
5,724 ریڈنگز
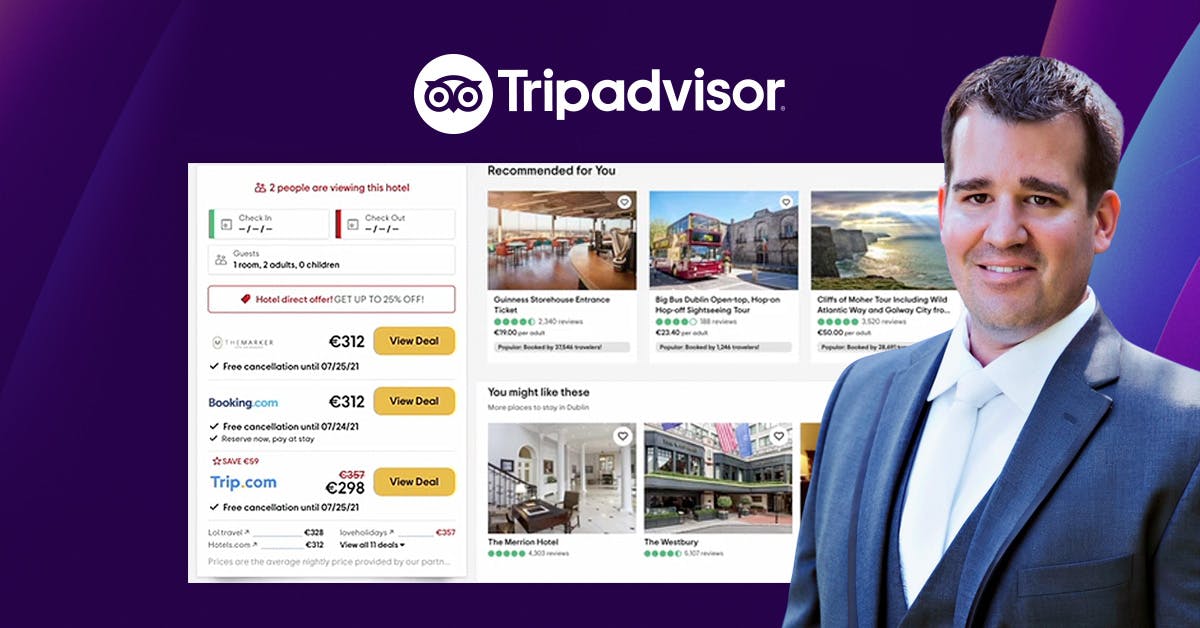
کس طرح Tripadvisor ML کے ساتھ مقیاس میں حقیقی وقت کی خصوصیات فراہم کرتا ہے
by
2025/07/22





































































Story's Credibility


Story's Credibility
About Author

Monstrously Fast + Scalable NoSQL. Start Fast. Scale Fearlessly
تبصرے

Monstrously Fast + Scalable NoSQL. Start Fast. Scale Fearlessly











