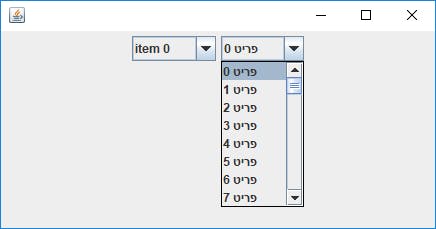
I was recently faced with a somewhat esoteric issue: rendering performance of a Swing application. Wait, what? who uses Swing in 2018? Well, when it comes to desktop applications, Swing still has several advantages: it is platform independent (that’s a part of Java’s nature), robust, rich and powerful. Of course, it also has its disadvantages — but that is not our topic today… Java Hebrew (actually non-English) string rendering performance In one of the projects I’m working on there was a weird issue: rendering of long lists of Hebrew strings took a lot of time. I’m talking about several seconds of frozen GUI while a list is rendering. When I replaced the list items with English (ASCII) strings, everything worked smoothly. After some digging into the code, It looked like the source of the problem relies deep inside the Swing code — in one of the classes within the JRE itself. Luckily, Java is an open source language, so I was able to dig into the JRE classes and find the cause of this slow rendering issue. How Strings are measured Let’s look at a simple case: a JComboBox with a String based model. This is one of the basic Swing components, that is basically comprised of an input field and a drop-down list. When this component is rendered on the screen, the strings in the list should be drawn on the screen. At some point of the rendering process, the width of the strings is calculated in order to determine the list dimensions. And here comes the interesting part: ASCII characters are handled differently than non-ASCII characters. Before we take a look at the code, it is important to understand why ASCII and non-ASCII characters are handled differently: in a string that contains only ASCII characters, we can safely say that the width of the string is equal to the width of the characters building it. This sentence can sound trivial, but in fact this is not true for all languages, as explained in the : Java documentation “A glyph is the visual representation of one or more characters. The shape, size, and position of a glyph is dependent on its context. Many different glyphs can be used to represent a single character or combination of characters, depending on the font and style. For example, in handwritten cursive text, a particular character can take on different shapes depending on how it is connected to adjacent characters.” With that in mind, let’s have a look at the code inside a method called in the class ( ). As the name suggests, this method takes a string and returns it width after rendering it (in arbitrary typographic units): stringWidth FontDesignMetrics here is the original source file The original stringWidth method (from the FontDesignMetrics class) I want to draw special attention to the for loop that starts on line 473 (in the above image). This loop is going through the characters of the measured string. In case of an ASCII string (0x100 is equal to decimal 256), the width is aggregated as the sum of the characters widths. A character width is obtained via the method, which uses an internal cache for optimized performance. getLatinCharWidth And what about non-ASCII characters? If the call to the (line 477) will return true (and for Hebrew characters — it does), the width will be calculated for the whole string and the for loop will break. That means that each string must be rendered as a whole in order to determine its width. And this is exactly the cause to our performance issue. FontUtilities::isNonSimpleChar Here comes the interesting part. In most cases, we can treat Hebrew letters like Latin characters. In other words — we actually can say that the width of a Hebrew string is equal to the sum of its characters. With that in mind, we can calculate the width of each Hebrew character only once and cache the result (basically the same treatment Latin characters gets). Here is the revised code: The revised stringWidth method In line 481, Hebrew characters (characters with value between and ) are now treated differently, accumulating the width as the sum of the characters, using cached values. 0x0590 0x05ff Replacing a JRE class? This is great in theory — but now we face another problem. The class resides in the package, which is a part of the JRE’s runtime jar (rt.jar file). When the Java classloader looks for a class, it first scans the bootstrap classes (including rt.jar), and if the class is found there — this version of the class will be used, so we cannot shadow the original class by cloning it to our ( ). How can we still use the custom version of this class? There are number of options, which are also discussed in : FontDesignMetrics sun.font codebase see the Java documentation this interesting stackoverflow thread Changing the source code and rebuilding the JRE binaries. This option has many downsides: first of all, this is not such a simple task. In addition, clients will have to install our the revised JRE on their machines, exposing them to possible security vulnerabilities. Also, there is the legal side of the deal (although using OpenJDK that should not be a problem). Finally — rebuilding the JRE because of a minor change in a single class is like using a sledgehammer to crack a nut… Using the JVM flag to prepend the class to the classpath. This is a non-standard flag that is not intended for production use due to license issues (It “violates the JRE binary code license”, as specified in the ). Xboothclasspath/p java command documentation Using the Java instrumentation API to replace the class file during runtime. I believe this is the most elegant solution — so let’s see it in action! Building a java agent The allows runtime bytecode manipulation. This API is accessed by using the Instrumentation object, which is obtained in a special way, even before the main method is called. Java instrumentation API To get a hold of this special object, one must implement a Java agent — a JAR file with a special manifest attribute and a class implementing the method. As the name suggests, this method is called by the JVM before the program’s main method and gets an instance of the Instrumentation object as a parameter. premain The agent code is available in . The Agent class contains the method, as indicated in the manifest file. Inside this method, I used the Instrumentation instance to register a implementation, which is able to intercept classloader calls and replace a requested class during runtime . When this agent is active, each call to the classloader is inspected, and if the requested class is the class that we want to replace — it returns the modified version of the class. this bitbucket repository premain ClassFileTransformer Results So… is it really working? here are the loading times of the test application: Without the agent injecting the modified class — 7232 ms. With the agent — only 290 ms! Test application loading time without the agent — more than 7(!) seconds Now with the agent — less than 300ms… Final thoughts Introducing changes to the JRE class files is probably not the best idea in most cases, But sometimes there is no choice: Swing maintenance is not exactly the first priority in the language roadmap. Of course, we can take another approach for this issue: simply not rendering long lists by keeping the full list model in-memory and feeding the list as necessary. This solves the rendering performance issue but adds complexity to the code. Either way, I think there is a lot to learn from this little journey inside the JRE and the Instrumentation API. All the code presented in this post can be found in . my Bitbucket repository