540 reads
Goodbye, Cost-depth Trade Off: Cloud-Native Observability, Redefined
by byShahar Azulay, CEO and Co-Founder of groundcover@groundcover1
byShahar Azulay, CEO and Co-Founder of groundcover@groundcover1
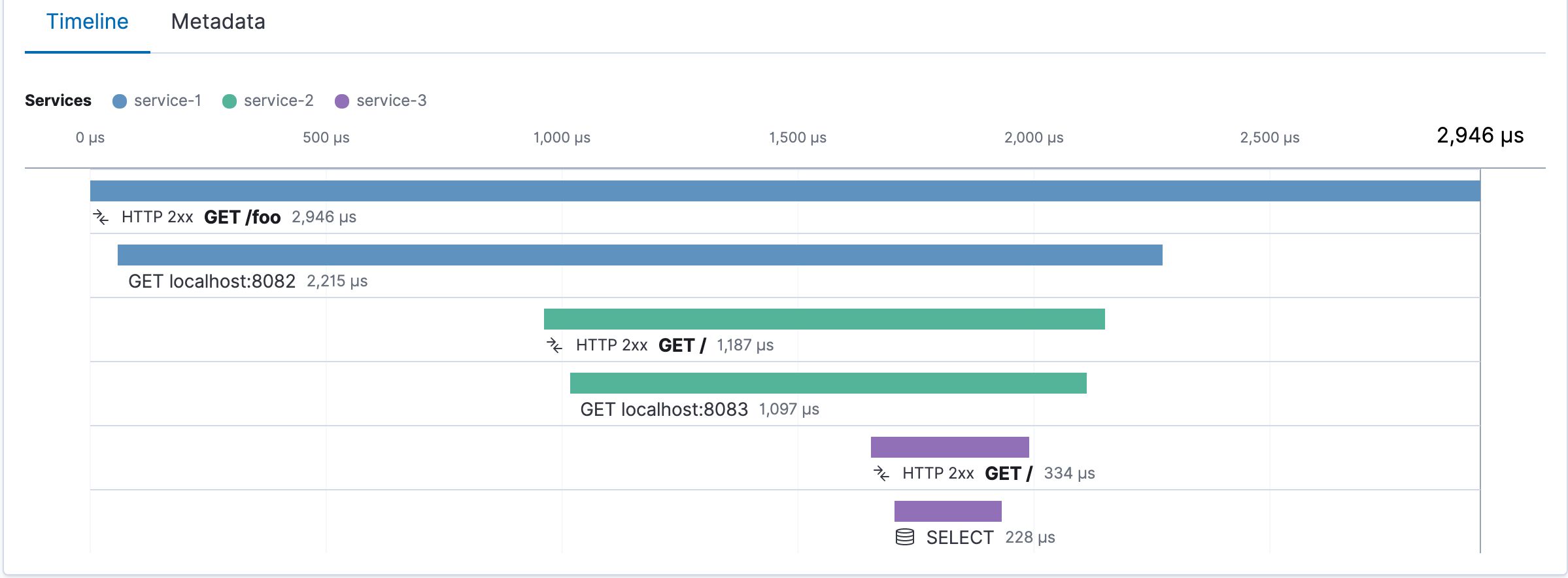
Using eBPF to help teams get a clear picture of their K8s applications: discovering + solving bleeding issues faster.
June 22nd, 2022






Using eBPF to help teams get a clear picture of their K8s applications: discovering + solving bleeding issues faster.


Using eBPF to help teams get a clear picture of their K8s applications: discovering + solving bleeding issues faster.
About Author

Using eBPF to help teams get a clear picture of their K8s applications: discovering + solving bleeding issues faster.
Comments