














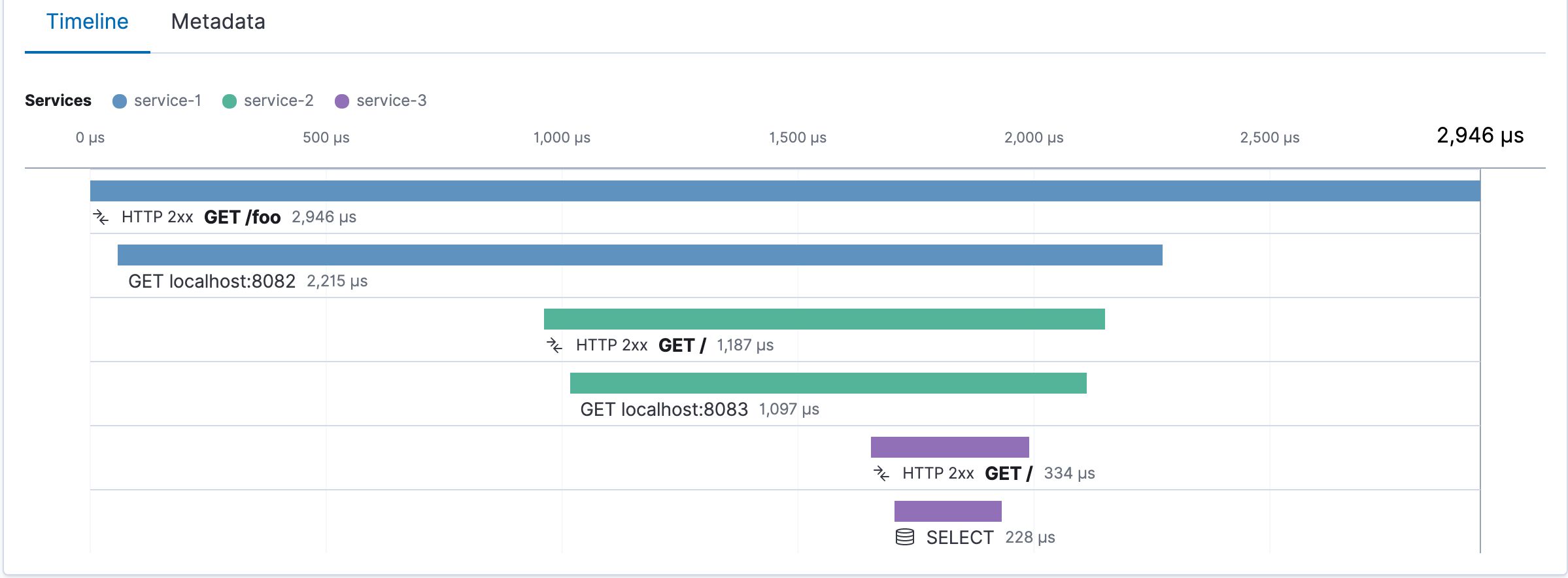
Custom TraceID in Elastic APM


Aug 01, 2020

Asserts transforms your Prometheus metrics into root cause insights by creating a dependency map of your app environment
Asserts transforms your Prometheus metrics into root cause insights by creating a dependency map of your app environment
Asserts transforms your Prometheus metrics into root cause insights by creating a dependency map of your app environment
Asserts transforms your Prometheus metrics into root cause insights by creating a dependency map of your app environment







