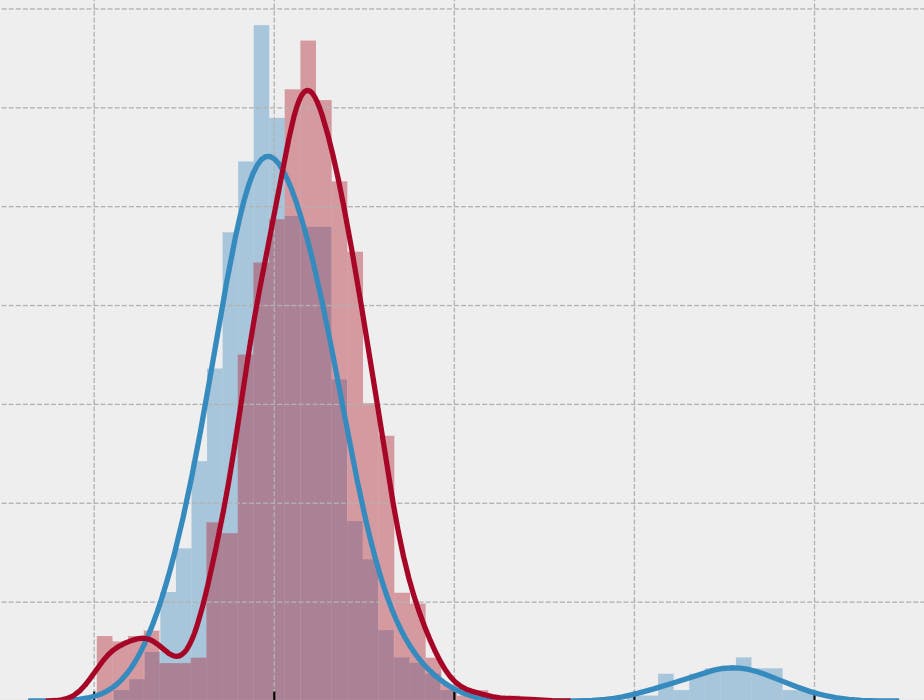
Any experiment involves a trade-off between fast results and metric sensitivity. If the chosen metric is wide in terms of variance, we must wait a long time to ensure the experiment's results are accurate. Let's consider one method to help analysts boost their experiments without losing too much time or metric sensitivity. Problem Formulation Suppose we conduct a standard experiment to test a new ranking algorithm, with session length as the primary metric. Additionally, consider that our audience can be roughly categorized into three groups: 1 million teenagers, 2 million users aged 18-45, and 3 million users aged 45 and above. The response to a new ranking algorithm would vary significantly among these audience groups. This wide variation reduces the sensitivity of the metric. In other words, the population can be divided into three strata, described in the following: Let's say that every component has a normal distribution. Then, the main metric for the population also has a normal distribution. Stratification method We randomly divide all users from the population in a classical experiment design without considering the differences between our users. Thus, we consider the sample with the following expected value and variance. Another way is randomly dividing inside every strat according to the weight of the strat in the general population. In this case, the expected value and variance are the following. The expected value is the same as in the first selection. However, the variance is less, which guarantees higher metric sensitivity. Now, let's consider Neyman's method. They suggest dividing users randomly inside every strat with specific weights. So, the expected value and variance are equal to the following in this case. The expected value is equal to the expected value in the first case asymptotically. However, the variance is much less. Empirical Testing We've proved the efficiency of this method theoretically. Let's simulate samples and test the stratification method empirically. Let's consider three cases: all strats with equal means and variances, all strats with different means and equal variances, all strats with equal means and different variances. We will apply all three methods in all cases and plot a histogram and boxplot to compare them. Code preparation First, let’s create a class in Python that simulates our general population consisting of three strats. class GeneralPopulation: def __init__(self, means: [float], stds: [float], sizes: [int], random_state: int = 15 ): """ Initializes our General Population and saves the given distributions :param means: List of expectations for normal distributions :param stds: List of standard deviations for normal distributions :param sizes: How many objects will be in each strata :param random_state: Parameter fixing randomness. Needed so that when conducting experiment repeatedly with the same input parameters, the results remained the same """ self.strats = [st.norm(mean, std) for mean, std in zip(means, stds)] self._sample(sizes) self.random_state = random_state def _sample(self, sizes): """Creates a general population sample as a mixture of strata :param sizes: List with sample sizes of the corresponding normal distributions """ self.strats_samples = [rv.rvs(size) for rv, size in zip(self.strats, sizes)] self.general_samples = np.hstack(self.strats_samples) self.N = self.general_samples.shape[0] # number of strata self.count_strats = len(sizes) # ratios for every strata in GP self.ws = [size/self.N for size in sizes] # ME and Std for GP self.m = np.mean(self.general_samples) self.sigma = np.std(self.general_samples) # ME and std for all strata self.ms = [np.mean(strat_sample) for strat_sample in self.strats_samples] self.sigmas = [np.std(strat_sample) for strat_sample in self.strats_samples] Then, let’s add functions for the three sampling methods described in the theoretical part. def random_subsampling(self, size): """Creates a random subset of the entire population :param sizes: subsample size """ rc = np.random.choice(self.general_samples, size=size) return rc def proportional_subsampling(self, size): """Creates a subsample with the number of elements, proportional shares of strata :param sizes: subsample size """ self.strats_size_proport = [int(np.floor(size*w)) for w in self.ws] rc = [] for k in range(len(self.strats_size_proport)): rc.append(np.random.choice(self.strats_samples[k], size=self.strats_size_proport[k])) return rc def optimal_subsampling(self, size): """Creates a subsample with the optimal number of elements relative to strata :param sizes: subsample size """ sum_denom = 0 for k in range(self.count_strats): sum_denom += self.ws[k] * self.sigmas[k] self.strats_size_optimal = [int(np.floor((size*w*sigma)/sum_denom)) for w, sigma in zip(self.ws, self.sigmas)] if 0 in self.strats_size_optimal: raise ValueError('Strats size is 0, please change variance of smallest strat!') rc = [] for k in range(len(self.strats_size_optimal)): rc.append(np.random.choice(self.strats_samples[k], size=self.strats_size_optimal[k])) return rc Also, for the empirical part, we always need a function for simulating the experiment process. def run_experiments(self, n_sub, subsampling_method, n_experiments=1000): """Conducts a series of experiments and saves the results :param n_sub: size of sample :param subsampling_method: method for creating a subsample :param n_experiments: number of experiment starts """ means_s = [] if(len(self.general_samples)<100): n_sub = 20 if(subsampling_method == 'random_subsampling'): for n in range(n_experiments): rc = self.random_subsampling(n_sub) mean = rc.sum()/len(rc) means_s.append(mean) else: for n in range(n_experiments): if(subsampling_method == 'proportional_subsampling'): rc = self.proportional_subsampling(n_sub) elif(subsampling_method == 'optimal_subsampling'): rc = self.optimal_subsampling(n_sub) strats_mean = [] for k in range(len(rc)): strats_mean.append(sum(rc[k])/len(rc[k])) # Mean for a mixture means_s.append(sum([w_k*mean_k for w_k, mean_k in zip(self.ws, strats_mean)])) return means_s Simulation results If we look at the general population, where all our strats have the same values and variances, the results of all three methods are expected to be more or less equal. Different means and equal variances obtained more exciting results. Using stratification dramatically reduces variance. In cases with equal means and different variances, we see a variance reduction in Neyman's method. Conclusion Now, you can apply the stratification method to reduce the metric variance and boost the experiment if you cluster your audience and technically divide them randomly inside each cluster with specific weights! Any experiment involves a trade-off between fast results and metric sensitivity. If the chosen metric is wide in terms of variance, we must wait a long time to ensure the experiment's results are accurate. Let's consider one method to help analysts boost their experiments without losing too much time or metric sensitivity. Problem Formulation Suppose we conduct a standard experiment to test a new ranking algorithm, with session length as the primary metric. Additionally, consider that our audience can be roughly categorized into three groups: 1 million teenagers, 2 million users aged 18-45, and 3 million users aged 45 and above. The response to a new ranking algorithm would vary significantly among these audience groups. This wide variation reduces the sensitivity of the metric. In other words, the population can be divided into three strata, described in the following: Let's say that every component has a normal distribution. Then, the main metric for the population also has a normal distribution. Stratification method Stratification method We randomly divide all users from the population in a classical experiment design without considering the differences between our users. Thus, we consider the sample with the following expected value and variance. randomly divide all users Another way is randomly dividing inside every strat according to the weight of the strat in the general population. randomly dividing inside every strat according to the weight In this case, the expected value and variance are the following. The expected value is the same as in the first selection. However, the variance is less, which guarantees higher metric sensitivity. Now, let's consider Neyman's method . They suggest dividing users randomly inside every strat with specific weights. Neyman's method So, the expected value and variance are equal to the following in this case. The expected value is equal to the expected value in the first case asymptotically. However, the variance is much less. Empirical Testing Empirical Testing We've proved the efficiency of this method theoretically. Let's simulate samples and test the stratification method empirically. Let's consider three cases: all strats with equal means and variances, all strats with different means and equal variances, all strats with equal means and different variances. all strats with equal means and variances, all strats with different means and equal variances, all strats with equal means and different variances. We will apply all three methods in all cases and plot a histogram and boxplot to compare them. Code preparation First, let’s create a class in Python that simulates our general population consisting of three strats. class GeneralPopulation: def __init__(self, means: [float], stds: [float], sizes: [int], random_state: int = 15 ): """ Initializes our General Population and saves the given distributions :param means: List of expectations for normal distributions :param stds: List of standard deviations for normal distributions :param sizes: How many objects will be in each strata :param random_state: Parameter fixing randomness. Needed so that when conducting experiment repeatedly with the same input parameters, the results remained the same """ self.strats = [st.norm(mean, std) for mean, std in zip(means, stds)] self._sample(sizes) self.random_state = random_state def _sample(self, sizes): """Creates a general population sample as a mixture of strata :param sizes: List with sample sizes of the corresponding normal distributions """ self.strats_samples = [rv.rvs(size) for rv, size in zip(self.strats, sizes)] self.general_samples = np.hstack(self.strats_samples) self.N = self.general_samples.shape[0] # number of strata self.count_strats = len(sizes) # ratios for every strata in GP self.ws = [size/self.N for size in sizes] # ME and Std for GP self.m = np.mean(self.general_samples) self.sigma = np.std(self.general_samples) # ME and std for all strata self.ms = [np.mean(strat_sample) for strat_sample in self.strats_samples] self.sigmas = [np.std(strat_sample) for strat_sample in self.strats_samples] class GeneralPopulation: def __init__(self, means: [float], stds: [float], sizes: [int], random_state: int = 15 ): """ Initializes our General Population and saves the given distributions :param means: List of expectations for normal distributions :param stds: List of standard deviations for normal distributions :param sizes: How many objects will be in each strata :param random_state: Parameter fixing randomness. Needed so that when conducting experiment repeatedly with the same input parameters, the results remained the same """ self.strats = [st.norm(mean, std) for mean, std in zip(means, stds)] self._sample(sizes) self.random_state = random_state def _sample(self, sizes): """Creates a general population sample as a mixture of strata :param sizes: List with sample sizes of the corresponding normal distributions """ self.strats_samples = [rv.rvs(size) for rv, size in zip(self.strats, sizes)] self.general_samples = np.hstack(self.strats_samples) self.N = self.general_samples.shape[0] # number of strata self.count_strats = len(sizes) # ratios for every strata in GP self.ws = [size/self.N for size in sizes] # ME and Std for GP self.m = np.mean(self.general_samples) self.sigma = np.std(self.general_samples) # ME and std for all strata self.ms = [np.mean(strat_sample) for strat_sample in self.strats_samples] self.sigmas = [np.std(strat_sample) for strat_sample in self.strats_samples] Then, let’s add functions for the three sampling methods described in the theoretical part. def random_subsampling(self, size): """Creates a random subset of the entire population :param sizes: subsample size """ rc = np.random.choice(self.general_samples, size=size) return rc def proportional_subsampling(self, size): """Creates a subsample with the number of elements, proportional shares of strata :param sizes: subsample size """ self.strats_size_proport = [int(np.floor(size*w)) for w in self.ws] rc = [] for k in range(len(self.strats_size_proport)): rc.append(np.random.choice(self.strats_samples[k], size=self.strats_size_proport[k])) return rc def optimal_subsampling(self, size): """Creates a subsample with the optimal number of elements relative to strata :param sizes: subsample size """ sum_denom = 0 for k in range(self.count_strats): sum_denom += self.ws[k] * self.sigmas[k] self.strats_size_optimal = [int(np.floor((size*w*sigma)/sum_denom)) for w, sigma in zip(self.ws, self.sigmas)] if 0 in self.strats_size_optimal: raise ValueError('Strats size is 0, please change variance of smallest strat!') rc = [] for k in range(len(self.strats_size_optimal)): rc.append(np.random.choice(self.strats_samples[k], size=self.strats_size_optimal[k])) return rc def random_subsampling(self, size): """Creates a random subset of the entire population :param sizes: subsample size """ rc = np.random.choice(self.general_samples, size=size) return rc def proportional_subsampling(self, size): """Creates a subsample with the number of elements, proportional shares of strata :param sizes: subsample size """ self.strats_size_proport = [int(np.floor(size*w)) for w in self.ws] rc = [] for k in range(len(self.strats_size_proport)): rc.append(np.random.choice(self.strats_samples[k], size=self.strats_size_proport[k])) return rc def optimal_subsampling(self, size): """Creates a subsample with the optimal number of elements relative to strata :param sizes: subsample size """ sum_denom = 0 for k in range(self.count_strats): sum_denom += self.ws[k] * self.sigmas[k] self.strats_size_optimal = [int(np.floor((size*w*sigma)/sum_denom)) for w, sigma in zip(self.ws, self.sigmas)] if 0 in self.strats_size_optimal: raise ValueError('Strats size is 0, please change variance of smallest strat!') rc = [] for k in range(len(self.strats_size_optimal)): rc.append(np.random.choice(self.strats_samples[k], size=self.strats_size_optimal[k])) return rc Also, for the empirical part, we always need a function for simulating the experiment process. def run_experiments(self, n_sub, subsampling_method, n_experiments=1000): """Conducts a series of experiments and saves the results :param n_sub: size of sample :param subsampling_method: method for creating a subsample :param n_experiments: number of experiment starts """ means_s = [] if(len(self.general_samples)<100): n_sub = 20 if(subsampling_method == 'random_subsampling'): for n in range(n_experiments): rc = self.random_subsampling(n_sub) mean = rc.sum()/len(rc) means_s.append(mean) else: for n in range(n_experiments): if(subsampling_method == 'proportional_subsampling'): rc = self.proportional_subsampling(n_sub) elif(subsampling_method == 'optimal_subsampling'): rc = self.optimal_subsampling(n_sub) strats_mean = [] for k in range(len(rc)): strats_mean.append(sum(rc[k])/len(rc[k])) # Mean for a mixture means_s.append(sum([w_k*mean_k for w_k, mean_k in zip(self.ws, strats_mean)])) return means_s def run_experiments(self, n_sub, subsampling_method, n_experiments=1000): """Conducts a series of experiments and saves the results :param n_sub: size of sample :param subsampling_method: method for creating a subsample :param n_experiments: number of experiment starts """ means_s = [] if(len(self.general_samples)<100): n_sub = 20 if(subsampling_method == 'random_subsampling'): for n in range(n_experiments): rc = self.random_subsampling(n_sub) mean = rc.sum()/len(rc) means_s.append(mean) else: for n in range(n_experiments): if(subsampling_method == 'proportional_subsampling'): rc = self.proportional_subsampling(n_sub) elif(subsampling_method == 'optimal_subsampling'): rc = self.optimal_subsampling(n_sub) strats_mean = [] for k in range(len(rc)): strats_mean.append(sum(rc[k])/len(rc[k])) # Mean for a mixture means_s.append(sum([w_k*mean_k for w_k, mean_k in zip(self.ws, strats_mean)])) return means_s Simulation results If we look at the general population, where all our strats have the same values and variances, the results of all three methods are expected to be more or less equal. Different means and equal variances obtained more exciting results. Using stratification dramatically reduces variance. In cases with equal means and different variances, we see a variance reduction in Neyman's method. Conclusion Conclusion Now, you can apply the stratification method to reduce the metric variance and boost the experiment if you cluster your audience and technically divide them randomly inside each cluster with specific weights!