





1,596 reads
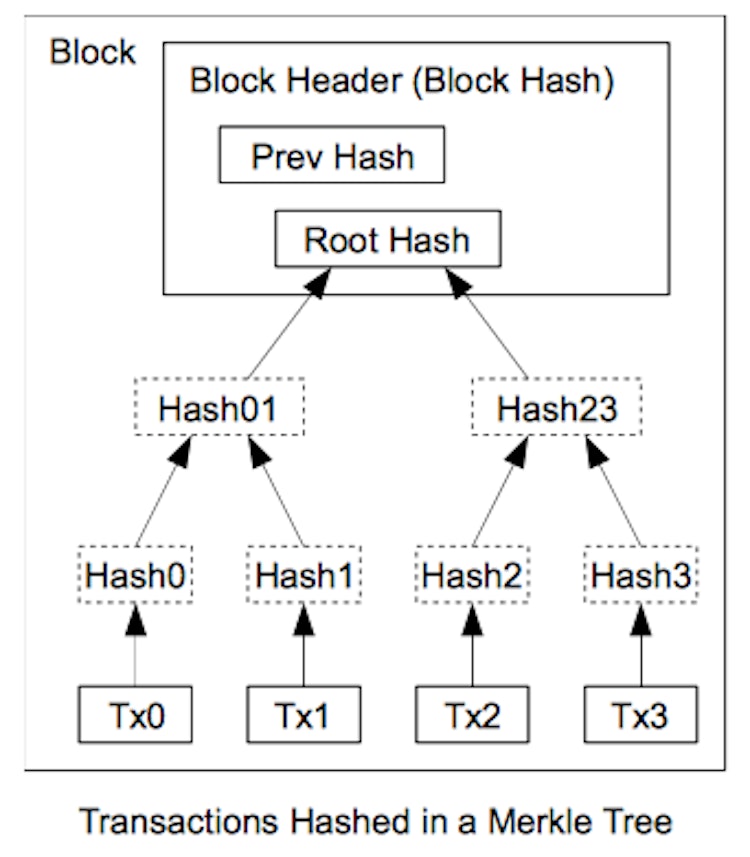
Achieving Blockchain Scalability with Sparse Merkle Trees and Bloom Filters





Too Long; Didn't Read
by <a href="https://medium.com/@abarisser" data-anchor-type="2" data-user-id="174780feb11a" data-action-value="174780feb11a" data-action="show-user-card" data-action-type="hover" target="_blank">Andrew Barisser</a>People Mentioned

Companies Mentioned

Coin Mentioned




Andrew Barisser
@abarisser
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author

TOPICS
THIS ARTICLE WAS FEATURED IN...



RELATED STORIES



A Proposal to Solve Blockchain Scalability #bitcoin
Dec 17, 2017


Bitcoin Halving: Bearish Implications? #bitcoin
Apr 23, 2024



