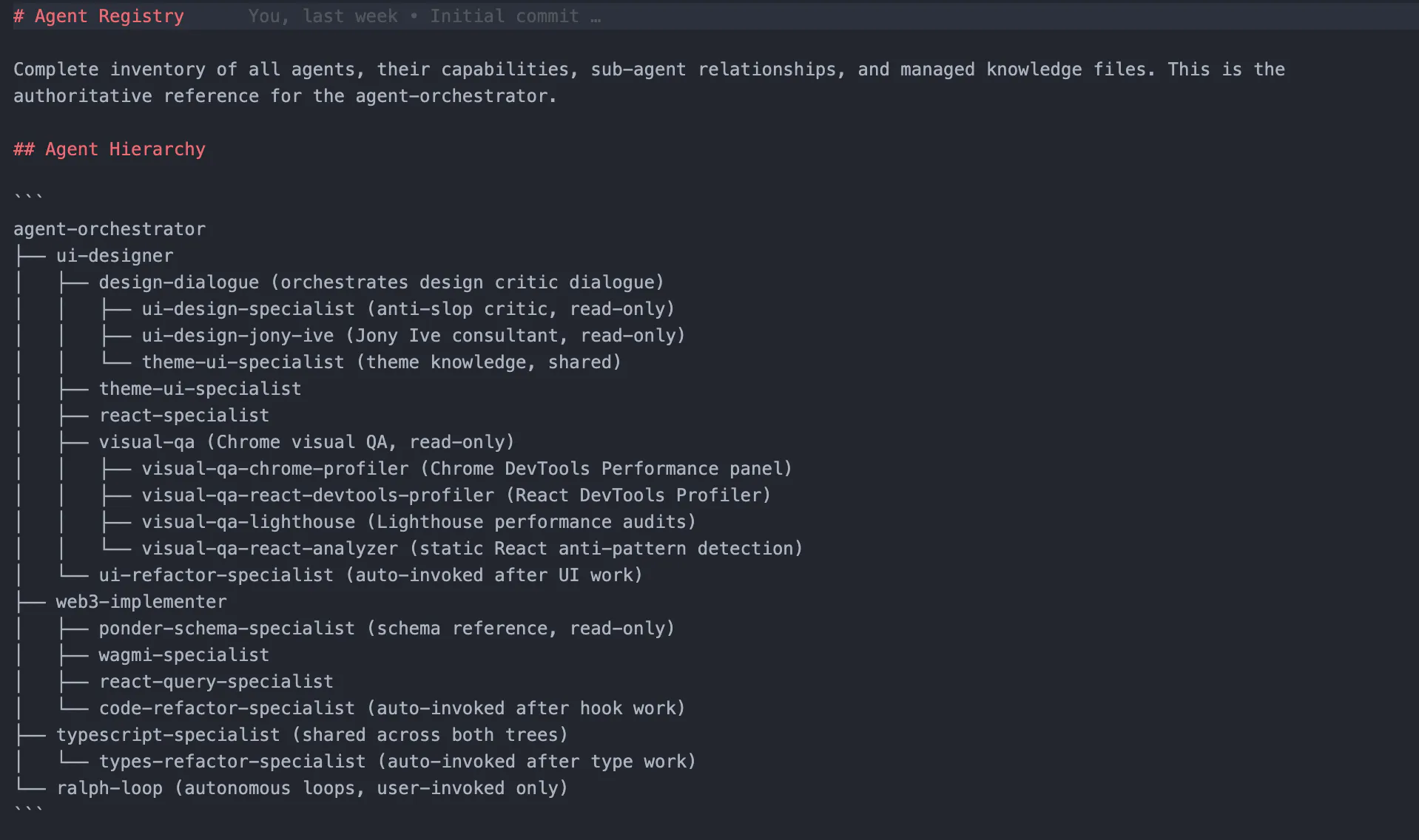
Part 1: Why Agentic Engineering Isn't Vibe Coding A friend recently posted about AI skills using The Matrix analogy: Trinity doesn't learn to fly a helicopter — Tank uploads a precise, verified program directly into her mind. She steps into the cockpit and flies. A friend recently posted about AI skills using The Matrix analogy: Trinity doesn't learn to fly a helicopter — Tank uploads a precise, verified program directly into her mind. She steps into the cockpit and flies. That analogy is perfect. But it exposes a fundamental misunderstanding about how these systems actually get built. Trinity doesn't vibe her way into flying. Tank uploads a precise, verified program. precise, verified program That's the difference between vibe coding and what Addy Osmani calls Agentic Engineering. "Vibe coding" has poisoned the well — it suggests you can prompt your way to production software. You can't. Agentic Engineering I have 70+ agents in my web3 development workflow. They're not prompt dumps. They're structured: clear responsibilities, explicit knowledge files, defined handoff points between agents. Building them took the same architectural thinking that's always separated working systems from chaos. The old principles translate directly: DRY → DRYP (Don't Repeat Your Prompt) Separation of concerns → Agent boundaries Interface design → Handoff contracts Documentation → Precompiled context DRY → DRYP (Don't Repeat Your Prompt) DRY → DRYP Separation of concerns → Agent boundaries Separation of concerns → Agent boundaries Interface design → Handoff contracts Interface design → Handoff contracts Documentation → Precompiled context Documentation → Precompiled context Building good skills is architecture work. The Trinity scene works because someone engineered that pilot program. Tank didn't vibe code it. engineered The Problem That Started Everything The biggest thing I learned building AI coding workflows: more context is not better. more context is not better I work in web3. I have ABIs that are thousands of lines. A Ponder database schema that would eat half the context window if I fed it in raw. My first instinct was to give the AI everything and let it figure out what matters. That doesn't work. The AI gets lost. Important instructions get ignored. It latches onto random details. Results get worse as context gets bigger. There's a term for this: context rot. As the context window fills up, earlier instructions get "crowded out" and the model starts ignoring them. context rot So I built a skills-specialist agent. Its only job is precompiling context for other agents. It reads my raw ABIs, schemas, and docs, then generates slim reference files tailored to specific tasks. It builds skills. When I need UI work done, I don't hand my ui-designer the entire codebase. The skills-specialist has already built a component reference with just the props and patterns that agent needs. When I need contract integration, the web3-implementer gets only the relevant functions and events. The raw ABI stays on disk. Agents building context for agents. Agents building context for agents. The Memory Hierarchy Mental Model The mental model that made everything click: treat context like RAM, not a junk drawer. Layer What It Holds Disk Full codebase, raw ABIs, complete schemas RAM Precompiled skills — task-specific reference files Registers The current prompt and immediate context Layer What It Holds Disk Full codebase, raw ABIs, complete schemas RAM Precompiled skills — task-specific reference files Registers The current prompt and immediate context Layer What It Holds Layer Layer What It Holds What It Holds Disk Full codebase, raw ABIs, complete schemas Disk Disk Full codebase, raw ABIs, complete schemas Full codebase, raw ABIs, complete schemas RAM Precompiled skills — task-specific reference files RAM RAM Precompiled skills — task-specific reference files Precompiled skills — task-specific reference files Registers The current prompt and immediate context Registers Registers The current prompt and immediate context The current prompt and immediate context You don't load everything into memory. You load what you need for the current task. My skills-specialist is the compiler that transforms disk into RAM. Without it, I'm back to stuffing context and hoping for the best. What a Precompiled Skill Looks Like Here's the pattern my skills-specialist generates: # MorphoVault Reference > Use when implementing vault deposit/withdraw flows. ## Terminology - **shares**: Vault shares representing proportional ownership - **assets**: The underlying token being deposited ## Key Functions ### deposit(uint256 assets, address receiver) → uint256 shares Deposits assets and mints shares to receiver. See: protocols/morpho/abis/MetaMorpho.json ### withdraw(uint256 assets, address receiver, address owner) → uint256 shares Burns shares and sends assets to receiver. See: protocols/morpho/abis/MetaMorpho.json ## Events ### Deposit(address indexed sender, uint256 assets, uint256 shares) ### Withdraw(address indexed sender, uint256 assets, uint256 shares) ## Related Hooks - useVaultDeposit: src/hooks/blockchain/useVaultDeposit.ts - useVaultBalance: src/hooks/ponder/useVaultBalance.ts # MorphoVault Reference > Use when implementing vault deposit/withdraw flows. ## Terminology - **shares**: Vault shares representing proportional ownership - **assets**: The underlying token being deposited ## Key Functions ### deposit(uint256 assets, address receiver) → uint256 shares Deposits assets and mints shares to receiver. See: protocols/morpho/abis/MetaMorpho.json ### withdraw(uint256 assets, address receiver, address owner) → uint256 shares Burns shares and sends assets to receiver. See: protocols/morpho/abis/MetaMorpho.json ## Events ### Deposit(address indexed sender, uint256 assets, uint256 shares) ### Withdraw(address indexed sender, uint256 assets, uint256 shares) ## Related Hooks - useVaultDeposit: src/hooks/blockchain/useVaultDeposit.ts - useVaultBalance: src/hooks/ponder/useVaultBalance.ts Short. Scannable. Pointers to source files. Domain terms defined. Clear sections. The raw Morpho ABI is 2,000+ lines. This reference is 30 lines and contains everything an agent needs to implement a deposit flow. The Craft Behind the Curtain Skills don't build themselves. My skills-creator is itself a skill — one I built through iteration, testing, and architectural thinking. Every skill in my system has: Clear responsibilities — What does this agent own? Explicit knowledge files — What precompiled context does it need? Defined handoff points — When does it call other agents? Verification criteria — How do we know it's done? Clear responsibilities — What does this agent own? Clear responsibilities Explicit knowledge files — What precompiled context does it need? Explicit knowledge files Defined handoff points — When does it call other agents? Defined handoff points Verification criteria — How do we know it's done? Verification criteria That's not vibing. That's engineering. The distribution insight is right — skills compress the distance between user and value. But someone still has to build them well. That's the craft. Coming Up in Part 2 Next, I'll cover the organizational breakthrough that made 70+ agents manageable: the distinction between skills (personas you converse with) and agents (workers you dispatch). skills agents Turns out only ~10 needed to be conversational. The rest just needed to be discoverable. This is Part 1 of "Lessons from Building a 100+ Agent Swarm in Web3." Follow for Part 2 on agent organization, or connect if you're building similar systems. This is Part 1 of "Lessons from Building a 100+ Agent Swarm in Web3." Follow for Part 2 on agent organization, or connect if you're building similar systems.