952 reads
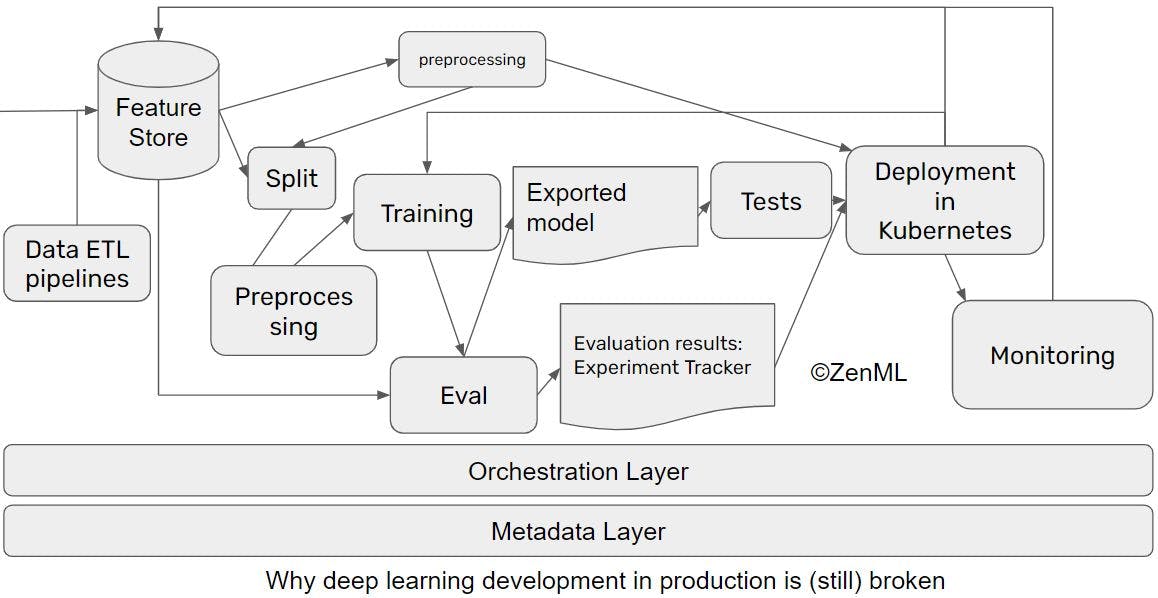
How To Productionalize ML By Development Of Pipelines Since The Beginning
by byHamza Tahir@htahir1
byHamza Tahir@htahir1
Launched stuff on ProductHunt. Open-sourced some things. Developed some nice products.
May 3rd, 2021






Launched stuff on ProductHunt. Open-sourced some things. Developed some nice products.


Launched stuff on ProductHunt. Open-sourced some things. Developed some nice products.
About Author

Launched stuff on ProductHunt. Open-sourced some things. Developed some nice products.
Comments