














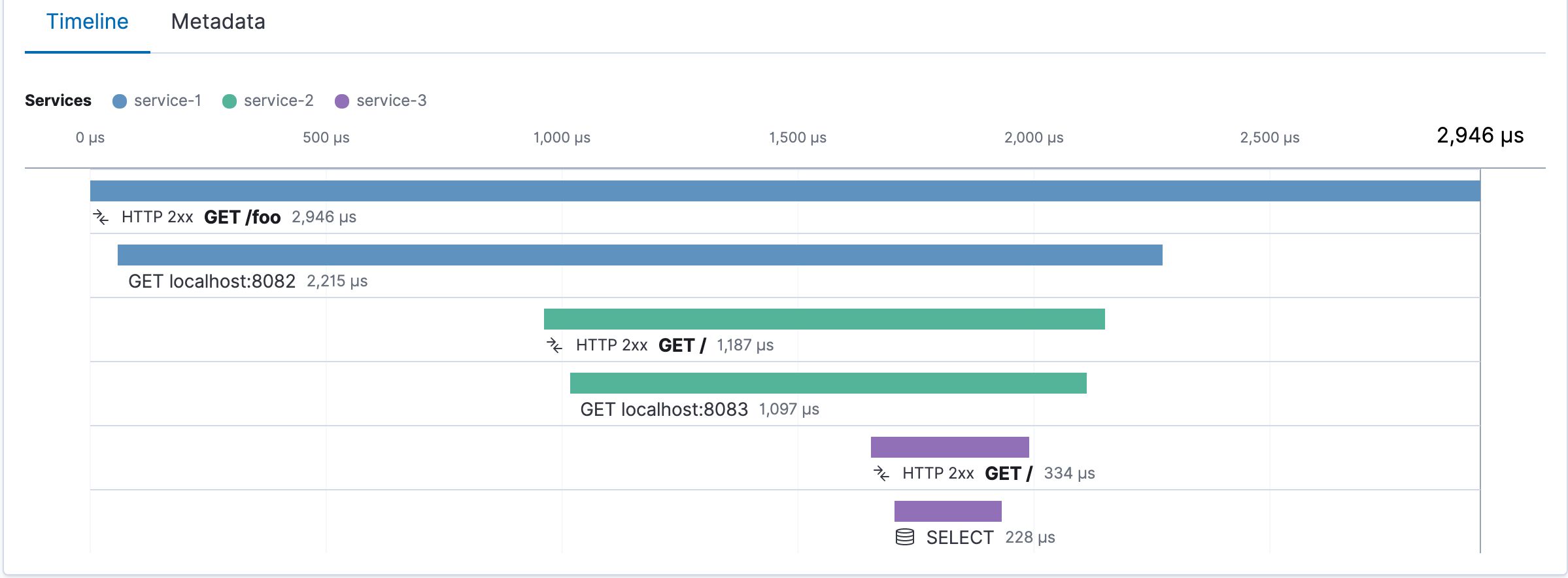
Custom TraceID in Elastic APM


Aug 01, 2020

OpenResty is designed to help developers easily build scalable web applications, web services, and dynamic web gateways.
OpenResty is designed to help developers easily build scalable web applications, web services, and dynamic web gateways.
OpenResty is designed to help developers easily build scalable web applications, web services, and dynamic web gateways.
OpenResty is designed to help developers easily build scalable web applications, web services, and dynamic web gateways.







