
1,065 reads
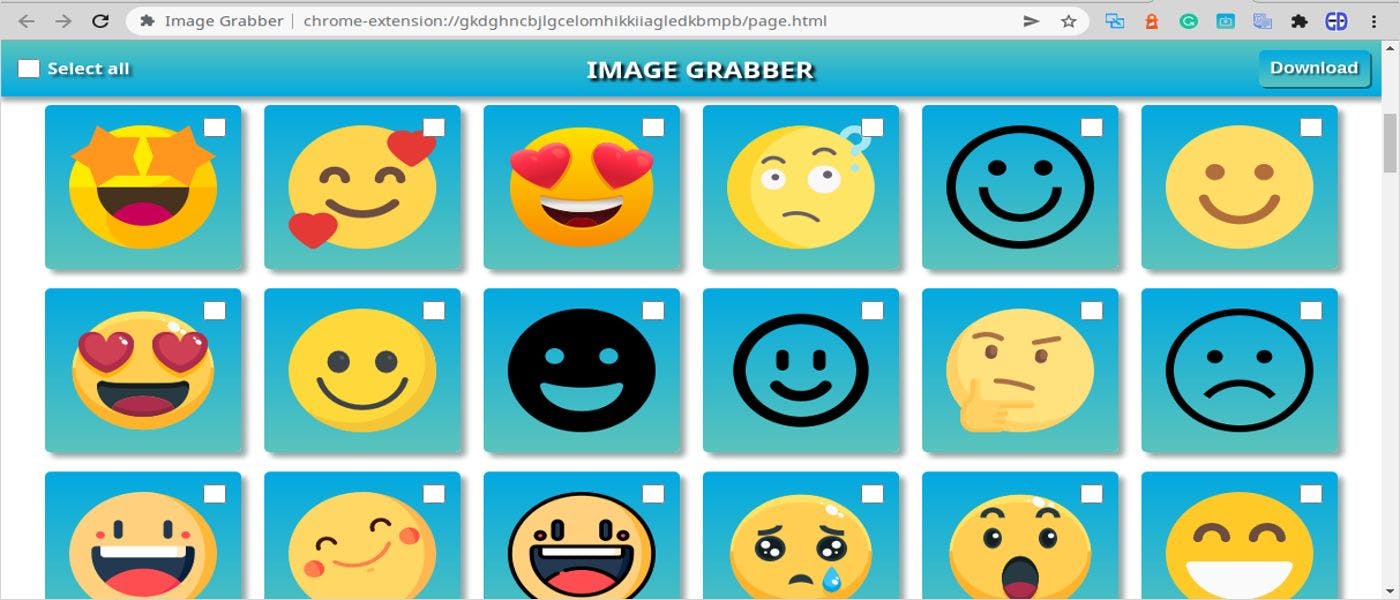
How to Create a Google Chrome Extension Part 2: Image Grabber
by byAndrey Germanov@germanov
byAndrey Germanov@germanov
Software developer and entrepreneur. Develop online services and write about progremming.
December 4th, 2022





Audio Presented by
Software developer and entrepreneur. Develop online services and write about progremming.
Story's Credibility


Software developer and entrepreneur. Develop online services and write about progremming.
Story's Credibility
About Author

Software developer and entrepreneur. Develop online services and write about progremming.
Comments

















