
2,033 reads
Why ML in Production is (still) Broken and Ways we Can Fix it
by byHamza Tahir@htahir1
byHamza Tahir@htahir1
Launched stuff on ProductHunt. Open-sourced some things. Developed some nice products.
February 1st, 2021





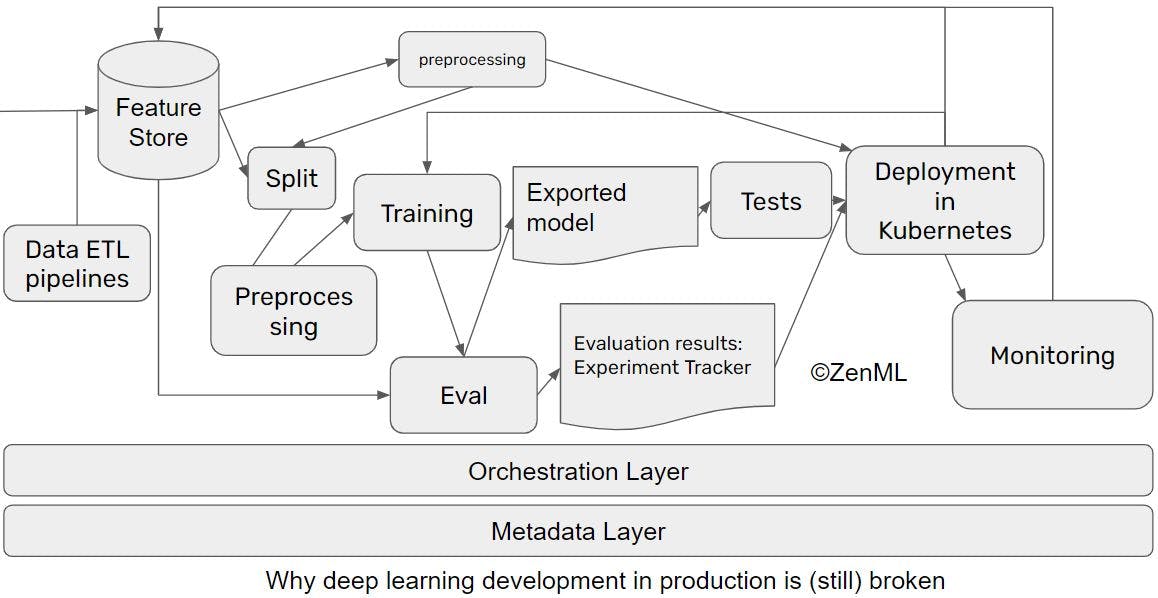
Launched stuff on ProductHunt. Open-sourced some things. Developed some nice products.


Launched stuff on ProductHunt. Open-sourced some things. Developed some nice products.
About Author

Launched stuff on ProductHunt. Open-sourced some things. Developed some nice products.
Comments








![What Are Convolution Neural Networks? [ELI5]](https://hackernoon.imgix.net/images/69s32rn.jpg?auto=format&fit=max&w=3840)








