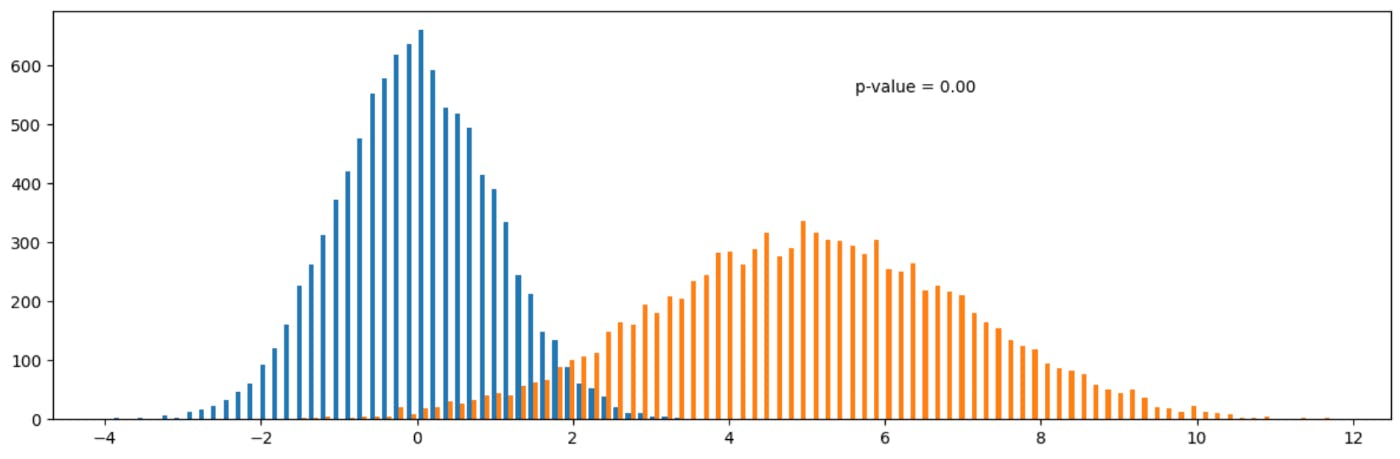
Today, nearly all companies in the IT industry use AB testing to evaluate the value of a feature. They test all changes in applications and websites, allowing someone to determine which feature is the winner every day. As a result, numerous discussions revolve around experiments and AB tests, with a common misconception being the prohibition of applying t-tests for abnormal distributions. Let's delve into this topic and find the correct answer! Problem Formulation Let’s look at a familiar example Imagine a common experiment with different paywalls that suggest a purchase to a customer. We have two variants that show two different and independent groups of users. The decision will be made by a conversion rate to purchase. Every user was assigned to a control or test group randomly, so both samples are independent. Also, every user is assigned 1 or 0 meaning they either made a purchase or not. Thus, our samples have a bi-nominal distribution. In this case, the conversion rate to purchase equals the sample mean. So, we will compare p1n1 and p2n2. Is it possible to use a t-test here or not? Let’s generalize the problem We’re still considering the two independent distributed samples X1 and X2. We know that they have abnormal distributions with finite expected values μ1 and μ2 and finite variances σ1 and σ2. Now, we want to check a hypothesis about the equality of means: Theoretical Proof Let’s consider the Welch’s t-test in a case of different variances. When the variances of both samples are the same, then the Student’s and Welch’s t-tests have similar results. Thus, let’s consider a statistic: Can it be compared with critical values of Student’s distribution? By the central limit theorem, if n1,2 → ∞ Therefore, Also, per Slutsky’s theorem, this convergence in probability is the convergence in distribution. Thus, the constructed statistic t ∼ N(μ1 −μ2,1). Under the null hypothesis t ∼ N(0,1), which is asymptotically equivalent to the Student’s distribution. Empirical Proof Finally, we proved that a t-test can estimate the experiment with two variants of paywall. Also, it is worth mentioning that only two conditions were used for that example: n→∞ and finite of moments for distribution of random value. Let’s try to simulate a pair of distributions to check the prohibition to apply a t-test for them! Bernoulli data Bernoulli data is a widely used case for the experimentation process. A metric like CTR, any type of conversion rate, retention rate, etc., is often chosen as a target metric in an experiment. First, let’s simulate two samples of the Bernoulli distribution with the same parameters. After that, we started increasing the parameter for the second sample. For all samples, we calculated the p-value using Student’s t-test. We see that the p-value drops to zero almost immediately. import numpy as np from scipy import stats import matplotlib.pyplot as plt p_diff_list = [] p_value_list = [] N = 10000 p_1 = 0.01 p_2 = p_1 while p_2 <= 1: p_diff_list.append(p_2-p_1) x_1 = np.random.binomial(1, p_1, N) x_2 = np.random.binomial(1, p_2, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_list.append(p_value) p_2 += 0.01 fig, ax = plt.subplots(figsize=(10,4)) ax.plot(p_diff_list, p_value_list) ax.set(xlabel='p_2 - p_1', ylabel='p-value', title='p-value changes for different Bernoulli distributions') fig.tight_layout() plt.show() Now, let’s simulate 100,000 times two samples with the same parameters and 100,000 times two samples with different parameters. After that, we can check the first and second-type errors. Indeed, the t-test is a powerful criterion for metrics with parameters like in our simulations—the first type error is around 5%, and the power is around 90%! import numpy as np from scipy import stats import matplotlib.pyplot as plt n_attempts = 100000 N = 10000 # False Negative calculation p_value_eq_list = [] p = 0.01 i = 1 while i <= n_attempts: x_1 = np.random.binomial(1, p, N) x_2 = np.random.binomial(1, p, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_eq_list.append(p_value) i += 1 False_Negative = sum([i < 0.05 for i in p_value_eq_list])/len(p_value_eq_list) # False Positive calculation p_value_noneq_list = [] p_1 = 0.01 p_2 = 0.015 i = 1 while i <= n_attempts: x_1 = np.random.binomial(1, p_1, N) x_2 = np.random.binomial(1, p_2, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_noneq_list.append(p_value) i += 1 False_Positive = 1 - sum([i < 0.05 for i in p_value_noneq_list])/len(p_value_noneq_list) Exponential data Now, let’s consider the exponential data prevalent in the real world, too. Two cases of exponential sample comparisons are shown below. In the first case, samples with the same parameters are considered. The p-value corresponds to reality; it says that samples are similar. In the right part, there is a case with two samples with different parameters and a p-value lower than 0.05. import numpy as np from scipy import stats import matplotlib.pyplot as plt # Generate similar samples N = 10000 beta = 3 xs_1 = np.random.exponential(beta, N) xs_2 = np.random.exponential(beta, N) _, p_value_s = stats.ttest_ind(xs_1, xs_2, equal_var=False) # Generate different samples N = 10000 beta_1 = 3 beta_2 = 10 xd_1 = np.random.exponential(beta_1, N) xd_2 = np.random.exponential(beta_2, N) _, p_value_d = stats.ttest_ind(xd_1, xd_2, equal_var=False) n_bins = 100 fig, axs = plt.subplots(1, 2, figsize=(12,4)) axs[0].hist([xs_1, xs_2], n_bins, histtype='bar') axs[0].set_title('Exponential similar samples') axs[0].annotate(f'p-value = {p_value_s:.2f}', xy=(.6, .8), xycoords=axs[0].transAxes) axs[1].hist([xd_1, xd_2], n_bins, histtype='bar') axs[1].set_title('Exponential different samples') axs[1].annotate(f'p-value = {p_value_d:.2f}', xy=(1.8, .8), xycoords=axs[0].transAxes) fig.tight_layout() plt.show() Now, we do the same calculations as with Bernoulli data for evaluating the first and second-type errors. The results are the same—the criteria are very powerful. import numpy as np from scipy import stats import matplotlib.pyplot as plt n_attempts = 100000 N = 10000 # False Negative calculation p_value_eq_list = [] beta = 1 i = 1 while i <= n_attempts: x_1 = np.random.exponential(beta, N) x_2 = np.random.exponential(beta, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_eq_list.append(p_value) i += 1 False_Negative = sum([i < 0.05 for i in p_value_eq_list])/len(p_value_eq_list) # False Positive calculation p_value_noneq_list = [] beta_1 = 1 beta_2 = 1.05 i = 1 while i <= n_attempts: x_1 = np.random.exponential(beta_1, N) x_2 = np.random.exponential(beta_2, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_noneq_list.append(p_value) i += 1 False_Positive = 1 - sum([i < 0.05 for i in p_value_noneq_list])/len(p_value_noneq_list) Conclusion Now we know the answer to the question about a prohibition on applying a t-test for abnormal distribution—yes, we can apply it to most distributions! Today, nearly all companies in the IT industry use AB testing to evaluate the value of a feature. They test all changes in applications and websites, allowing someone to determine which feature is the winner every day. As a result, numerous discussions revolve around experiments and AB tests, with a common misconception being the prohibition of applying t-tests for abnormal distributions. Let's delve into this topic and find the correct answer! Problem Formulation Let’s look at a familiar example Imagine a common experiment with different paywalls that suggest a purchase to a customer. We have two variants that show two different and independent groups of users. The decision will be made by a conversion rate to purchase. Every user was assigned to a control or test group randomly, so both samples are independent. Also, every user is assigned 1 or 0 meaning they either made a purchase or not. Thus, our samples have a bi-nominal distribution. In this case, the conversion rate to purchase equals the sample mean. So, we will compare p1n1 and p2n2. Is it possible to use a t-test here or not? Is it possible to use a t-test here or not? Let’s generalize the problem We’re still considering the two independent distributed samples X1 and X2. We know that they have abnormal distributions with finite expected values μ1 and μ2 and finite variances σ1 and σ2. Now, we want to check a hypothesis about the equality of means: Theoretical Proof Let’s consider the Welch’s t-test in a case of different variances. When the variances of both samples are the same, then the Student’s and Welch’s t-tests have similar results. Thus, let’s consider a statistic: Can it be compared with critical values of Student’s distribution? By the central limit theorem, if n1,2 → ∞ Therefore, Also, per Slutsky’s theorem, this convergence in probability is the convergence in distribution. Thus, the constructed statistic t ∼ N(μ1 −μ2,1). Under the null hypothesis t ∼ N(0,1), which is asymptotically equivalent to the Student’s distribution. Empirical Proof Finally, we proved that a t-test can estimate the experiment with two variants of paywall. Also, it is worth mentioning that only two conditions were used for that example: n→∞ and finite of moments for distribution of random value. n→∞ and finite of moments for distribution of random value. Let’s try to simulate a pair of distributions to check the prohibition to apply a t-test for them! Bernoulli data Bernoulli data is a widely used case for the experimentation process. A metric like CTR, any type of conversion rate, retention rate, etc., is often chosen as a target metric in an experiment. First, let’s simulate two samples of the Bernoulli distribution with the same parameters. After that, we started increasing the parameter for the second sample. For all samples, we calculated the p-value using Student’s t-test. We see that the p-value drops to zero almost immediately. import numpy as np from scipy import stats import matplotlib.pyplot as plt p_diff_list = [] p_value_list = [] N = 10000 p_1 = 0.01 p_2 = p_1 while p_2 <= 1: p_diff_list.append(p_2-p_1) x_1 = np.random.binomial(1, p_1, N) x_2 = np.random.binomial(1, p_2, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_list.append(p_value) p_2 += 0.01 fig, ax = plt.subplots(figsize=(10,4)) ax.plot(p_diff_list, p_value_list) ax.set(xlabel='p_2 - p_1', ylabel='p-value', title='p-value changes for different Bernoulli distributions') fig.tight_layout() plt.show() import numpy as np from scipy import stats import matplotlib.pyplot as plt p_diff_list = [] p_value_list = [] N = 10000 p_1 = 0.01 p_2 = p_1 while p_2 <= 1: p_diff_list.append(p_2-p_1) x_1 = np.random.binomial(1, p_1, N) x_2 = np.random.binomial(1, p_2, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_list.append(p_value) p_2 += 0.01 fig, ax = plt.subplots(figsize=(10,4)) ax.plot(p_diff_list, p_value_list) ax.set(xlabel='p_2 - p_1', ylabel='p-value', title='p-value changes for different Bernoulli distributions') fig.tight_layout() plt.show() Now, let’s simulate 100,000 times two samples with the same parameters and 100,000 times two samples with different parameters. After that, we can check the first and second-type errors. Indeed, the t-test is a powerful criterion for metrics with parameters like in our simulations—the first type error is around 5%, and the power is around 90%! import numpy as np from scipy import stats import matplotlib.pyplot as plt n_attempts = 100000 N = 10000 # False Negative calculation p_value_eq_list = [] p = 0.01 i = 1 while i <= n_attempts: x_1 = np.random.binomial(1, p, N) x_2 = np.random.binomial(1, p, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_eq_list.append(p_value) i += 1 False_Negative = sum([i < 0.05 for i in p_value_eq_list])/len(p_value_eq_list) # False Positive calculation p_value_noneq_list = [] p_1 = 0.01 p_2 = 0.015 i = 1 while i <= n_attempts: x_1 = np.random.binomial(1, p_1, N) x_2 = np.random.binomial(1, p_2, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_noneq_list.append(p_value) i += 1 False_Positive = 1 - sum([i < 0.05 for i in p_value_noneq_list])/len(p_value_noneq_list) import numpy as np from scipy import stats import matplotlib.pyplot as plt n_attempts = 100000 N = 10000 # False Negative calculation p_value_eq_list = [] p = 0.01 i = 1 while i <= n_attempts: x_1 = np.random.binomial(1, p, N) x_2 = np.random.binomial(1, p, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_eq_list.append(p_value) i += 1 False_Negative = sum([i < 0.05 for i in p_value_eq_list])/len(p_value_eq_list) # False Positive calculation p_value_noneq_list = [] p_1 = 0.01 p_2 = 0.015 i = 1 while i <= n_attempts: x_1 = np.random.binomial(1, p_1, N) x_2 = np.random.binomial(1, p_2, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_noneq_list.append(p_value) i += 1 False_Positive = 1 - sum([i < 0.05 for i in p_value_noneq_list])/len(p_value_noneq_list) Exponential data Now, let’s consider the exponential data prevalent in the real world, too. Two cases of exponential sample comparisons are shown below. In the first case, samples with the same parameters are considered. The p-value corresponds to reality; it says that samples are similar. In the right part, there is a case with two samples with different parameters and a p-value lower than 0.05. import numpy as np from scipy import stats import matplotlib.pyplot as plt # Generate similar samples N = 10000 beta = 3 xs_1 = np.random.exponential(beta, N) xs_2 = np.random.exponential(beta, N) _, p_value_s = stats.ttest_ind(xs_1, xs_2, equal_var=False) # Generate different samples N = 10000 beta_1 = 3 beta_2 = 10 xd_1 = np.random.exponential(beta_1, N) xd_2 = np.random.exponential(beta_2, N) _, p_value_d = stats.ttest_ind(xd_1, xd_2, equal_var=False) n_bins = 100 fig, axs = plt.subplots(1, 2, figsize=(12,4)) axs[0].hist([xs_1, xs_2], n_bins, histtype='bar') axs[0].set_title('Exponential similar samples') axs[0].annotate(f'p-value = {p_value_s:.2f}', xy=(.6, .8), xycoords=axs[0].transAxes) axs[1].hist([xd_1, xd_2], n_bins, histtype='bar') axs[1].set_title('Exponential different samples') axs[1].annotate(f'p-value = {p_value_d:.2f}', xy=(1.8, .8), xycoords=axs[0].transAxes) fig.tight_layout() plt.show() import numpy as np from scipy import stats import matplotlib.pyplot as plt # Generate similar samples N = 10000 beta = 3 xs_1 = np.random.exponential(beta, N) xs_2 = np.random.exponential(beta, N) _, p_value_s = stats.ttest_ind(xs_1, xs_2, equal_var=False) # Generate different samples N = 10000 beta_1 = 3 beta_2 = 10 xd_1 = np.random.exponential(beta_1, N) xd_2 = np.random.exponential(beta_2, N) _, p_value_d = stats.ttest_ind(xd_1, xd_2, equal_var=False) n_bins = 100 fig, axs = plt.subplots(1, 2, figsize=(12,4)) axs[0].hist([xs_1, xs_2], n_bins, histtype='bar') axs[0].set_title('Exponential similar samples') axs[0].annotate(f'p-value = {p_value_s:.2f}', xy=(.6, .8), xycoords=axs[0].transAxes) axs[1].hist([xd_1, xd_2], n_bins, histtype='bar') axs[1].set_title('Exponential different samples') axs[1].annotate(f'p-value = {p_value_d:.2f}', xy=(1.8, .8), xycoords=axs[0].transAxes) fig.tight_layout() plt.show() Now, we do the same calculations as with Bernoulli data for evaluating the first and second-type errors. The results are the same—the criteria are very powerful. import numpy as np from scipy import stats import matplotlib.pyplot as plt n_attempts = 100000 N = 10000 # False Negative calculation p_value_eq_list = [] beta = 1 i = 1 while i <= n_attempts: x_1 = np.random.exponential(beta, N) x_2 = np.random.exponential(beta, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_eq_list.append(p_value) i += 1 False_Negative = sum([i < 0.05 for i in p_value_eq_list])/len(p_value_eq_list) # False Positive calculation p_value_noneq_list = [] beta_1 = 1 beta_2 = 1.05 i = 1 while i <= n_attempts: x_1 = np.random.exponential(beta_1, N) x_2 = np.random.exponential(beta_2, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_noneq_list.append(p_value) i += 1 False_Positive = 1 - sum([i < 0.05 for i in p_value_noneq_list])/len(p_value_noneq_list) import numpy as np from scipy import stats import matplotlib.pyplot as plt n_attempts = 100000 N = 10000 # False Negative calculation p_value_eq_list = [] beta = 1 i = 1 while i <= n_attempts: x_1 = np.random.exponential(beta, N) x_2 = np.random.exponential(beta, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_eq_list.append(p_value) i += 1 False_Negative = sum([i < 0.05 for i in p_value_eq_list])/len(p_value_eq_list) # False Positive calculation p_value_noneq_list = [] beta_1 = 1 beta_2 = 1.05 i = 1 while i <= n_attempts: x_1 = np.random.exponential(beta_1, N) x_2 = np.random.exponential(beta_2, N) _, p_value = stats.ttest_ind(x_1, x_2, equal_var=False) p_value_noneq_list.append(p_value) i += 1 False_Positive = 1 - sum([i < 0.05 for i in p_value_noneq_list])/len(p_value_noneq_list) Conclusion Now we know the answer to the question about a prohibition on applying a t-test for abnormal distribution—yes, we can apply it to most distributions!