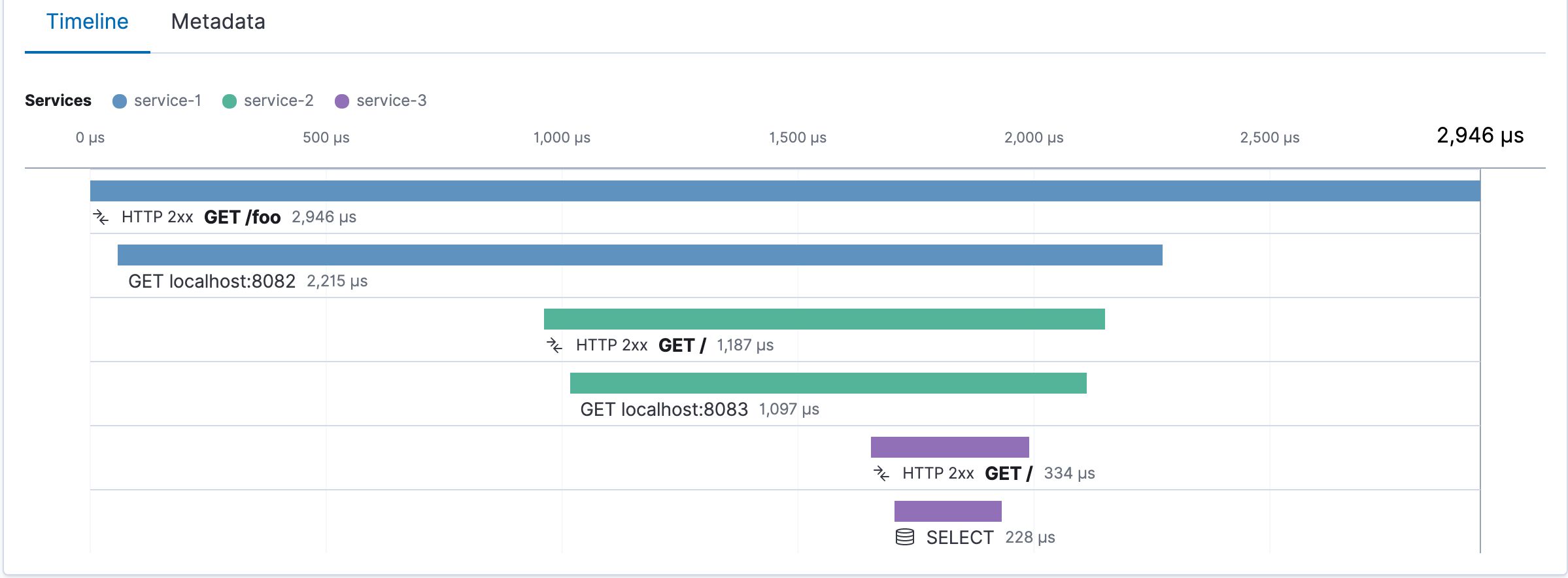
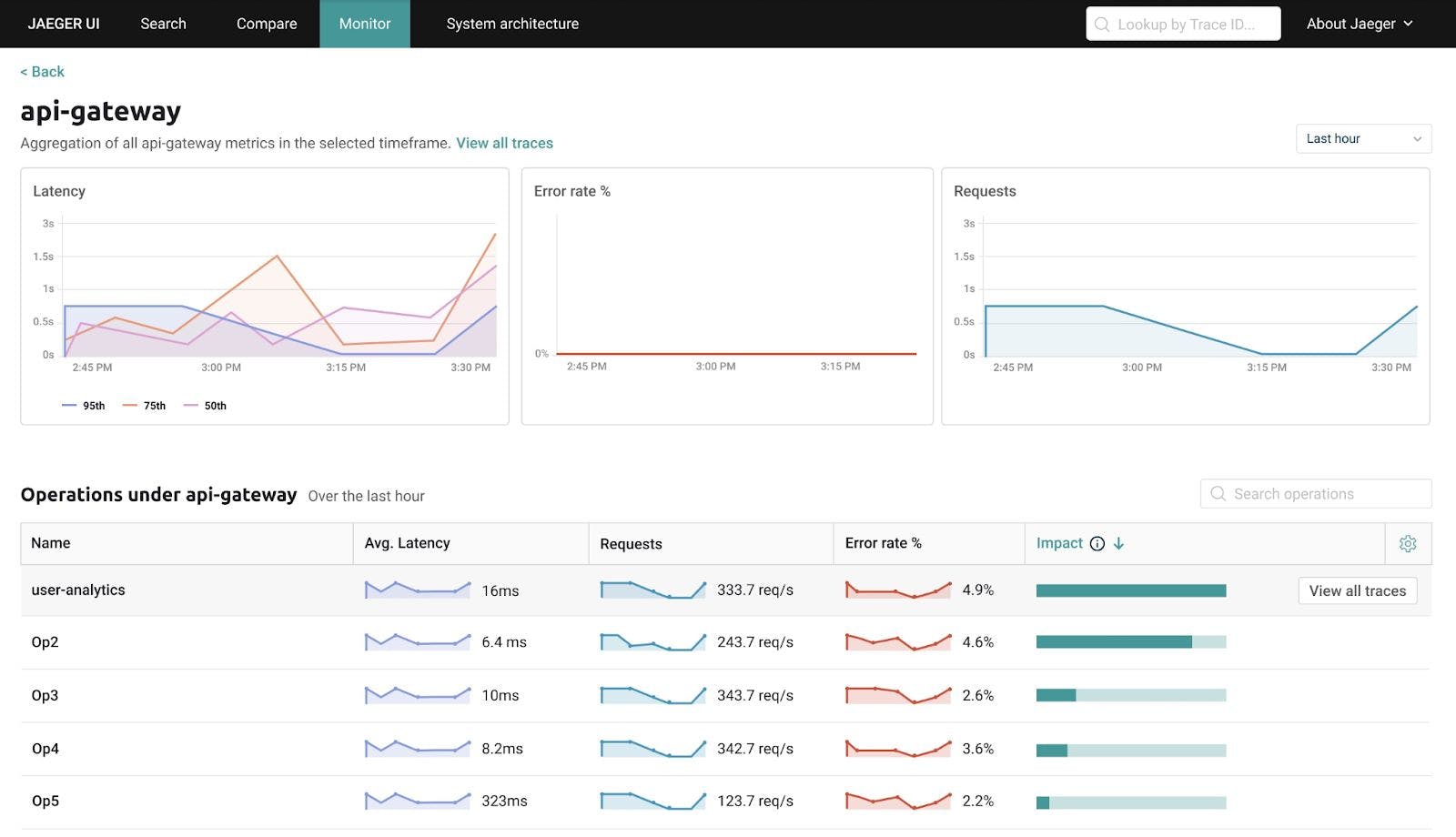
Pinpointing Root Causes of Application Performance Problems in Dynamic Environments Pinpointing the root cause of application performance problems in a dynamic environment often resembles a complicated game of hide-and-seek. A familiar analogy is that it’s like trying to find a needle in a haystack. This characterization illustrates the challenge but isn’t especially helpful in offering solutions. So, if the root cause of an application problem is the “needle” and the application environment is the “haystack,” how exactly would we go about restoring peak performance? Taking the analogy literally is actually a pretty good way to explore the various approaches to resolving application performance problems in dynamic, elastic, and transient infrastructure environments. So, exactly how would you go about finding a needle in a haystack? 1. Eliminate the haystack Probably the fastest way to find the needle is to burn the haystack. Or dumping the hay into a pool of water and waiting for the needle to sink to the bottom would also work. If we were really talking about needles and haystacks, fine — but we’re not. There are fundamental business reasons why more and more companies are turning to dynamic cloud-based deployments in the first place. We can pretty much reject the option of returning to monolithic, static infrastructure where identifying application performance cause-and-effect relationships is more straightforward. 2. Rummage for the needle manually We could sift through the pile of hay, strand by strand, until we find the needle. That’s basically the way traditional (APM) tools work. They throw a massive collection of data at us (albeit usually in nicely formatted charts and graphs) and require us to comb through it all to figure what went wrong. Actually finding the needle remains a laborious manual process. Somebody somewhere has to pore over the charts and graphs, make sense of the data, and connect the dots to discover the root cause. Such handwork analysis can take hours — even days. application performance monitoring That’s too long when application problems are leading to disgruntled customers. Of course, things would go faster if we assigned more staff to tackle the problem: the more people sifting through the hay, the sooner we’d find the needle. But convening a war-room assembly to interpret the data is still a labor-intensive, time-consuming effort. Already most CIOs are frustrated that so many man-hours are spent on troubleshooting instead of innovating and optimizing. Furthermore, and perhaps more significant, today’s liquid environments — where millions of dependencies are changing on the fly from moment to moment — are simply too complex and too fast-moving, with too many performance data points, for humans to analyze in a timely manner. It would take more people than any business has at its disposal to detect causal relationships among so much data and identify the component that’s causing the problem. 3. Locate the general area of the needle Using a metal detector or an X-ray would narrow down the approximate location of the needle within a haystack. This is more efficient than looking through the entire pile, but it’s still a lot of work. We still have to manually sift through the hay — just not as much. Similarly, a handful of modern APM solutions get us a step closer. Discovery agents collect and correlate myriad metrics and performance data points from various distributed elements across the application environment. The data is consolidated and presented in a unified, integrated “single pane of glass” view. We now have a clear, comprehensive picture of the of the performance problem, but we haven’t diagnosed the The hard work is still left to us. We still have to pore through charts and graphs of data — just not as much. Modern APM displays the data within a more meaningful framework that helps us narrow down our focus. symptoms root cause. Now, imagine the difficulty when the needle is constantly on the move. That’s exactly what’s happening with today’s highly dynamic environments. Servers are perpetually coming and going, auto-scaling up and down as needs dictate. Container technology and microservices architecture are even more transient — moving from host to host — and generate even more metrics. With our applications now having so many moving parts, trying to keep up with them and their topology by dissecting a plethora of charts and graphs is literally beyond human capabilities. Dynamic applications have millions of dependencies that need to be analyzed, and they’re ever changing. No sooner do we think we have a handle on how everything is working together than the landscape changes and we’re back to square one. Present-day application environments change too fast and too often for even the most talented troubleshooters. Even a relatively simple containerized environment like this one, with only 142 hosts, has more dependencies than a human being can track without software assistance. 4. Extract the needle automatically Ultimately, the best way to find the needle (especially if it won’t sit still) is to use a powerful magnet to pull it right out of the haystack and deliver it into your hands. In our analogy, a next-generation solution would be such a “magnet.” It zeroes in on an application problem’s root cause automatically, rendering time-consuming manual analysis unnecessary — the same way a magnet obviates the need to sift through the pile of hay. artificial intelligence–powered APM Artificial intelligence (AI) enables computers to do what they do best: absorb huge amounts of information and make sense of it faster and more thoroughly than is humanly possible. It applies sophisticated algorithms and context-rich diagnostics to detect and correlate causal relationships among data with millions of dependencies in microseconds. In essence, AI-enhanced monitoring analyzes the problem the same way we humans would, only faster. Artificial intelligence is able to perform almost instantaneously the analytical “heavy lifting” that takes us humans hours or days. From theory to reality: Dynatrace APM Artificial intelligence has been defined as “being able to perceive its environment and apply cognitive functions such as learning and problem-solving.” has been built on artificial intelligence so that it is able to Dynatrace APM auto-discover all components of the full technology stack end to end from the customers’ web browsers all the way down to the host infrastructure — map out the entire IT in an interactive visual display environment identify the millions of dependencies among websites, applications, services, processes, hosts, , and cloud infrastructure networks learn how it all works together and what constitutes normal behavior automatically detect, analyze, and prioritize anomalies and performance problems actually recommend solutions to the root cause of those problems And AI allows Dynatrace to do all this at a speed, scale, and precision that no human could ever match. Dynatrace gets to “know” applications. Its proprietary Smartscape technology continuously auto-discovers and monitors every aspect of every application. Sophisticated algorithms learn normal application performance patterns and proactively flag anomalies. The AI auto-adjusts baselines dynamically in real time to avoid false positives caused by preset static alerting thresholds. Application performance problems are seldom isolated, one-time events, and they’re usually symptoms of a larger issue. Dynatrace looks at all other transactions that used the same components around the same time to see if they also experienced problems. Artificial intelligence correlates events throughout the full technology stack — client side, server side, infrastructure level — to identify analogous issues and detect causal relationships. AI diagnostics analyze the vast amount of data collected to pinpoint the exact component that’s causing the problem. In today’s increasingly complex and fluid IT environments, interpreting data points with millions of dependencies in order to determine underlying casual relationships is more than humans can master by themselves. Only artificial intelligence can take the colossal volume of data and translate it into actionable solutions before problems hit customers. See for yourself what Dynatrace can do. Dynatrace offers a — the complete full-blown version, not a stripped-down demo — that auto-discovers and visually maps out your entire technology stack within minutes. free trial