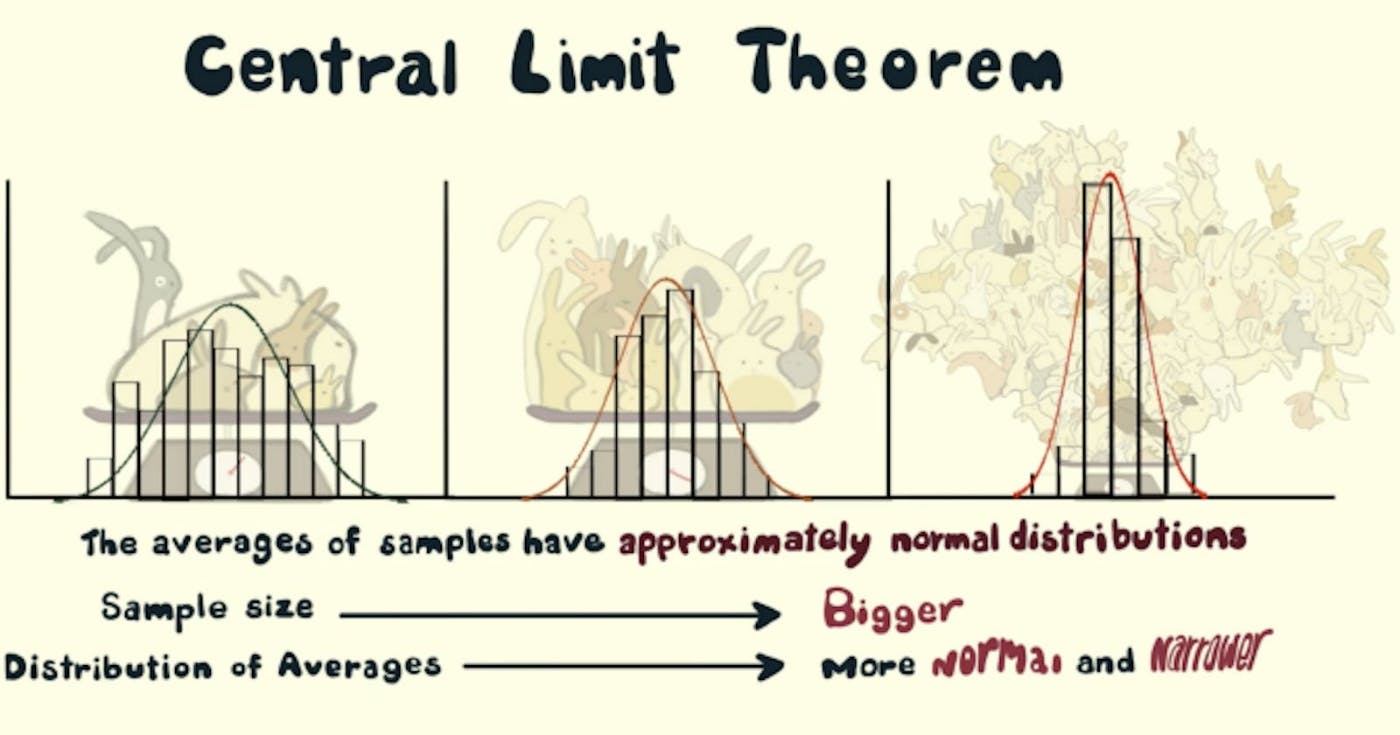
Tanım, Önem ve Uygulamalar TLDR: Kodun tamamını bulabilirsiniz. GitHub'da Merkezi Limit Teoremi aşağıdaki olguyu yakalar: Herhangi bir dağıtımı alın! (bir futbol maçındaki pas sayısının dağılımı diyelim) Bu dağılımdan (n = 5 diyelim) birden çok kez [m = 1000 diyelim] kez n numune almaya başlayın. Her örnek kümesinin ortalamasını alın (böylece m = 1000 ortalamaya sahip oluruz) Araçların dağılımı (az ya da çok) . (Ortalamaları x eksenine, frekanslarını da y eksenine çizerseniz o meşhur çan eğrisini elde edersiniz.) normal şekilde dağıtılacaktır Daha küçük bir standart sapma elde etmek için n'yi artırın ve normal dağılıma daha iyi bir yaklaşım elde etmek için m'yi artırın. Ama Neden Umursamalıyım? İşleme için tüm verileri yükleyemiyor musunuz? Sorun değil, verilerden birden fazla örnek alın ve ortalama, standart sapma, toplam vb. veri parametrelerini tahmin etmek için merkezi limit teoremini kullanın. Zaman ve para açısından kaynaklardan tasarruf etmenizi sağlayabilir. Çünkü artık popülasyondan çok daha küçük örnekler üzerinde çalışabiliyor ve tüm popülasyon için çıkarımlar yapabiliyoruz! Belirli bir örnek belirli bir popülasyona (veya bir veri kümesine) ait mi? Örnek ortalamasını, popülasyon ortalamasını, örnek standart sapmasını ve popülasyon standart sapmasını kullanarak bunu kontrol edelim. Tanım Bilinmeyen bir dağılıma sahip bir veri seti verildiğinde (tekdüze, iki terimli veya tamamen rastgele olabilir), örnek ortalama normal dağılıma yaklaşacaktır. Açıklama Herhangi bir veri seti veya popülasyon alırsak ve popülasyondan örnekler almaya başlarsak, diyelim ki 10 örnek alıyoruz ve bu örneklerin ortalamasını alıyoruz ve bunu birkaç kez, diyelim 1000 kez yapmaya devam ediyoruz, bunu yaptıktan sonra, 1000 ortalama elde ediyoruz ve bunu çizdiğimizde örnek ortalamaların örnekleme dağılımı adı verilen bir dağılım elde ediyoruz. Bu örnekleme dağılımı (az ya da çok) normal bir dağılım izliyor! Bu Merkezi Limit teoremidir. Normal bir dağılımın analiz için yararlı olan bir takım özellikleri vardır. Şekil 1 Örnek ortalamalarının örnekleme dağılımı (normal dağılıma göre) Normal dağılımın özellikleri: Ortalama, mod ve medyanın hepsi eşittir. Verilerin %68'i ortalamanın bir standart sapması dahilindedir. Verilerin %95'i ortalamanın iki standart sapması dahilindedir. Eğri merkezde simetriktir (yani ortalama μ civarında). Ayrıca, örnek ortalamalarının örnekleme dağılımının ortalaması, popülasyon ortalamasına eşittir. μ popülasyon ortalaması ve μX̅ numunenin ortalaması ise bu şu anlama gelir: Şekil 2 popülasyon ortalaması = örnek ortalaması Ve popülasyonun standart sapması (σ), standart sapma örnekleme dağılımı (σX̅) ile aşağıdaki ilişkiye sahiptir: Eğer σ popülasyonun standart sapması ve σX̅ örneklem ortalamalarının standart sapması ve n örneklem büyüklüğü ise, o zaman şunu elde ederiz: Şekil 3 Popülasyon standart sapması ile örnekleme dağılımı standart sapması arasındaki ilişki Sezgi Popülasyondan birden fazla örnek aldığımız için ortalamalar çoğu zaman gerçek popülasyon ortalamasına eşit (veya ona yakın) olacaktır. Bu nedenle, örnek ortalamalarının örnekleme dağılımında gerçek popülasyon ortalamasına eşit bir tepe noktası (mod) bekleyebiliriz. Çoklu rastgele örnekler ve bunların ortalamaları, gerçek popülasyon ortalamasının etrafında yer alacaktır. Dolayısıyla, ortalamaların %50'sinin popülasyon ortalamasından daha büyük ve %50'sinin bundan (medyan) daha az olacağını varsayabiliriz. Örnek boyutunu arttırırsak (10'dan 20'ye, 30'a), giderek daha fazla örnek ortalaması popülasyon ortalamasına yaklaşacaktır. Bu nedenle, bu ortalamaların ortalaması (ortalaması), nüfus ortalamasına az çok benzer olmalıdır. Örneklem büyüklüğünün popülasyon büyüklüğüne eşit olduğu uç durumu düşünün. Yani her örnek için ortalama, popülasyon ortalamasıyla aynı olacaktır. Bu en dar dağılımdır (örnek ortalamalarının standart sapması, burada 0'dır). Bu nedenle, örneklem büyüklüğünü arttırdıkça (10'dan 20'ye, 30'a) standart sapma azalma eğiliminde olacaktır (çünkü örnekleme dağılımındaki yayılma sınırlı olacaktır ve örnek ortalamalarının daha fazlası popülasyon ortalamasına odaklanacaktır). Bu olgu, numune dağılımının standart sapmasının numune boyutunun karekökü ile ters orantılı olduğu "Şekil 3"teki formülde yansıtılmaktadır. Eğer daha fazla örnek alırsak (1.000'den 5.000'e, 10.000'e), o zaman örnekleme dağılımı daha düzgün bir eğri olur çünkü daha fazla örnek merkezi limit teoremine göre davranır ve model daha temiz olur. "Konuşmak Ucuz, Bana Kodu Göster!" - Linus Torvalds O halde merkezi limit teoremini kod aracılığıyla simüle edelim: Bazı İthalatlar: import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math kullanarak bir popülasyon oluşturun. Veri oluşturmak için farklı dağıtımları deneyebilirsiniz. Aşağıdaki kod (bir nevi) monoton olarak azalan bir dağılım oluşturur: random.randint() def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population Örnekler oluşturun ve bunların ortalama sayısını alın: sample_count def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list Bazı etiketlerle birlikte veri dağılımını çizme işlevi. def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show() Kodu çalıştırmak için ana işlev: def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True) Kodun tamamını bulabilirsiniz. GitHub'da Referanslar: Merkezi Limit Teoremi Uygulamada Merkezi Limit Teoremi: gerçek hayattaki bir uygulama Merkezi Limit Teoremine Giriş Makine Öğrenimi için Merkezi Limit Teoremine Nazik Bir Giriş Merkezi Limit Teoremi Kapak Resmi Kredisi: Casey Dunn ve Yaratık Oyuncusu on Vimeo Önerilen Okuma (Önerilen Videolar): khanacademy/merkezi limit teoremi Makine Öğrenimi Veri Bilimi istatistikleri da yayınlandı Burada