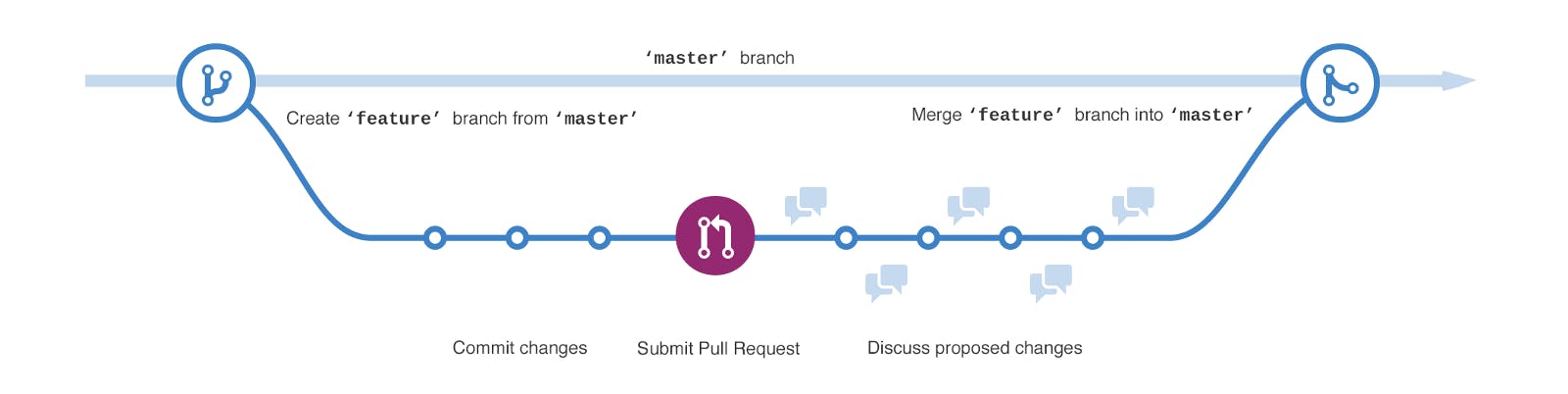
Rewriting history without a time machine Like , is an endless debate. Both have pros and cons but to the question of whether merging or rebasing is better: hopefully you’ll see that it’s not that simple. is a powerful tool, and allows you to do many things to and with your history, but every team and every project is different. If you know how both of these things work, it’s up to you to decide which one is best for your particular situation. Vim vs Emacs Merging vs Rebasing Git Why do I need to rebase? From a content perspective, rebasing really is just moving a branch from one commit to another. But internally, Git accomplishes this by creating new commits and applying them to the specified base — it’s literally your project history. The general process can be visualised as the following: rewriting When a feature branch’s development is complete, / all the work down to the minimum number of meaningful commits and avoid creating a merge commit. This way code history remains flat and readable. Clean, clear commit messages are as much part of the documentation of your code base as code comments. For this reason, it’s important not to pollute history with 50 single-line commits that partially cancel each other out for a single feature or bug fix. rebase squash Git rebase interactive Interactive rebasing gives you the opportunity to alter commits as they are moved to the new branch. This is even more powerful than an automated rebase, since it offers complete control over the branch’s commit history. Typically, this is used to clean up a messy history before merging a feature branch into . It lets you clean up history by removing, splitting, and altering an existing series of commits. It’s like on steroids. develop git commit --amend To begin an interactive rebasing session, pass the option to the command: i git rebase git checkout featuregit rebase -i origin/develop This will open a text editor listing all of the commits that are about to be moved: This listing defines exactly what the branch will look like after the rebase is performed. By changing the command and/or (such a cool feature), you can make the branch’s history look like whatever you want. For example, if the #2 commit fixes a small problem in the #1 commit, you can condense them into a single commit with the command (or for short): pick re-ordering the entries fixup f When you save and close the file, Git will perform the rebase according to your instructions. Most developers like to use an interactive rebase to polish a feature branch before merging it into the main code base. This gives them the opportunity to squash insignificant commits, delete obsolete ones, and make sure everything else is in order before committing to the “official” project history. To everybody else, it will look like the entire feature was developed in a single series of well-planned commits. Squashing Eliminating insignificant commits makes your feature’s history much easier to understand. This is something that simply cannot do. git merge There are ways to squash commits, the following are the ones I use the most. several By using the the interactive rebasing git rebase -i HEAD~3 It’s HEAD~3 because it is the number of commits in this branch If you are not sure about the amount of commits the branch has, you can perform a get the hash of the commit before you started working on this feature and do a: git log --oneline git rebase -i 3598fe2 If you lost track of how many commits are in your branch you can create an alias in your : .gitconfig [alias] count = Running will tell you the number of commits you have diverged from , note that it can be used with any branch name. git count **develop** develop Or by reseting “X” number of commits git reset --soft HEAD~X After this command, your last X commit changes will be unstaged so you’ll need to create a new commit to override them. git add .git commit -am "Feature Z is completed" This way is great when you open a pull request and someone tells you to fix something, you can just go back “1” commit, fix what you need to fix and force push it. Force pushing Now that we’ve rewritten history locally we need to override the remote by force pushing it to upstream. git push origin feature_branch --force Git’s is because it with whatever you have locally, overwriting any changes that a team member has pushed in the meantime, so . push --force destructive overwrites the remote repository possibly be super cautious about this , --force less known little brother --force-with-lease This option allows you to force push without the risk of unintentionally overwriting someone else’s work. It will only allow you to force-push if no-one else has pushed changes up to the remote in the meantime. If there are new remote commits, will fail, prompting us to fetch first. --force-with-lease If you intend to use it often, create an alias in your : .gitconfig [alias] pf = push --force-with-lease computer says no In the end… The main decision revolves around this: In the first case go for a policy, in the later go for a one. Do you value more a clean, linear history? Or the traceability of your branches? rebase merge Thanks … for getting this far! I would love to know what do you think and if you do something in a different way. Also it would be awesome if you click the little ❤️ and share the article so more people would benefit from it. If you are interested in more tech related topics, please check my other articles, follow me on or check my projects. Twitter GitHub Sources _Translations started for Azərbaycan dil, Беларуская, Català, Esperanto, Español (Nicaragua), فارسی, हिन्दी, Magyar…_git-scm.com Git - The Command Line _Compare git rebase with the git merge command and identify all of the potential opportunities to incorporate rebasing…_www.atlassian.com Merging vs. Rebasing _The Gitflow Workflow streamlines the release cycle by using isolated branches for feature development, release…_www.atlassian.com Gitflow Workflow _Common use cases for overwriting committed snapshots in Git. History rewriting commands: git commit--amend, git rebase…_www.atlassian.com Git - Rewriting History | Atlassian Git Tutorial _Git's push --force is destructive because it unconditionally overwrites the remote repository with whatever you have…_developer.atlassian.com --force considered harmful; understanding git's --force-with-lease - Atlassian Developers _Now, to the question of whether merging or rebasing is better: hopefully you'll see that it's not that simple. Git is a…_git-scm.com Git - Rebasing _Atlassian Git Tutorial_www.atlassian.com Git team workflows: merge or rebase? _A gentler git push --force ._robots.thoughtbot.com Force push with care _The more you work with Git, the faster you’ll learn its workflows._medium.freecodecamp.com Bash Shortcuts to Enhance Your Git Workflow