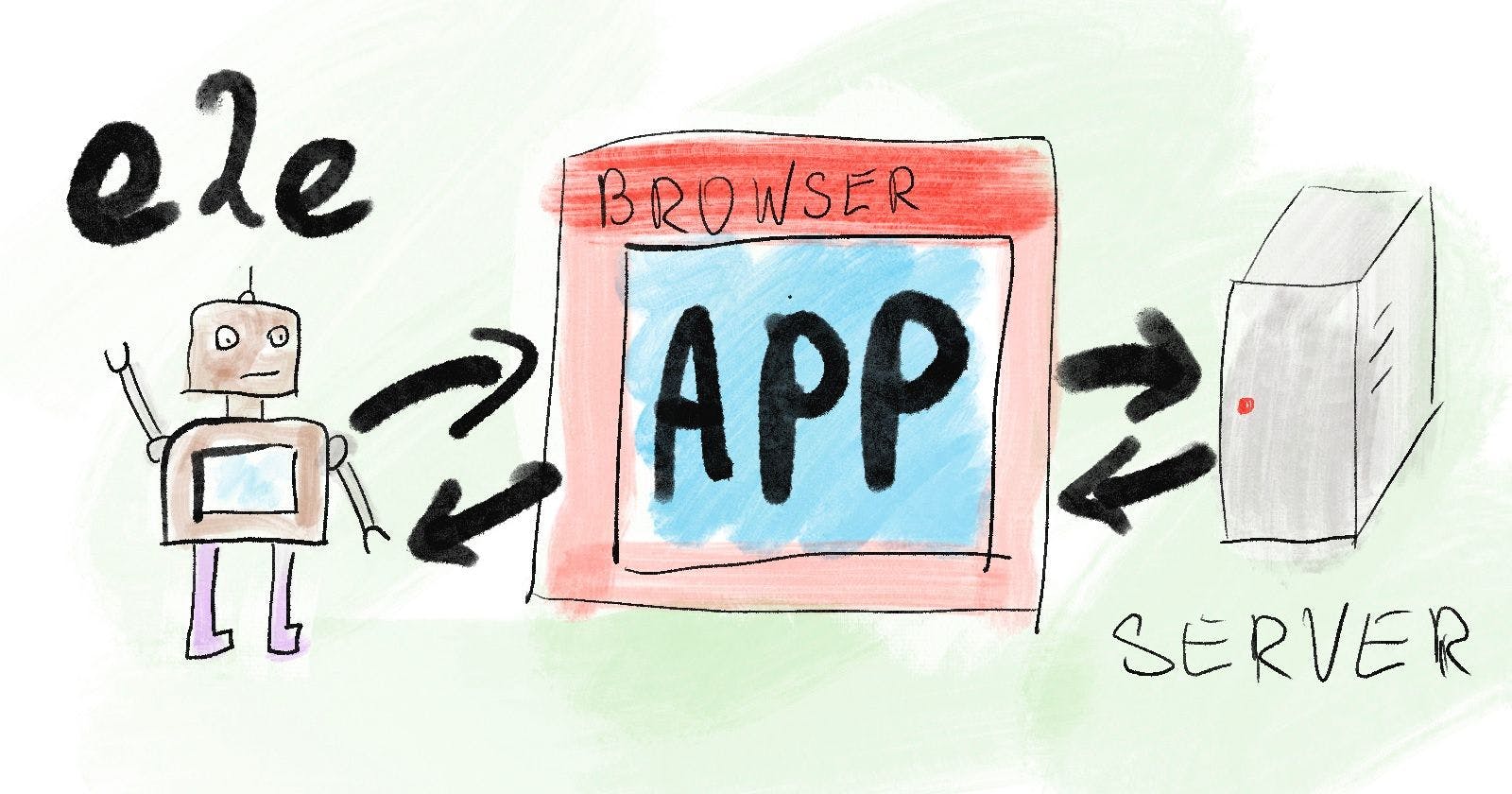
434 reads
What Fixing a Bug Looks Like
by byMarcin Wosinek@marcinwosinek
byMarcin Wosinek@marcinwosinek
I'm a JavaScript developer. I'm here to teach you useful skills, so you can succeed in your work & private projects.
May 15th, 2022






Audio Presented by
I'm a JavaScript developer. I'm here to teach you useful skills, so you can succeed in your work & private projects.


I'm a JavaScript developer. I'm here to teach you useful skills, so you can succeed in your work & private projects.
About Author

I'm a JavaScript developer. I'm here to teach you useful skills, so you can succeed in your work & private projects.
Comments