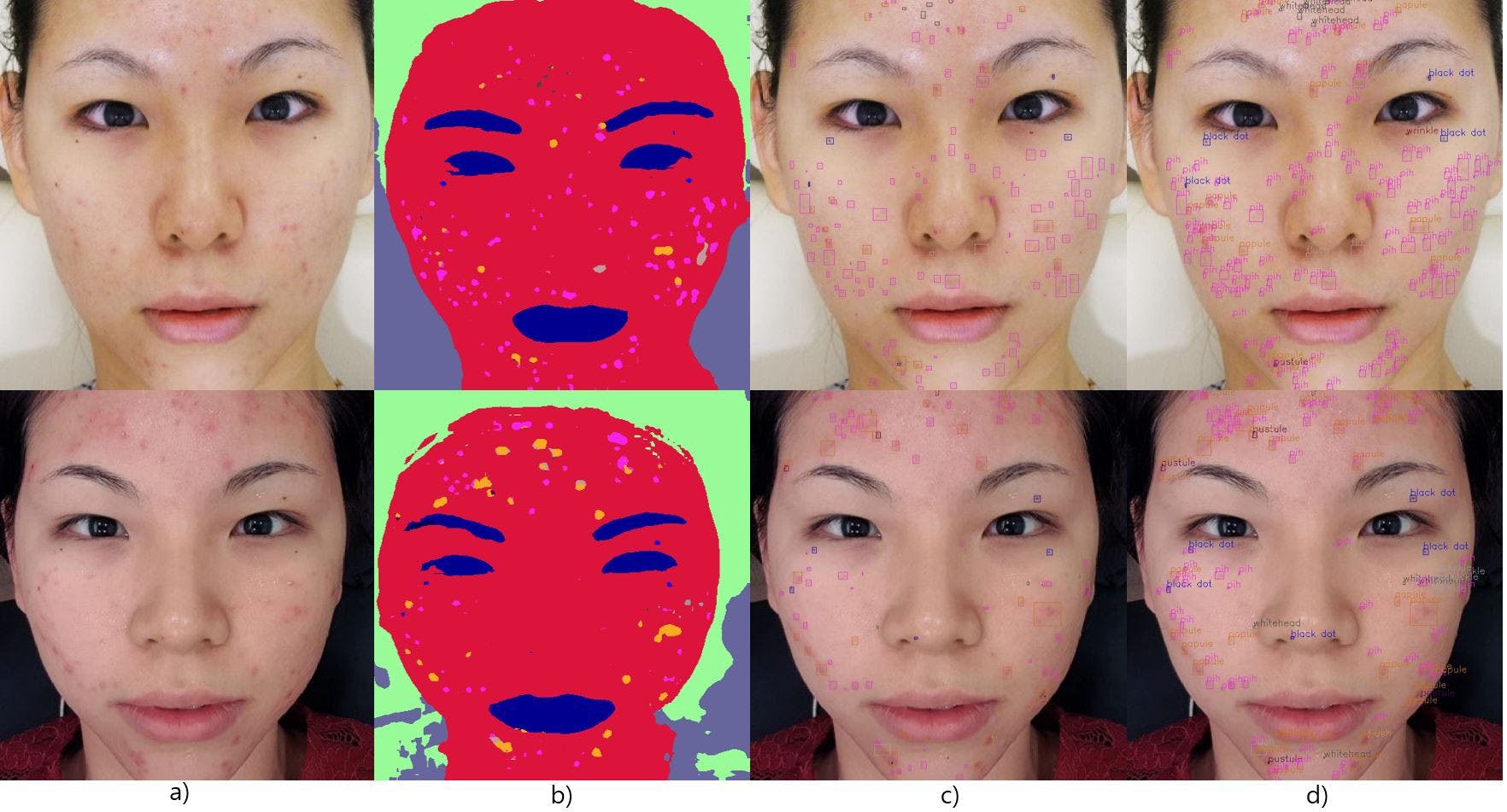
In August 2019, a group of researchers from propose the state-of-the-art concept using a semantic segmentation method to detect the most common facial skin problems accurately. The work is accepted to . lululab Inc ICCV 2019 Workshop Outline 1. The Concept of Object-by-Object Learning 2. Dataset 3. REthinker Blocks 4. REthinker Modules VS SENet Modules 5. RethNeT 6. Results 1. The Concept of Object-by-Object Learning In fact, skin lesion objects have visual relations between each other where it helps easily humanity to judge what type of skin lesions they are. Precisely, there are the , and interactions between some skin lesions where the detection of an object class helps to detect another by their co-occurrence interactions (e.g., wrinkle and age spots, or papule and whitehead, etc.). The detection decisions about individual skin lesions can be switched dynamically through contextual relations among object classes. This cognitive process is denoted as . region-region object-region object-object object-by-object decision-making Simply, object-by-object learning is observed when an object can be identified by looking at other objects. 2. Dataset The researches prepared a dataset called with pixel-wise labeling of frontal face images. Reported that the designing of is unique in ML community where it is not available such a dataset with the labeling of multi-type skin lesions of facial images. ”Multi-type Skin Lesion Labeled Database” (MSLD) MSLD 412 images have been annotated with the labeling of 11 common types of facial skin lesions and 6 additional classes. The skin lesions are . The additional classes are Reported that they do not disclose their (MSLD) dataset as the user’s privacy is taken under the responsibility. whitehead, papule, pustule, freckle, age spots, PIH, flush, seborrheic, dermatitis, wrinkle and black dot normal skin, hair, eyes/mouth/eyebrow, glasses, mask/scarf and background. 3. The REthinker Block Proposed a REthinker module based on the SENet module and locally constructed convLSTM/conv3D unit to increase the network’s sensitivity in local and global contextual representation that helps to capture ambiguously appeared objects and co-occurrence interactions between object classes. 4. REthinker Modules VS SENet Modules REthinker modules consist of the SENet module and locally constructed convLSTM/conv3D layers as an one-shot attention mechanism, which are both responsible for extracting contextual relations from features. Precisely, as the global pooling of SENet module aggregates the global spatial information, the SE module passes more embedded higher-level contextual information across large neighborhoods of each feature map. Whereas, the locally constructed convLSTM/conv3D layers encode lower-level contextual information across local neighborhoods elements of fragmented feature map (patches) while further take spatial correlation into consideration distributively over patches. Batch_size, H, W, C = image.get_shape() patches = tf.image.extract_image_patches(image, patch_size, patch_size, [ , , , ], ) patches = tf.reshape(patches, [Batch_size ,patch_size[ ]*patch_size[ ], patch_size[ ], patch_size[ ], C]) patches _, N, H, W, C = patches.get_shape() patches = tf.reshape(patches, [ , image_shape[ ], image_shape[ ], C]) rec_new = tf.space_to_depth(patches, H) rec_new = tf.reshape(rec_new, [ , image_shape[ ], image_shape[ ], C]) rec_new _, H, W, C = inputs.get_shape() net = image_to_patches(inputs, patch_size=[ , , , ]) net = tf.keras.layers.ConvLSTM2D(depth, kernel_size=kernel_size, padding= , dilation_rate=rate, return_sequences= )(net) net = patches_to_image(net, image_shape=[H, W]) net residual = inputs inputs = contructed_convLSTM(inputs,depth,kernel_size,rate=rate) _, H, W, C = inputs.get_shape() residual = tf.keras.layers.GlobalAveragePooling2D(name= + prefix)(residual) residual = tf.keras.layers.Dense(C.value // , activation= , name= + prefix + )(residual) residual = tf.keras.layers.Dense(C.value, activation= , name= + prefix + )(residual) residual = tf.keras.layers.Reshape([ , , C.value])(residual) outputs = tf.keras.layers.Multiply(name= + prefix)([residual, inputs]) outputs : def image_to_patches (image, patch_size=[ , , , ]) 1 4 4 1 1 1 1 1 'VALID' 1 1 1 1 return : def patches_to_image (patches, image_shape) -1 0 1 1 0 1 return : def contructed_convLSTM (inputs, depth,kernel_size, rate) 1 4 4 1 #print(net) 'same' True # net = tf.keras.layers.Conv3D(depth, kernel_size=kernel_size, padding='same', dilation_rate=rate)(net) #print(net) return : def RethBlock (inputs, depth,kernel_size, rate, prefix=None) 'Globalpooling_SeNet' 8 'relu' 'fc_SeNet' '_squ' 'sigmoid' 'fc_seNet' '_exc' 1 1 'scale' return Note that this is a fast implementation of REthinker blocks that support only when the input size has the root of a number such as 256x256, 64x64, 16x16, etc ... 5. RethNeT In practice, proposed REthinker blocks are applicable in any standard CNNs. However, in this work, is considered as the current state of the art network and powered with REthinker blocks. Furthermore, there are lightweight versions of RehNet based on MobileNet v2 and IGCV3. The use of the REthinker modules forces networks to capture the contextual relationships between object classes regardless of similar texture and ambiguous appearance they have. An Encoder Search: Xception In fact, the rich contextual information is a key to capturing ambiguously appeared objects and co-occurrence interactions between object classes where that is usually obtained in encoders. Therefore, the decoder path is not considered and just used decoder of to recover object segmentation details of individual skin lesions. A Decoder Search: DeepLabv3+ Simply investigated RethNet with the combining of the Xception module and REthinker modules. Xception is modified as follows: RethNet: The REthinker module added after each Xception block without spatial loss of feature maps. The final block of the entry flow of Xception is removed. The patches size as 4x4 in each REthinker module is kept in order to ”see” future maps wider in ConvLSTM/conv3D with simply increasing time steps. The number of parameters is minimized in the middle flow and exit flow of Xception. The max-pooling operation is replaced by the depthwise separable convolutions with striding and the batch normalization and ReLU is applied after each 3 x 3 depthwise convolution of the Xception module. 6. Results The inference results of RethNet seem pretty good if you check the title image of the blog post that is the inference result of RethNet in real test images. According to the comparison results, it shows significant improvements in the facial skin lesion detection task of the dataset, representing a 15.34% improvement over Deeplab v3+ (MIoU of 64.12%). MSLD If you find the work useful for your research, please consider citing : our paper @InProceedings{Bekmirzaev_2019_ICCV_Workshops, author = {Bekmirzaev, Shohrukh and Oh, Seoyoung and Yo, Sangwook}, title = {RethNet: Object-by-Object Learning for Detecting Facial Skin Problems}, booktitle = {The IEEE International Conference on Computer Vision (ICCV) Workshops}, month = {Oct}, year = {2019} }