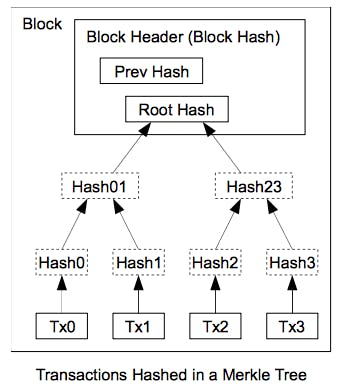
by Andrew Barisser I have been thinking hard about blockchain scalability lately (see my recent article ). I have the outlines of a proposal which I would like to share here for comment and feedback. The goal is no less than to solve the blockchain scalability problem. This is an incredibly audacious goal, but I hope you will at least review my proposal. https://hackernoon.com/wrestling-with-blockchain-scalability-a1295e47962f The Problem For a more in-depth analysis of the problems underlying blockchain scalability, see my article in the link above. In short, to prevent a double spend, each verifier must have a view of all transactions to a double spend transaction. Since this could occur anywhere, in any block, you must look everywhere. Thus to trustlessly verify even just 1 transaction, you must hold an entire blockchain on your device. global rule out the existence of Proof-of-Publication Scales almost Infinitely With current Blockchain technology, we already have a capability called Proof-of-Publication. I can take 2^N pieces of data, hash them, and compose a Merkle Tree with depth N. I can take the Merkle Root of that tree and publish it in a Bitcoin Block. Then for any of the individual pieces of data in the original Merkle Tree, I can provide what is called a Merkle Path (a series of neighbor hashes demonstrating that my leaf hash is a member of the Merkle Tree) to the Merkle Root. This has the effect that I can prove, for any one of my 2^N pieces of data, that it was published as of the Bitcoin Block in which the Merkle Root resides. This scheme scales almost infinitely because what is actually stored in the block is a succinct Merkle Root hash. This is merely a short string. For a tree of length N, it takes log(N) space and computation to demonstrate membership; this scales quite well. I could prove publication of billions or trillions of datapoints in each Bitcoin Block today. The fact that Proof-of-Publication scales so well should suggest that we can do better than the current state of the art. However, as we shall see, it is not itself enough to create a scalable blockchain. It is also not a new idea; it has been around for years in the community. Tokens with Addresses in an Abstract Merkle Tree In my proposed blockchain design, Blocks are produced using Proof-of-Work just as done today in Bitcoin. However each block contains 1 Merkle Root string. This Merkle Root represents a Merkle Tree that is The Merkle Root merely acts as an anchor; whatever was in that tree, which was potentially vast in size, can be provably timestamped using proof-of-publication. not actually present in the blockchain. Using this abstract Merkle Tree, we can create an out of the leaves of that tree. Each leaf corresponds to some binary number which represents the lefts-and-rights navigating one from the Merkle Root to leaf. In short, each leaf can have a unique numeric address. address space In my scheme, each leaf corresponds to a distinct token in the blockchain.To publish a transaction for that token, it is necessary (but not sufficient) to provide a Proof-of-Publication of that transaction . The Merkle Path that proves publication will also prove the fact that this transaction originated from that Merkle Leaf. An otherwise valid transaction originating from a different leaf (than the one corresponding to that token) is not valid. originating from that leaf in the Merkle Tree Proof-of-Publication does not prevent double spends The above gives us certain capabilities, but does not prevent double spends. One of its key features is that it makes it in a block to rule out a double spend (within the same block and only for the token in question). Since a transaction must originate from the Merkle leaf that corresponds with the spent token, the existence of a double spend transaction from any other leaf is not a concern. There is only one place to look. unnecessary to look elsewhere However we have not yet solved the double spend problem. Let’s say I send you a token at Block 25. I show you a Proof-of-Publication of a correctly signed transaction in block 25. That checks out. I also show you a Proof-of-Publication of the transaction in which I was given the token back in Block 10. But I cannot (yet) demonstrate the of publication of any transactions for blocks 11–24. Thus while the transactions in blocks 10 and 25 are valid, and no other valid ones could exist in blocks 10 and 25, I’m still worried about a double spend in 11–24. absence Theoretically you could have a proof-of-publication of a null transaction for blocks 11–24. But this is not a guarantee of the system. A miner can insert junk where you should have a null transaction. I called this a “gibberish attack” in my previous article. The Merkle Tree route breaks down for demonstrating the absence of transactions for blocks 11–24. We need Proof of Absence As I mused in the last article, there needs to be some scheme where I take a set of strings S and produce a succinct commitment to those strings P, such that for any other string X , I can prove that X was not a member of S . In other words, I need to prove non-membership of an element to a set without examining the whole set, but merely a succinct (and non-interactive) commitment to the set. not in S solely by acting on X and P Cryptographic Accumulators After some research, it turns out this functionality does exist. Cryptographic accumulators provide a way to efficiently test the membership of an element to a set without inspecting the whole set. Critically, there are also variants that support testing . non-membership Here is a simplified summary of what dynamic, universal Cryptographic Accumulators do. To prove membership, I start with some value G. For each member X of a set S, I act on G to produce a new witness value. That witness value can be probed, via mechanisms I will not try to explain here, to demonstrate that X was a member of set S without having to carry all of S around. A similar version exists for non-membership proofs. As far as I can tell, the transformations acting on the witness value are publicly verifiable, thus one does not need to trust the veracity of non-membership proofs. A cryptographic accumulator is, like a Merkle Root, a succinct string that can be used for proofs of membership or non-membership. We will include the accumulator witness statement in each block. Because cryptographic accumulators are ‘dynamic’, ie a valid one for set S can be updated for insertions and deletions in S, we can include in each block a global accumulator witness for the entire blockchain history up to that point. How It All Works So here is how my scheme works. Once: Verify block headers using proof-of-work as lite Bitcoin wallets work today. Each block has an accumulator witness derived from the witness of the previous block, as well as a proof to that effect. Verify that proof to ensure that the accumulator for any given block corresponds to the entire blockchain history. When sending a transaction: You need to send the entire proof-of-publication history of all transactions that ever concerned that token. Thus if the transaction concerns block 25, and its input comes from block 10, show proofs for blocks 10 and 25. This is more data than a Bitcoin transaction is today, but thankfully it does not have to be stored on a blockchain. It could go as follow:- Token A was created at Block 0 and was owned by the one-address-that-owned-everything-at-conception. This is self-evident.- Token A was sent from the genesis address to my address at Block 10. There is a proof of publication of this. Critically the sender does a second thing. He reveals a hidden signature value that corresponds to his address and includes it in the cryptographic accumulator for Block 10. To verify the above transaction, I am given the Proof-of-Publication of a valid (signed) transaction at Block 10. This includes a Merkle Path to a Merkle Root that I know is correct (by having validated all block headers). I am given the hidden signature value that was included in the cryptographic accumulator. This value can be a hidden predecessor to the owning address (like a private key, or one of many private keys) such that once I know it, I know it corresponds to the sending address. I verify that this value is a member of the cryptographic accumulator. At the same time, I verify that . Since Block 9 inherits all the signature values from all previous blocks, this has the effect of proving that this signature value is present in Block 10 and had never before been revealed. A transaction is only valid if also uniquely it was not a value of Block 9’s cryptographic accumulator A) It has a valid accompanying Proof-of-Publication B) It is accompanied by a revealed, previously hidden value that links to his address. This value is part of the next Block’s cryptographic accumulator but part of any other block’s accumulator. This is accomplished by proving non-membership of the preceding block’s accumulator, and by proving the successive inheritance of all cryptographic accumulators across blocks. not Steps A) and B) above must be repeated for all transactions of that token throughout history to demonstrate that a double spend has never occurred. Thus it is not enough to prove a transaction, we must prove that transaction’s predecessor, and that one’s, until genesis. This is feasible because all block headers are verified and these are relatively short proofs a client device can perform. Note that the purpose of the revealed, hidden signature value is to create a provable test that double-spend attempts will fail to defeat. This value must be hidden until use and lead deterministically to the spending public address. It must be apparent to future token recipients that no other signature value could have existed for this address-token pair, thus when they rule out its membership in a block’s accumulator, they have ruled out all spends coming from that address for that token. I believe that the above resolves the double spend problem without including massive amounts of data in a global blockchain. Proof-of-Publication, which is known to scale very well, is coupled with succinct non-membership proofs in cryptographic accumulators. The amount of data in each block is minimal. This design shifts the burden of computation to individual owners and receivers. They can prove the validity of their coins without proving the validity of all coins. Similarly, the existence of Proofs-of-Publications of double spends is not a problem; they will not pass the cryptographic accumulator tests. Some Issues There are some issues and gaps that I would like to enumerate here. My chief concern is that succinct, dynamic, non-membership proofs via Cryptographic Accumulators are pretty esoteric math. I would like more evidence that they work as advertised and that I have represented them properly. A real cryptographer should review my interpretation carefully. These underpin the whole solution. My scheme involves non-fungible tokens rather than fungible units like Bitcoins. I don’t think this is a huge problem; you can construct fine-grained transactions from sets of token exchanges. It is slighlty non-optimal. I would not be surprised if a fungible version could be constructed using similar ideas. A miner has to aggregate all this data into cryptographic accumulators and Merkle trees for them to be published. The miner has to return information to the transaction’s publisher for them to have adequate information to provide transaction proofs. This back and forth introduces complications that do not exist in Bitcoin, where transaction publishing is 1-way only. Worse, a malicious miner could take the revealed, hidden value intended to be part of an accumulator, and include it without including the corresponding leaf in the Merkle Tree. This would lead to a situation in which it would appear I had committed a double-spend when I in fact had not. This can be resolved via several routes; for instance the hidden signature could be revealed a Proof-of-Publication has already succeeded, removing this risk. This is acceptable because orphaned proofs-of-publication have no cost. Thus I believe there are avenues around this problem. the block after This scheme imposes a larger burden on owners of tokens. They must store more data and pass it along. If the transactional proofs are lost, the tokens will be stuck, as they are today with lost Bitcoin private keys. Arguably more computation is required for recipients to confirm transactions. I believe that this is worth the trade-off in Blockchain scalability. If my proposal works, it could allow for vastly improved blockchain scalability. The only real limits would be in connectivity to miners during the interval between blocks. Miners could cram as much as possible into Merkle Trees and cryptographic accumulators without extra burden to block size. I am a bit concerned by the audacity of this proposal that I have missed some critical flaw. I also admit that many parts are not well-defined; this is in part because I am still digesting these ideas. I invite maximal scrutiny and review of this proposal, in particular the feasibility of using non-membership proofs in succinct cryptographic accumulators in the adversarial environment of decentralized blockchains. Feel free to ping me on Twitter for ideas, feedback, or comments. Twitter: https://twitter.com/abarisser 1JZBGMjZxVG1u4WzwAFzKEgHCpfG4YSWhe