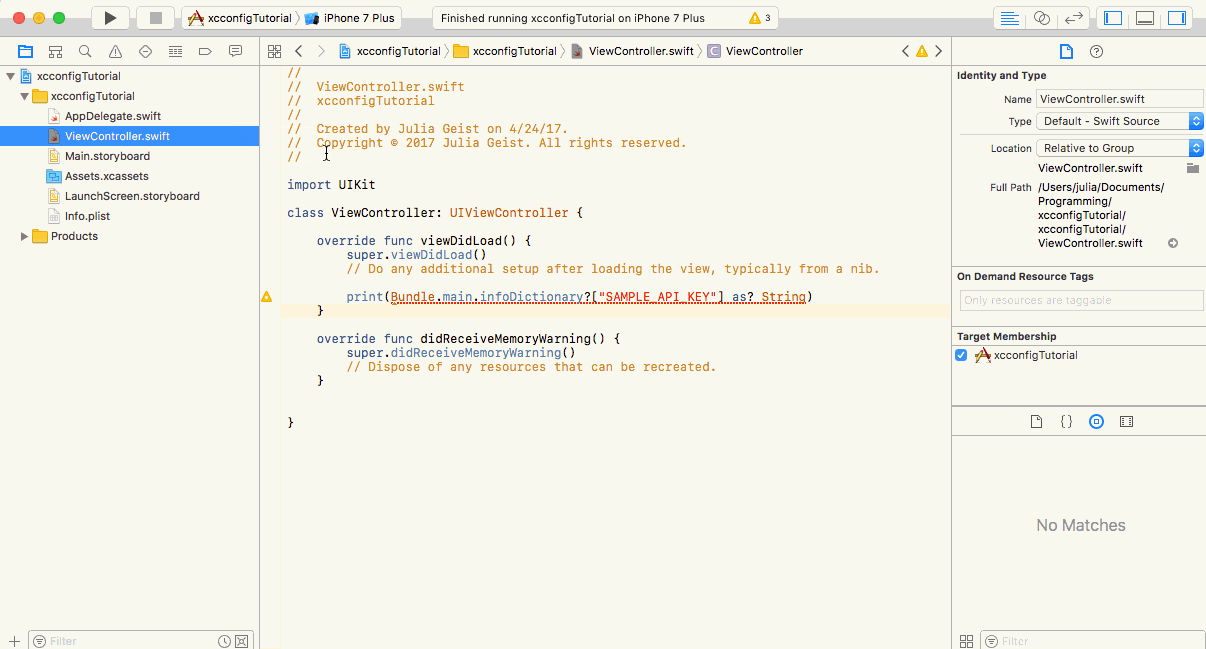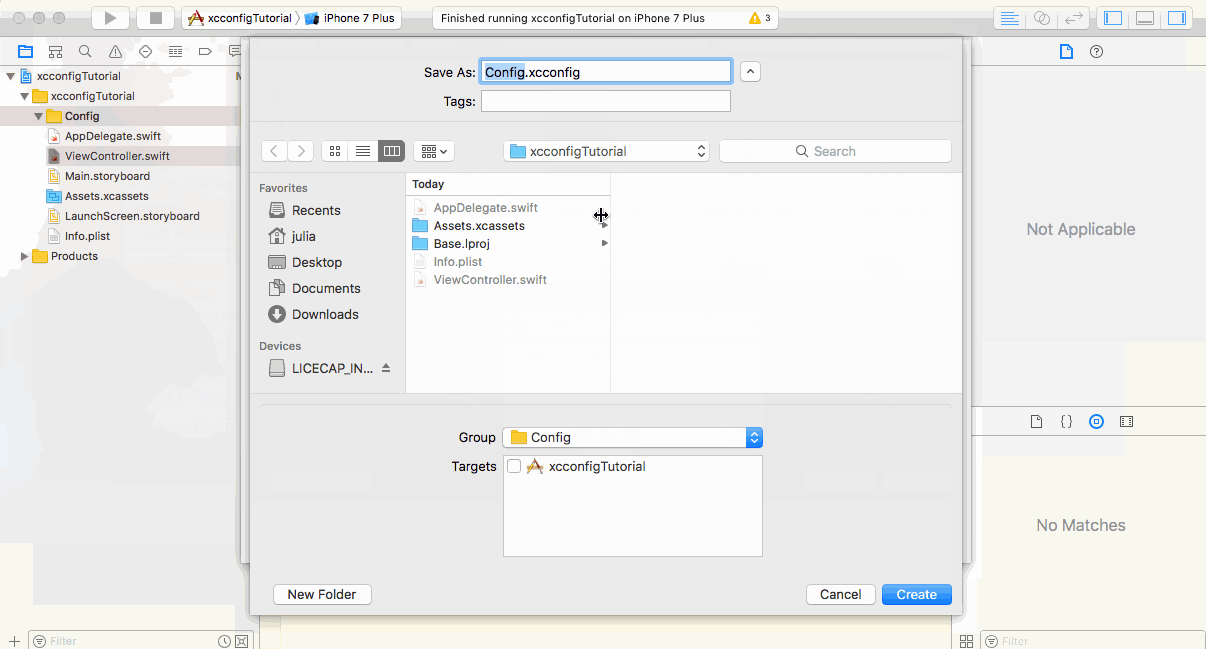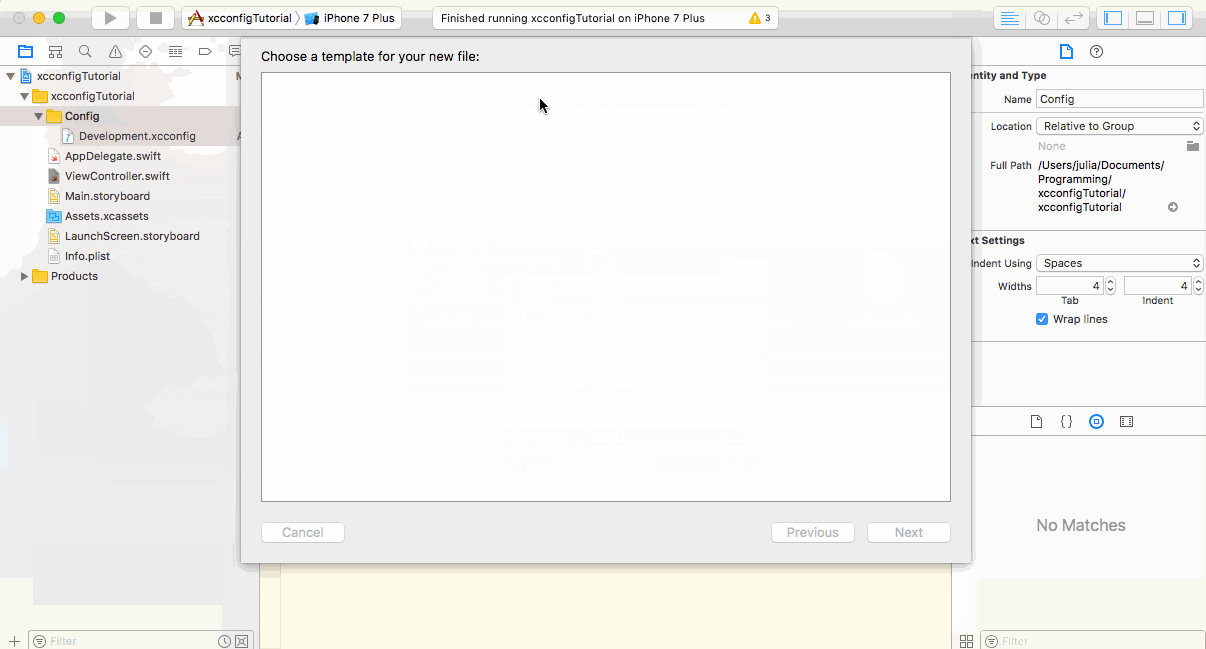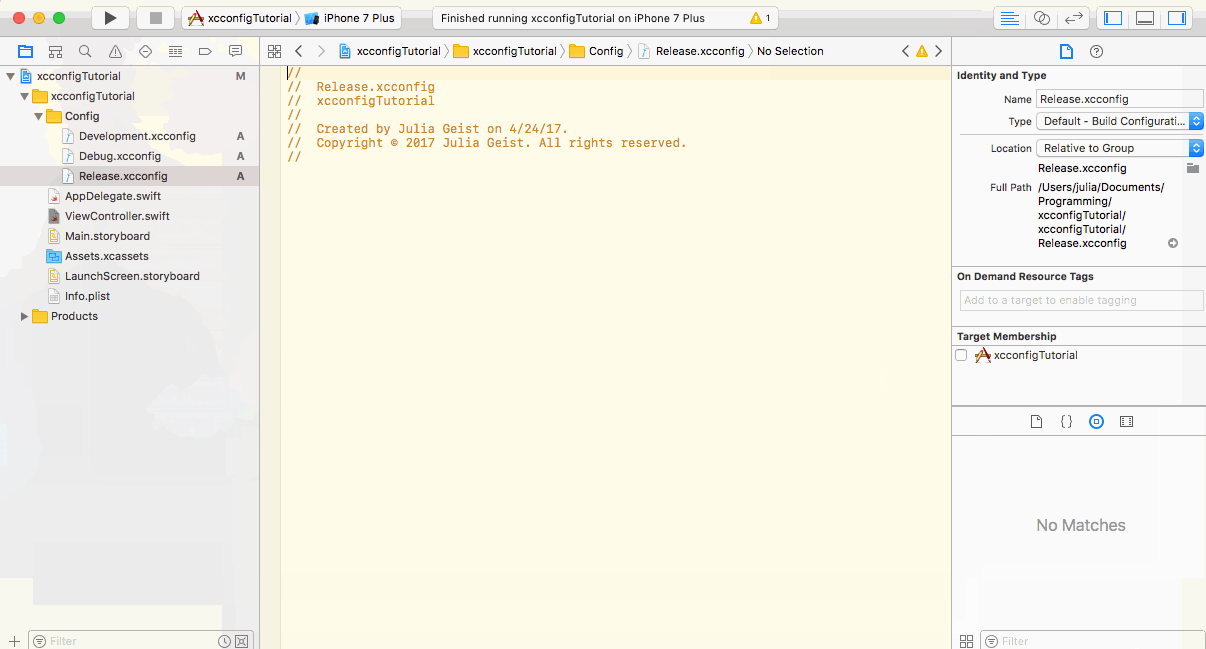
I’m not a native speaker. Sorry for my english. Please understand. When develop the server applications, you could encounter a problem for managing the configuration. Of course, This issue can be encountered in every place where configuration management is needed as well as server applications. If you are beginner or have no experience with configuration management, it could be little a bit hard to do. Especially, If you have secret values like Database Information, AWS Credentials, it may be very dangerous to manage the configuration on open VCS (Version Control System) such as Github, Bitbucket. In fact, in some cases, due to careless configuration management, web application could be hacked by other hackers or seized their server resources so a ton of price is billed unexpectedly. Therefore the configuration management, especially, the secret values management is a very important issue. In my case, I developed server applications mainly and managed the configurations in different ways for each project. So, I’d like to introduce the ways I used for help you who don’t know configuration management well. I used Python mainly when develop the server applications, so those ways I will introduce are worked in Python. Of course, these are the “ways” to manage the configuration, so you could use these ideas in other languages too. There are no any problems. In this post, I’ll introduce 4 ways of management as follows. (But, In here, I’ll do not talk about large scale management on infrastructure or distributed system levels. I’ll post it later) Using built-in data structure Using external configuration file Using environment variables Using dynamic loading Let’s explore it now! Using built-in data structure It is a very easy and intuitive way. As is the title, it is using the built-in data structure for managing the configuration, basically, it can be used as follow. Then, look at a little more complicated case. For example, If you are web developer, you may need different configurations for each development, testing, production environment, so, you can do as follow. It is easy and intuitive to use because you can import the configuration file directly from the same project and use the built-in data structure as it is. But, if you are using the VCS, your codebase will be exposed to world, so, there could be security issues if there are secret values. Therefore, you should use dummy data (non-real data) on VCS instead of real secret data for protecting you from external security attacks. And then you will replace the dummy data with real configuration values in production server by yourself, but, it would be cumbersome. There is a slightly more advanced way of using dynamic loading, which we’ll discuss later. So, I recommend this way if you have no secret values in configuration. Using external configuration file This way loads the configuration values defined in external file, not the built-in data structures. It is more general way because this way will treats the configuration as just configuration, not as a part of code. Let’s see the basic examples for using the ini and json formats as configuration. (Note that configparser is for Python 3.x, in Python 2.x, you should use ConfigParser instead) You can also use other formats such as xml, yaml. The basic approach is same, so, any formats are ok if there is a way for parsing that formats. In this approach, the configuration will be separated from code, so if you are using Git, just able to specify the file to ignore from VCS. However, when the configuration is completely separated from VCS, your co-worker may not able to use the configuration. So, you can use a following tip for solving this problem. Suppose the config.json has real configuration values. Then make an example configuration file with name which indicate it is an example like config.json.example. And you should manage the only config.json.example instead of config.json on VCS. This allows other developers to know the format and manipulate the configuration by themselves. Of course, they should rename that file name with config.json to use it as configuration correctly. Using environment variables This way does not use the files, instead system environment variables as configuration values. The configuration values are not managed as a separate file, so there is less risk of exposure of secret values, and it is so easy to use and can be used anywhere in codebase. But, of course, eventually, you may have to use shell script or other scripts for managing the every environment variables systematically. So, if you are familiar with system and scripting, this way is for you. However, if some environment which unable to use the environment variables like Apache, Nginx web server, you should use other ways. Using dynamic loading As mentioned above, this is a more advanced way than using built-in data structures one. Previous way should import the configuration .py file from specific file which need to use configuration, so, the config file must be located on import-able path. But, In this approach, the config file does not have to located on import-able path and can even be located on other repository. The principle is so simple. Just registers and loads the path of configuration .py file dynamically. That is, see following. Yes, It seems very similar to first way: using built-in data structures. But, the most advantage of it is that you can separate the configuration .py file from project itself. So, this way is proper when while taking the advantages of both first and second ways, and want to (or need to) separate the configuration .py file from project codebase. In my case, I used this way for managing the configuration repository and API server repository independently. The API server just use the configuration by import that file, but the real configuration values were managed on other repository. Then, when provisioning the servers, I’ve just cloned both repositories and make the API server able to use configuration dynamically. By doing this, you can manage the configuration while taking the advantages of first way and you can also minimize the security risk and manage the configuration easier. Also, especially, as the size of the configuration environment grows larger, it will be more easier and effective that maintain the configuration independently from project repository. Conclusion So far, we talked about 4 ways to manage the configuration. In fact, it depends on your applications. Of course, you can mix them and there may be better ways than these ways. And, when the system is on very large scale, it could be better to use third-party tools or services which provide the configuration management mainly. I hope this post will helps someone who have problems about configuration management. Hacker Noon is how hackers start their afternoons. We’re a part of the @AMIfamily. We are now accepting submissions and happy to discuss advertising & sponsorship opportunities. To learn more, read our about page, like/message us on Facebook, or simply, tweet/DM @HackerNoon. If you enjoyed this story, we recommend reading our latest tech stories and trending tech stories. Until next time, don’t take the realities of the world for granted! I’m not a native speaker. Sorry for my english. Please understand. I’m not a native speaker. Sorry for my english. Please understand. When develop the server applications, you could encounter a problem for managing the configuration. Of course, This issue can be encountered in every place where configuration management is needed as well as server applications. If you are beginner or have no experience with configuration management, it could be little a bit hard to do. Especially, If you have secret values like Database Information, AWS Credentials, it may be very dangerous to manage the configuration on open VCS (Version Control System) such as Github, Bitbucket. In fact, in some cases, due to careless configuration management, web application could be hacked by other hackers or seized their server resources so a ton of price is billed unexpectedly. Therefore the configuration management, especially, the secret values management is a very important issue. In my case, I developed server applications mainly and managed the configurations in different ways for each project. So, I’d like to introduce the ways I used for help you who don’t know configuration management well. I used Python mainly when develop the server applications, so those ways I will introduce are worked in Python. Of course, these are the “ways” to manage the configuration, so you could use these ideas in other languages too. There are no any problems. In this post, I’ll introduce 4 ways of management as follows. (But, In here, I’ll do not talk about large scale management on infrastructure or distributed system levels. I’ll post it later) Using built-in data structure Using external configuration file Using environment variables Using dynamic loading Using built-in data structure Using external configuration file Using environment variables Using dynamic loading Let’s explore it now! Using built-in data structure It is a very easy and intuitive way. As is the title, it is using the built-in data structure for managing the configuration, basically, it can be used as follow. Then, look at a little more complicated case. For example, If you are web developer, you may need different configurations for each development, testing, production environment, so, you can do as follow. It is easy and intuitive to use because you can import the configuration file directly from the same project and use the built-in data structure as it is. But, if you are using the VCS, your codebase will be exposed to world, so, there could be security issues if there are secret values. Therefore, you should use dummy data (non-real data) on VCS instead of real secret data for protecting you from external security attacks. And then you will replace the dummy data with real configuration values in production server by yourself, but, it would be cumbersome. There is a slightly more advanced way of using dynamic loading , which we’ll discuss later. using dynamic loading So, I recommend this way if you have no secret values in configuration. Using external configuration file Using external configuration file This way loads the configuration values defined in external file, not the built-in data structures. It is more general way because this way will treats the configuration as just configuration , not as a part of code. Let’s see the basic examples for using the ini and json formats as configuration. (Note that configparser is for Python 3.x, in Python 2.x, you should use ConfigParser instead) configuration ini json configparser ConfigParser You can also use other formats such as xml, yaml. The basic approach is same, so, any formats are ok if there is a way for parsing that formats. xml, yaml. In this approach, the configuration will be separated from code, so if you are using Git, just able to specify the file to ignore from VCS. However, when the configuration is completely separated from VCS, your co-worker may not able to use the configuration. So, you can use a following tip for solving this problem. Suppose the config.json has real configuration values. Then make an example configuration file with name which indicate it is an example like config.json.example. And you should manage the only config.json.example instead of config.json on VCS. This allows other developers to know the format and manipulate the configuration by themselves. Of course, they should rename that file name with config.json to use it as configuration correctly. config.json config.json.example. config.json.example config.json config.json Using environment variables This way does not use the files, instead system environment variables as configuration values. The configuration values are not managed as a separate file, so there is less risk of exposure of secret values, and it is so easy to use and can be used anywhere in codebase. But, of course, eventually, you may have to use shell script or other scripts for managing the every environment variables systematically. So, if you are familiar with system and scripting, this way is for you. However, if some environment which unable to use the environment variables like Apache, Nginx web server, you should use other ways. Using dynamic loading As mentioned above, this is a more advanced way than using built-in data structures one. Previous way should import the configuration .py file from specific file which need to use configuration, so, the config file must be located on import-able path. But, In this approach, the config file does not have to located on import-able path and can even be located on other repository. built-in data structures The principle is so simple. Just registers and loads the path of configuration .py file dynamically. That is, see following. Yes, It seems very similar to first way: using built-in data structures. But, the most advantage of it is that you can separate the configuration .py file from project itself. So, this way is proper when while taking the advantages of both first and second ways, and want to (or need to) separate the configuration .py file from project codebase. using built-in data structures. In my case, I used this way for managing the configuration repository and API server repository independently. The API server just use the configuration by import that file, but the real configuration values were managed on other repository. Then, when provisioning the servers, I’ve just cloned both repositories and make the API server able to use configuration dynamically. By doing this, you can manage the configuration while taking the advantages of first way and you can also minimize the security risk and manage the configuration easier. Also, especially, as the size of the configuration environment grows larger, it will be more easier and effective that maintain the configuration independently from project repository. Conclusion So far, we talked about 4 ways to manage the configuration. In fact, it depends on your applications. Of course, you can mix them and there may be better ways than these ways. And, when the system is on very large scale, it could be better to use third-party tools or services which provide the configuration management mainly. I hope this post will helps someone who have problems about configuration management. Hacker Noon is how hackers start their afternoons. We’re a part of the @AMIfamily. We are now accepting submissions and happy to discuss advertising & sponsorship opportunities. Hacker Noon is how hackers start their afternoons. We’re a part of the @AMI family. We are now accepting submissions and happy to discuss advertising & sponsorship opportunities. Hacker Noon @AMI accepting submissions discuss advertising & sponsorship To learn more, read our about page, like/message us on Facebook, or simply, tweet/DM @HackerNoon. To learn more, read our about page , like/message us on Facebook , or simply, tweet/DM @HackerNoon. read our about page like/message us on Facebook tweet/DM @HackerNoon. If you enjoyed this story, we recommend reading our latest tech stories and trending tech stories. Until next time, don’t take the realities of the world for granted! If you enjoyed this story, we recommend reading our latest tech stories and trending tech stories . Until next time, don’t take the realities of the world for granted! latest tech stories trending tech stories