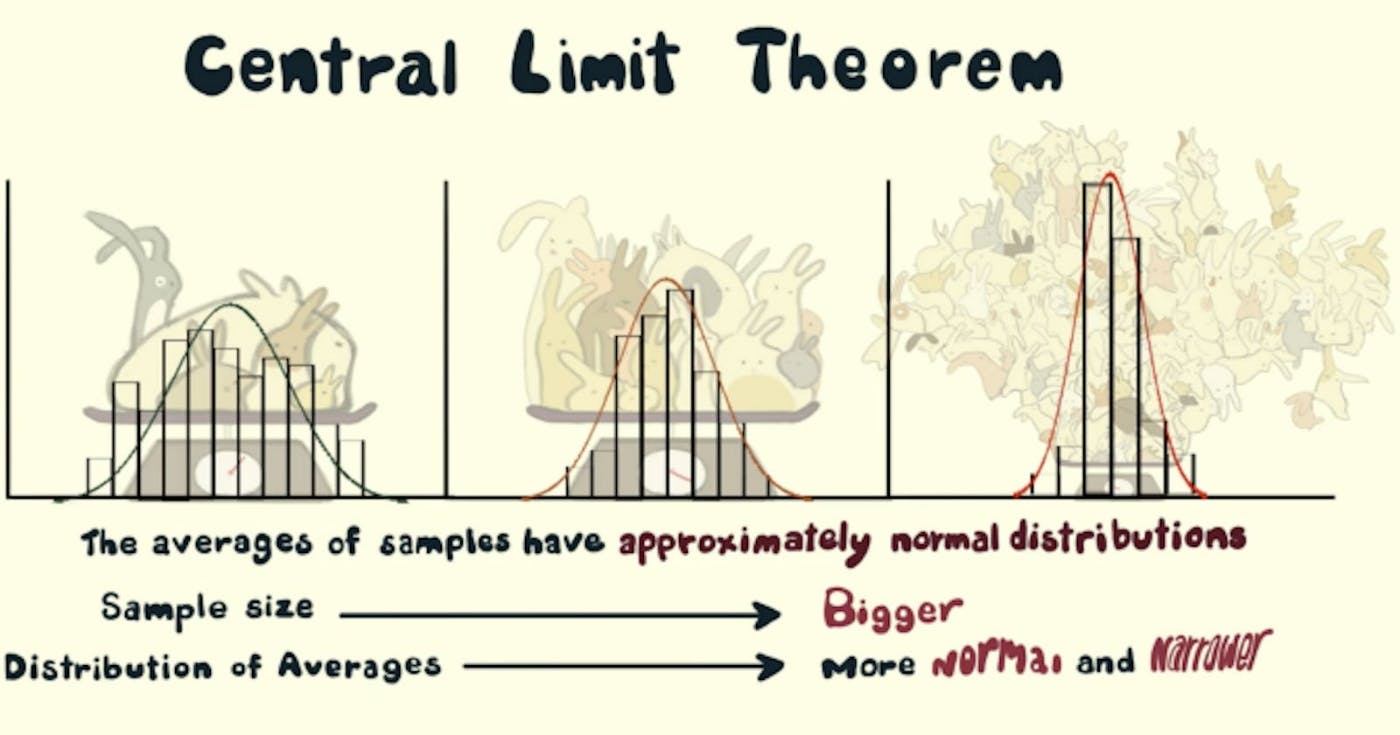
Định nghĩa, ý nghĩa và ứng dụng TLDR: Bạn có thể tìm thấy toàn bộ mã . ở đây trên GitHub Định lý giới hạn trung tâm nắm bắt được hiện tượng sau: Hãy phân phối bất kỳ! (nói về sự phân bổ số lượng đường chuyền trong một trận bóng đá) Bắt đầu lấy n mẫu từ phân phối đó (giả sử n = 5) nhiều lần [giả sử m = 1000] lần. Lấy giá trị trung bình của từng bộ mẫu (vì vậy chúng ta sẽ có m = 1000 phương tiện) Việc phân phối phương tiện sẽ (ít nhiều) . (Bạn sẽ có được đường cong hình chuông nổi tiếng đó nếu bạn vẽ giá trị trung bình trên trục x và tần số của chúng trên trục y.) được phân phối bình thường Tăng n để có độ lệch chuẩn nhỏ hơn và tăng m để có giá trị gần đúng hơn với phân phối chuẩn. Nhưng tại sao tôi nên quan tâm? Bạn không thể tải toàn bộ dữ liệu để xử lý? Không vấn đề gì, hãy lấy nhiều mẫu từ dữ liệu và sử dụng định lý giới hạn trung tâm để ước tính các tham số dữ liệu như giá trị trung bình, độ lệch chuẩn, tổng, v.v. Nó có thể giúp bạn tiết kiệm tài nguyên về thời gian và tiền bạc. Bởi vì bây giờ, chúng ta có thể làm việc trên các mẫu nhỏ hơn đáng kể so với tổng thể và rút ra kết luận cho toàn bộ tổng thể! Một mẫu nhất định có thuộc về một quần thể nhất định (hoặc một tập dữ liệu) không? Hãy kiểm tra bằng cách sử dụng giá trị trung bình mẫu, giá trị trung bình tổng thể, độ lệch chuẩn mẫu và độ lệch chuẩn tổng thể. Sự định nghĩa Cho một tập dữ liệu có phân phối không xác định (có thể là đồng nhất, nhị thức hoặc hoàn toàn ngẫu nhiên), phương tiện mẫu sẽ gần đúng với phân phối chuẩn. Giải trình Nếu chúng tôi lấy bất kỳ tập dữ liệu hoặc tổng thể nào và bắt đầu lấy mẫu từ tổng thể, giả sử chúng tôi lấy 10 mẫu và lấy giá trị trung bình của các mẫu đó, và chúng tôi tiếp tục thực hiện việc này, một vài lần, chẳng hạn như 1000 lần, sau khi thực hiện việc này, chúng ta có 1000 phương tiện và khi vẽ đồ thị, chúng ta nhận được một phân phối được gọi là phân phối lấy mẫu của các phương tiện mẫu. Phân phối lấy mẫu này (ít nhiều) tuân theo phân phối chuẩn! Đây là định lý Giới hạn trung tâm. Phân phối chuẩn có một số đặc tính hữu ích cho việc phân tích. Hình 1 Phân phối mẫu của phương tiện mẫu (theo phân phối chuẩn) Thuộc tính của phân phối chuẩn: Giá trị trung bình, mốt và trung vị đều bằng nhau. 68% dữ liệu nằm trong một độ lệch chuẩn so với giá trị trung bình. 95% dữ liệu nằm trong hai độ lệch chuẩn của giá trị trung bình. Đường cong đối xứng ở tâm (tức là xung quanh giá trị trung bình, μ). Hơn nữa, giá trị trung bình của phân phối mẫu của phương tiện mẫu bằng với giá trị trung bình của tổng thể. Nếu μ là trung bình tổng thể và μX̅ là trung bình của mẫu, có nghĩa là: Hình 2 trung bình dân số = trung bình mẫu Và độ lệch chuẩn của tổng thể(σ) có mối quan hệ sau với phân bố lấy mẫu độ lệch chuẩn (σX̅): Nếu σ là độ lệch chuẩn của dân số và σX̅ là độ lệch chuẩn của trung bình mẫu và n là cỡ mẫu, thì chúng ta có Hình 3. Mối quan hệ giữa độ lệch chuẩn tổng thể và độ lệch chuẩn phân phối mẫu Trực giác Vì chúng ta lấy nhiều mẫu từ tổng thể nên giá trị trung bình sẽ bằng (hoặc gần) với trung bình thực tế của tổng thể thường xuyên hơn không. Do đó, chúng ta có thể mong đợi một đỉnh (chế độ) trong phân phối lấy mẫu của phương tiện mẫu bằng với giá trị trung bình tổng thể thực tế. Nhiều mẫu ngẫu nhiên và giá trị trung bình của chúng sẽ nằm xung quanh giá trị trung bình của tổng thể thực tế. Do đó, chúng ta có thể giả định 50% phương tiện sẽ lớn hơn trung bình tổng thể và 50% sẽ nhỏ hơn mức đó (trung vị). Nếu chúng ta tăng cỡ mẫu (từ 10 lên 20 lên 30), thì ngày càng nhiều giá trị trung bình của mẫu sẽ tiến gần đến giá trị trung bình của tổng thể. Do đó, giá trị trung bình (trung bình) của các phương tiện đó ít nhiều phải giống với giá trị trung bình của tổng thể. Hãy xem xét trường hợp cực đoan khi kích thước mẫu bằng kích thước tổng thể. Vì vậy, đối với mỗi mẫu, giá trị trung bình sẽ bằng với giá trị trung bình của tổng thể. Đây là phân bố hẹp nhất (độ lệch chuẩn của phương tiện mẫu, ở đây là 0). Do đó, khi chúng ta tăng cỡ mẫu (từ 10 lên 20 lên 30), độ lệch chuẩn sẽ có xu hướng giảm (vì độ chênh lệch trong phân bổ mẫu sẽ bị hạn chế và nhiều phương tiện mẫu sẽ tập trung vào giá trị trung bình của tổng thể). Hiện tượng này được thể hiện trong công thức ở "Hình 3" trong đó độ lệch chuẩn của phân bố mẫu tỷ lệ nghịch với căn bậc hai của cỡ mẫu. Nếu chúng ta lấy ngày càng nhiều mẫu (từ 1.000 đến 5.000 đến 10.000), thì phân bố lấy mẫu sẽ là một đường cong mượt mà hơn vì nhiều mẫu sẽ hoạt động theo định lý giới hạn trung tâm và mẫu sẽ rõ ràng hơn. "Nói chuyện là rẻ, cho tôi xem mã!" - Linus Torvalds Vì vậy, hãy mô phỏng định lý giới hạn trung tâm thông qua mã: Một số hàng nhập khẩu: import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math Tạo một quần thể bằng cách sử dụng . Bạn có thể thử các bản phân phối khác nhau để tạo dữ liệu. Đoạn mã sau tạo ra một (loại) phân phối giảm dần đơn điệu: random.randint() def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population Tạo mẫu và lấy số lần trung bình của chúng: sample_count def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list Chức năng vẽ đồ thị phân bố dữ liệu cùng với một số nhãn. def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show() Chức năng chính để chạy code: def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True) Bạn có thể tìm thấy toàn bộ mã . ở đây trên GitHub Người giới thiệu: Định lý giới hạn trung tâm đang hoạt động Định lý giới hạn trung tâm: ứng dụng thực tế Giới thiệu Định lý giới hạn trung tâm Giới thiệu nhẹ nhàng về Định lý giới hạn trung tâm cho học máy Định lý giới hạn trung tâm Tín dụng ảnh bìa: Casey Dunn & Creature Cast trên Vimeo Đề xuất đọc (Video được đề xuất): khanacademy/định lý giới hạn trung tâm Thống kê khoa học dữ liệu học máy Cũng được xuất bản ở đây