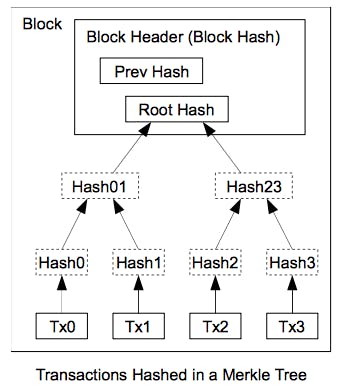
by Andrew Barisser Problems with scaling are a primary factor blocking broader adoption of blockchain technologies like Bitcoin. These systems as they exist today simply won’t scale. We are forced to ask the question again and again, how can we extend the trustless paradigm across millions and billions of users if, to remain trustless, every user must validate very transaction? In this post I will lay out my thoughts on the matter, and propose a system involving Sparse Merkle Trees used in conjunction with Bloom Filters. It will retain many of the features of Bitcoin, namely Proof-of-Work and confirmation of block headers. But I lay out a proposal which I hope can attain 10x or more scalability over the current system, which currently relies on global verification of state. The key to improved scalability is to make it unnecessary to have a global view of all transactions to verify the validity of any single transaction. Sparse Merkle Trees First, let me introduce Sparse Merkle Trees. These are except that they have only sparsely populated child nodes at potentially extreme depths. So for instance, one can imagine a Merkle tree with depth 256. Such a tree will have 2²⁵⁶ leaf nodes, more than the number of subatomic particles in the visible universe. However imagine that only some limited subset of these leaf nodes are populated with data. The rest are “empty” leaf nodes. The parents of empty leaf nodes are themselves predictable. The entire tree is sparse because very few available paths are occupied. For more information, check out my (known as SMT). Merkle Trees Python implementation of Sparse Merkle Trees Bloom Filters are probabilistic data structures that allow a fixed-length representation to cache the presence of elements in a set. It has no false negatives. The trick is, it has probabilistic false positives. The rate of false positives is a function of the ratio between the amount of space allocated to the Bloom Filter and the number of elements stored in it. There are formulas to calculate the optimal bloom filter construction, and you can find a nice calculator . As an example, one can create a bloom filter with a 10^-9 false positive error rate for 44 bits / stored-element. Thus a filter expected to store up to 1000 elements will consume 44kB of space, and provide a 0.0000001% probability of a false positive for any non-member elements. Bloom Filters here Bloom Filters are commonly used across many different applications. Key Elements to Verify a Transaction Blockchains allow users to verify all transactions independently, without having to trust any single entity. We can boil this down to a few core operations necessary to fully validate any one transaction. Verify all the block headers and find the longest Proof-of-Work branch of blocks. Verifying block headers establishes a canonical source of truth, but it does not verify the consistency of what is the blocks; for all we know it could be contradictory gibberish if we do not look further. inside Verify that a given transaction is “internally” correct. In other words, the transaction is correctly signed from sender to receiver, well formatted, etc. This is completely straightforward and does not require blockchains, only elliptic curve cryptography. This is a solved problem but I include it here for completeness. Verify that a transaction “took place” when it is supposed to have taken place. This can be restated as confirming that a transaction is a member of a given block. Verify that a transaction was not spent , either within the current block, or in any preceding block. If someone spends an unspent output to send me Bitcoin, I must verify that that same unspent output is truly unspent. In Bitcoin, I accomplish this by viewing transactions. By maintaining a global view of state, I can rule out double-spends. This leads directly to the scalability problem. It is not enough to know that 1 transaction is correct. I must know that it is not correct everywhere else! Thus I must inspect every transaction in every block. elsewhere all Problem #1 was solved by Bitcoin and is implemented in . These confirm block headers only. These are extremely space efficient and scalable. Thin clients solve Problem #3. Because Bitcoin Block headers include Merkle Roots of transactions, it is simple to prove membership of a transaction in a block. Problem #2 does not require a Blockchain solution, and is solved with 1970’s era cryptography. But Thin clients do not solve problem #4. Even if I can prove that a valid transaction occurred in a block, in the same block, or in a previous block, with block header information alone. Thin Bitcoin clients I cannot prove that it did not occur elsewhere Problem #4 is the key problem to solve. Achieving Scalability Now that I have framed the problem, let me concisely lay out a possible solution. A new cryptocurrency has a proof-of-work algorithm and block headers just like Bitcoin today. All participants verify block headers and PoW solutions on their own. This part is very scalable and easy. Let us imagine that our new cryptocurrency consists of a finite number of non-fungible tokens. Instead of bundling and reshuffling satoshi, each coin has a label and a history. There are probably schemes to create fungible tokens abstracted over non-fungible ones, but this is not relevant to our discussion. Inside each block, we do something different. We add 2 data structures. First we add a Sparse Merkle Tree (SMT). Using the SMT, we prove of transactions. Each leaf in our SMT represents an address for a non-fungible coin. This can be thought of simply as a unique binary number, representing the sequence of left’s and right leading from the Merkle Root to the leaf node. We create a semantic rule. Any transaction concerning a given non-fungible token with ID=N must be published at leaf node N of a SMT in a block. Any transactions at incorrect leaf node positions can be ignored. membership The use of SMT’s lends a nice property to our system; for any given block and for any given token, there is only one place where a spend transaction can occur. Thus I only need to look in one place per block; no where else is valid. Proving membership with SMT’s is fairly trivial and can be done today quite easily. The hard part is proving non-membership in all other blocks. Enter Bloom Filters. Each block also has a Bloom Filter of some length M that can contain a maximum of N elements with a false positive rate of P. The purpose of the Bloom Filter is to verify the presence or non-presence of a transaction in a block. So we create a new rule. For a transaction to be valid, we take the following steps: Sign a transaction sending token T from sender A to recipient B. Submit the hash of this transaction H with leaf_node_position=T to miners. Miners include the hash (H) in a SMT at block=Q at leaf_node_position T. The SMT is published in full; every leaf node is listed in the block. The sender looks at the SMT in block Q and calculates a Merkle path leading from their transaction hash to the Merkle Root. They confirm that this is correctly constructed. Then the sender the block’s SMT data and retains header data only (which includes the SMT root only). discards At Block Q+1, the sender submits a second item to miners. They produce a deterministic signature of the following concatenated items: transaction hash, token_id, Merkle Root from Block Q. This signature is hashed and submitted to the miners for inclusion in the Bloom Filter. The sender now has a proof of transaction. The SMT Merkle Path from Block Q and the Bloom Filter from Block Q+1. These are forwarded to the token receiver for verification off-chain, as well as the underlying transaction itself. The sender also creates deterministic signatures as they for all previous blocks <Q+1 and forwards these to the receiver. would have existed The token receiver verifies all block headers. Then they verify the internal correctness of the transaction. Then they verify membership of the transaction hash in the SMT from Block Q at the correct leaf node position T. This involves merely validating the provided Merkle Path. The receiver needs to confirm that the correct signature lives in the Bloom Filter at Block Q+1. They verify that the provided Q+1 signature is correct. They then verify membership of that signature in the Bloom Filter at Q+1. Finally, one must verify non-membership in preceding blocks. The sender has already sent every retroactive digital signatures for all preceding blocks <Q+1. The receiver verifies these signatures. Then he verifies that they are members of all bloom filters in blocks < Q+1. not Since membership of the signature in a Bloom Filter at block Q+1 is required for a transaction to be valid, its absence in preceding blocks means it was never spent! I believe this neatly gets around the non-membership problem #4 having to maintain a global view of all transactions. without Questions and Answers Q: What if miners do not faithfully publish a correct SMT? A: A transaction sender only needs to verify their own Merkle Path at the correct leaf node. It does not matter if the rest is gibberish. It cannot be verified by anyone. If a sender submits a transaction and it is not included in an SMT, or anything goes wrong with SMT construction, nothing is lost, and the sender may try again later. This is why SMT construction and Bloom Filter signature addition are in separate blocks. The former can be ignored if something goes wrong, the latter cannot be! Q: What if miners do not faithfully publish a correct Bloom Filter? A: This is trickier. We have to add constraints. The Bloom filter must not have more than N elements, where N is fixed per block at some number. This can be verified by asserting that the number of filled bits does not exceed some number. Another attack vector is for a miner to maliciously add a transaction signature to a block bloom filter where the transaction was never really spent. This would make the transaction spent to verifiers and thus be effectively unusable. This is why I introduced the concept of deterministic signatures that include the block’s Merkle Root. These signatures cannot be faked without knowing the sender address’s private key, which is unknown at the time of publishing. By including a reference to the preceding Merkle Root, they are only valid for blocks referencing a known SMT Merkle Path proof, and cannot be used on forked branches where that Merkle Path does not apply. appear preceding It is imperative that miners are not allowed to predict the value of a digital signature before its addition to the bloom filter, as they could then maliciously include it in the wrong block. This is why a secret, which is revealed later, is necessary for use in the signature. If it is known in advance, it will not work. Moreover, the digital signature includes a reference to the appropriate SMT so that a signature cannot be reused in cousin or other blocks. Q: Why are both SMTs and Bloom Filters necessary? A: Each gives us something different. The SMT allows us to attach any data at all to a specific block under a specific leaf with an associated ID number. The bloom filter allows us to check for the existence, and non-existence, of an element known up front by the checker for all blocks. Q: How does this achieve Blockchain Scalability? A: In my proposal, blocks consist of 3 pieces a short block header, including the SMT Merkle Root a long bloom filter all the occupied leaves of an SMT (hashes only) A verifier only needs to store the block headers and bloom filters. The SMT leaves are included only for They use SMT leaves to calculate their own, personal Merkle Paths, then they may discard the SMT data. In other words, SMT data is only necessary transiently for the sender and they may store only a small subset of that data. senders. This formulation will allow for a lot more transactions per block. At a false positive rate of 10^-9, 1mB Bloom Filters can store approximately 200,000 elements. The Block header information is trivially small. The SMT data, while larger (64 bytes times the number of elements), can be discarded very quickly and does not need to be stored by anyone after senders calculate their (individually much shorter) Merkle Paths. Thus SMT data size can be discounted. At 200,000 elements per block, this is effectively 200,000 transactions per 1mB block. Currently, Bitcoin can only manage 3000 to 4000 max transactions per block of the same size. Thus for the same retained amount of data, my proposal, if correct, provides 50–70 times more capacity than Bitcoin today. Q: What about False Positives in Bloom Filters? A: Bloom Filters have a false positive probability. Thus at any time, an unspent transaction could appear spent, purely by chance, and effectively destroy coins. We can control this rate at the cost of scalability. If we use a false positive rate of p, we find that: Probability of Random Coin Decay = 1- (1–p) ^ N where N is the number of blocks. At p = 10^-9 (as I used in my example above with 200,000 transactions / block), and 10 minutes per block, we find that 1-(1–10**-9)**(144*365*100) = 0.00524 This means that we could achieve 200,000 transactions per 10 minutes and randomly lose 0.524% of coins every 100 years. If we choose p = 10^-12 we get 140,000 transactions per 1mB block and 0.000525% loss every 100 years. That seems like a good trade-off to me. Q: Doesn’t this impose a lot of computational burden on receivers? Aren’t the transfer proofs quite large? A: This scheme definitely shifts more burden to senders and receivers to construct and validate proofs from relatively sparse block data. I believe that the computational loads are manageable. Q: How solid is this formulation of the digital signature? Could there be another way? A: This part is not super solid and should be reviewed. I did not describe the details of deterministic signature construction, but this could probably done with modular arithmetic on large prime numbers. Q: Isn’t it tedious to supply / confirm / and check Q-1 digital signatures and bloom filters? A: Yes this part is tedious. It could probably be improved. However this is client-side computation which is much cheaper than global blockchain data. Q: Has this been vetted? A: No! Please help me out with constructive feedback and critical scrutiny. It’s possible I’ve missed something… I’m just not sure what it is. Q: Has this been thought of before? A: I’m not sure. A lot of these concepts have been around: SMT’s, thin clients, bloom filters. But I am not aware of a formulation like that above. In conclusion, I am proposing a new blockchain formulation that appears to offer dramatically improved scalability over the “global view” model employed by virtually all blockchain implementations. It links two critical data structures, SMT’s and Bloom Filters to prove both membership and non-membership. It also makes compromises related to coin decay and client-side computation in verification, that make improved data scalability possible. In essence, the heavy lifting is deferred to senders and receivers, utilizing a space-efficient ‘anchor’ in the blockchain for verification only. My proposal has not been scrutinized and I would be grateful for comments, feedback, and a careful review. Follow me at for more… @abarisser