
3,217 reads
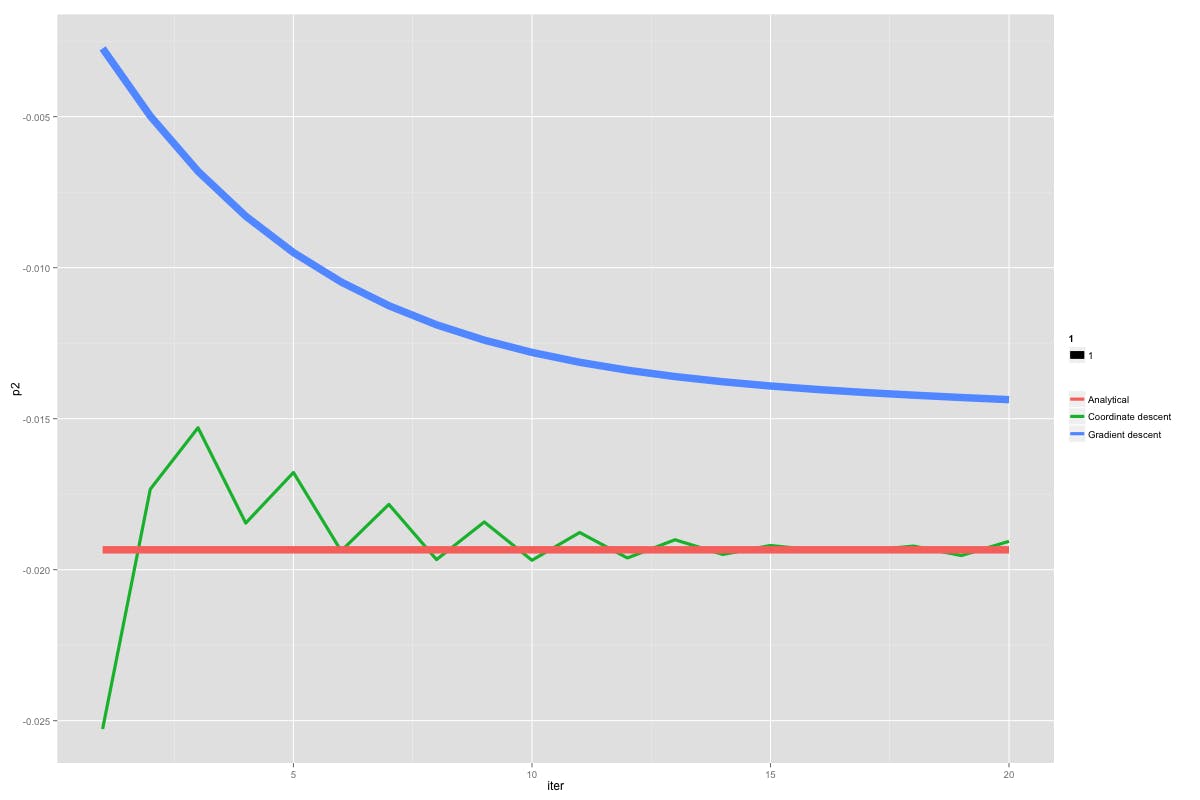
Gradient descent vs coordinate descent
by byFrancesco Gadaleta@frag
byFrancesco Gadaleta@frag
I do stuff with computers, host data science at home podcast, code in Rust and Python
April 12th, 2017





I do stuff with computers, host data science at home podcast, code in Rust and Python


I do stuff with computers, host data science at home podcast, code in Rust and Python
About Author

I do stuff with computers, host data science at home podcast, code in Rust and Python
Comments














