. In general every kind of data could be stored in Sirix as long as it can be fetched by a generated sequential, stable record-identifier, which is assigned by Sirix during insertion and a custom serializer/deserializer is plugged in. However, we are working on several small layers for natively storing JSON data. Vert.x, Kotlin/Coroutines and Keycloak on the other hand is closely modeled after Node.js and for the JVM. Everything in Vert.x should be non blocking. As thus a single thread called an event-loop can handle a lot of requests. Blocking calls have to be handled on a special Thread Pool. Default are two event-loops per CPU (Multi-Reactor Pattern). Vert.x We are using , because it’s simple and concise. One of the features, which is really interesting are coroutines. Conceptually they are like very lightweight threads. While creating threads is very expensive creating a coroutine is not. Coroutines allow to writing of asynchronous code almost like sequential. Whenever it is suspended due to blocking calls or long running tasks, the underlying thread is not blocked and can be reused. Under the hood each suspending function gets another parameter through the Kotlin compiler, a continuation, which stores where to resume the function (normal resuming, resuming with an exception). Kotlin is used as the authorization server via OAuth2 (Password Credentials Flow), as we decided not to implement authorization ourselves. Keycloak Things to consider when building the Server First, we have to decide, which flow best suits our needs. As we built a REST-API usually not consumed by user agents/browsers we decided to use the It is as simple as this: first get an access token, second send it with each request in the Authorization header. OAuth2 Pasword Credentials Flow. In order to get the access-token, first a request has to be made against a route with the username/password credentials sent in the body as a JSON-object. POST /login — The implementation looks like this: The coroutine-handler is a simply extension function: Coroutines are launched on the Vert.x event loop (the dispatcher). In order to execute a longer running handler we use Vert.x uses a different thread pool for these kind of tasks. The task is thus executed in another thread. Beware that the event loop isn’t going to be blocked, the coroutine is going to be suspended. API design by example . We first need to set up our server and Keycloak (read on how to do this). Now we are switching the focus to our API again and show how it’s designed with examples http://sirix.io Once both servers are up and running, we’re able to write a simple HTTP-Client. We first have to obtain a token from the endpoint with a given "username/password" JSON-Object. Using an asynchronous HTTP-Client (from Vert.x) in Kotlin, it looks like this: /login This access token must then be sent in the Authorization HTTP-Header for each subsequent request. Storing a first resource looks like this(simple HTTP PUT-Request): First, an empty database with the name with some metadata is created, second the XML-fragment is stored with the name . The PUT HTTP-Request is idempotent. Another PUT-Request with the same URL endpoint would just delete the former database and resource and recreate the database/resource. database resource1 The HTTP response-code should be 200 (everything went fine) in which case the HTTP-body yields: We are serializing the generated IDs from our storage system for element-nodes. Via a to we are also able to retrieve the stored resource again. GET HTTP-Request https://localhost:9443/database/resource1 However, this is not really interesting so far. We can update the resource via a . Assuming we retrieved the access token as before, we can simply do a POST-Request and use the information we gathered before about the node-IDs: POST-Request The interesting part is the URL we are using as the endpoint. We simply say, select the node with the ID 3, then insert the given XML-fragment as the first child. This yields the following serialized XML-document: Every PUT- as well as POST-request implicitly the underlying transaction. Thus, we are now able send the first GET-request for retrieving the contents of the whole resource again for instance through specifying a simple XPath-query, to select the root-node in all revisions and get the following XPath-result: commits GET https://localhost:9443/database/resource1?query=/xml/all-time::* Note, that we used a time-traveling axis in the query-parameter. In general we support several additional temporal XPath axis: future, future-or-self, past, past-or-self, previous, previous-or-self, next, next-or-self, first, last, all-time Time axes are compatible with node tests:<time axis>::<node test>is defined as<time axis>::*/self::<node test>. Of course, the usual way would be, to use one of the standard XPath axis first to navigate to the nodes you are interested in as for instance, the descendant- and/or child-axis, add predicate(s), and then navigate in time, to watch how a node and subtree changed. This is an incredible powerful feature and might be the subject of a future article. The same can be achieved through specifying a range of revisions to serialize (start- and end-revision parameters) in the GET-request: GET [https://localhost:9443/database/resource1?start-revision=1&end-revision=2](https://localhost:9443/database/resource1?start-revision=1&end-revision=2) or via timestamps: GET [https://localhost:9443/database/resource1?start-revision-timestamp=2018-12-20T18:00:00&end-revision-timestamp=2018-12-20T19:00:00](https://localhost:9443/database/resource1?start-revision-timestamp=2018-12-20T18:00:00&end-revision-timestamp=2018-12-20T19:00:00) However, if we first open a resource, then via a query select individual nodes, it is faster to use the time traveling axis, otherwise the same query has to be executed for each opened revision (parsed, compiled, executed…). We for sure are also able to delete the resource or any subtree thereof by an updating XQuery expression (which is not very RESTful) or with a simple HTTP-request: DELETE This deletes the node with ID 3 and in our case as it’s an element node the whole subtree. For sure it’s committed as revision 3 and as such all old revisions still can be queried for the whole subtree as it was during the transaction-commit (in the first revision it’s only the element with the name “bar” without any subtree). If we want to get a diff, currently in the form of an XQuery Update Statement, simply call the XQuery function which is defined as: sdb:diff sdb:diff($coll as xs:string, $res as xs:string, $rev1 as xs:int, $rev2 as xs:int) as xs:string We could specify other serialization formats for sure. For instance, we can send a GET-request like this on the database/resource1 we created above: GET [https://localhost:9443/?query=](https://localhost:9443/?query=sdb:diff%28%27database%27,%27resource1%27,1,2%29)sdb%3Adiff%28%27database%27%2C%27resource1%27%2C1%2C2%29 Note that the query-String has to be URL-encoded, thus decoded it’s [sdb:diff('database','resource1',1,2)](https://localhost:9443/?query=sdb:diff%28%27database%27,%27resource1%27,1,2%29) and we are comparing revision 1 and 2 (but diffing performance for sure is in the same time complexity for each revision-tuple we compare). The output for the diff in our example is this XQuery-Update statement wrapped in an enclosing sequence-element: This means from is opened in the first revision. Then the subtree is appended to the node with the stable node-ID 3 as a first child. resource1 database <xml>foo<bar/></xml> If you like this, please give us some claps so more people see it or a star on Github… and most importantly check it out ( ) :-) we would love to hear any suggestions, feedback, suggestions for future work, as for instance work on JSON or horizontal scaling in the cloud, bug reports ;-), just everything… please get in contact Our Open Source repository: http://sirix.io