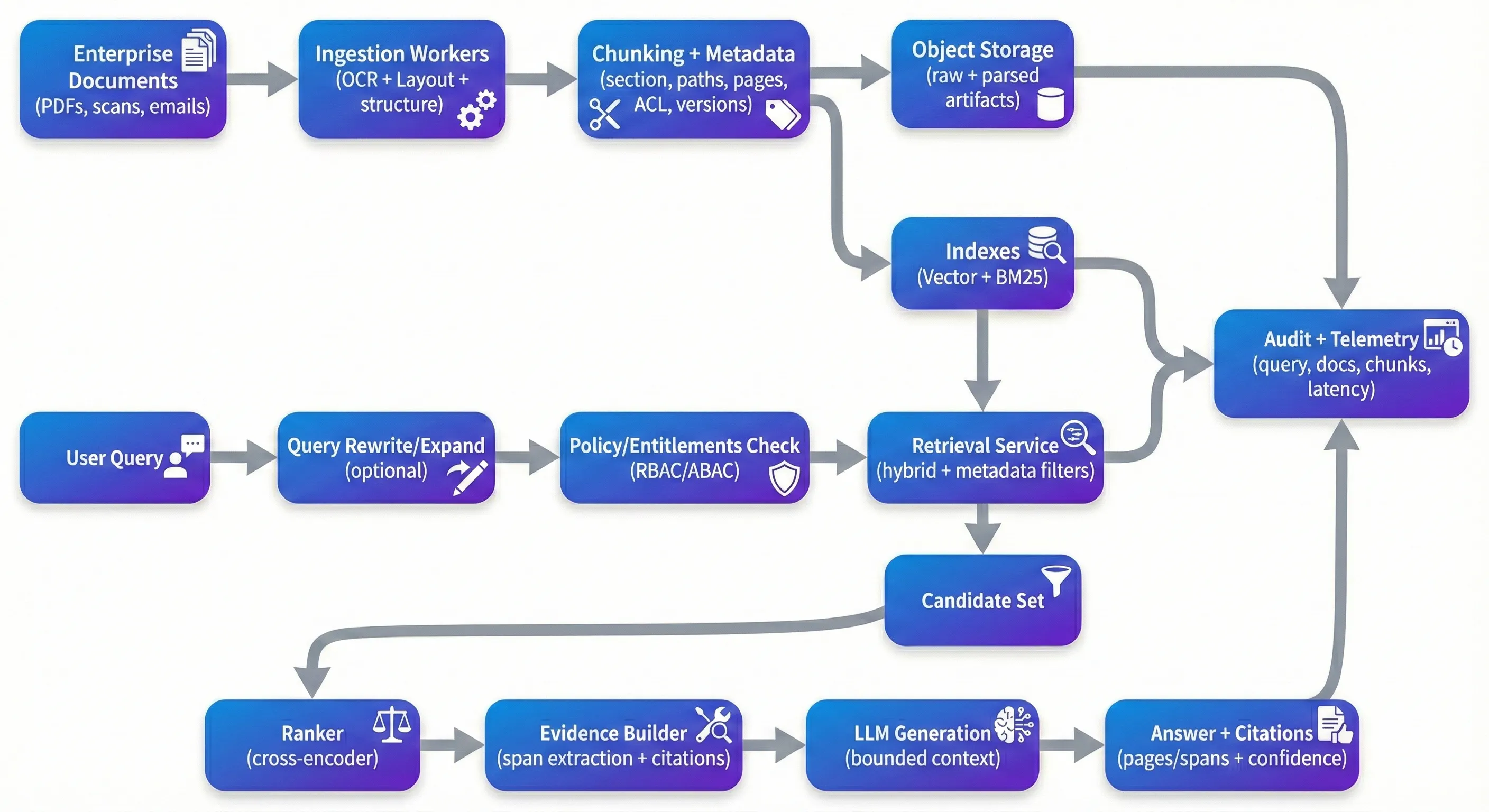
RAG есть повсюду — и это не удивительно. Это один из самых практичных способов сделать большие коллекции документов спрашиваемыми без создания хрупких, специфических для домена аналитиков для каждого типа вопросов. Уловка заключается в том, что то, что работает в контролируемом демо, часто быстро деградирует, когда вы ставите его перед реальными корпоративными PDF-файлами: сканированные контракты, документы о соответствии, медицинские записи, политики и длинный хвост проблем с оформлением и качеством, которые приходят с ними. Когда команды застряют, это редко происходит потому, что векторный поиск «не работает». Это потому, что система не может последовательно основывать ответы на правильные доказательства, не может надежно применять права, или не может быть оценена и улучшена, не нарушая вещи. Если вы не можете сказать заинтересованной стороне, какая версия документа поддерживала требование — или доказать, что пользователь был уполномочен видеть его — у вас еще нет продукта. The Demo Trap Демо ловушка Большинство прототипов следуют тому же пути: бросают документы в векторный магазин, получают верхние кусочки и просят LLM синтезировать. На чистом, хорошо структурированном тексте это может выглядеть отлично. Проблема в том, что происходит дальше. Сканированные PDF-файлы приходят в повороте или искажении. Порядок чтения в нескольких столбцах скручивается. Таблицы теряют структуру во время извлечения. Чунки разделяют середину аргумента. Получение возвращает «достаточно близкий» контекст, который читает правдоподобно, но на самом деле не поддерживает утверждение. И модель, делая то, что оптимизировано для этого, отвечает плавно в любом случае. В производстве вы оптимизируете для различных свойств, чем демонстрация.Вы хотите, чтобы система была надежной над беспорядочными вводами, воспроизводимой через изменения трубопровода, и защищаемой под контролем. Это означает, что вы можете отслеживать ответ обратно к конкретным доказательствам, и иметь сильные по умолчанию, когда доказательства слабы: разъясняя вопросы, отказ поведение, или представляя «лучшие доступные доказательства» с явной неопределенностью. Ingestion: Where Quality Is Won or Lost Поглощение: где качество выигрывается или теряется Если вы построили несколько из этих систем, вы быстро узнаете, что поглощение определяет качество извлечения больше, чем большинство последующих трюков. Предварительная обработка документов ИИ не очаровательна, но это место, где вы либо сохраняете структуру, либо потеряете ее навсегда. Для корпоративных документов ОКР в одиночку недостаточно; вам обычно нужны ОКР с обнаружением расположения, реконструкцией порядка чтения и экстракцией структуры, которая держит заголовки, разделы и таблицы значимыми. Управляемые инструменты, такие как Google Document AI, Azure Document Intelligence и Amazon Textract, могут покрывать много земли. Чункинг - это место, где команды часто недооценивают сложность. Простой характер или раздел токенов происходит быстро, но он имеет тенденцию пересекать семантические границы - именно границы, о которых заботятся пользователи в контрактах и политиках. Адаптивный чункинг, который следует за заголовками, границами разделов и границами таблиц, обычно улучшает как восстановление, так и заземление вниз. Он также делает происхождение естественным для конечного пользователя: вместо того, чтобы выставлять непрозрачный внутренний идентификатор, как chunk_4892, вы можете указать на то, что рецензент может немедленно проверить - "MSA v3.2 → Раздел 9 (Окончание) → 9.2 (Окончание для Причины), страница 12, стро Метаданные являются еще одной областью, которая имеет тенденцию выглядеть дополнительно до тех пор, пока вам не понадобится. На практике, метаданные являются тем, что делает фильтрацию, отслеживаемость и воспроизводимость возможными. Полезные метаданные на уровне частей обычно включают идентификаторы документов, пути раздела, номера страниц, временные отметки (действительная дата, последняя модификация, введенная в), сигналы доверия к экстракции и идентификаторы версий (хэш-документ, шунки-версия, встраиваемая версия модели). В корпоративных контекстах атрибуты контроля доступа (наниматель, отдел, конфиденциальность, теги роли) должны быть первоклассными, потому что они напрямую ограничивают поиск и The Retrieval Stack That Actually Works Восстановление стек, который действительно работает На практике гибридное извлечение — плотные встраивания плюс скудные лексические извлечения, такие как BM25 — имеет тенденцию быть более прочным, особенно когда пользователи задают запросы с номерами пунктов, идентификаторами, аббревиатурами или точными фразами. Переоценка часто заключается в том, что системы делают наибольший скачок в воспринимаемом качестве, не потому, что это волшебство, а потому, что это фиксирует общий режим неудачи: первоначальный набор поиска содержит "кинда-релевантные" частички, и вам нужно продвигать действительно релевантные частицы вверх. Переоценки кросс-кодера (открытые модели, такие как bge-reranker или управляемые API, такие как Cohere ranker) переоценивают частицы кандидатов с помощью более глубокого взаимодействия запроса и прохода. Команды обычно видят заметный подъем в контекстной точности, когда переоценка измеряется должным образом (например, на золотом наборе с ожидаемыми источниками). Перезапись запросов и расширение является еще одним рычагом, который легко пропустить раньше, а затем снова открыть позже. Пользователи естественным образом не задают вопросы так, как пишутся документы. Шаг перезаписи может расширить аббревиатуры, нормализовать субъекты и разделить многочасовые вопросы на подзапросы, удобные для поиска. Security: The Layer Everyone Forgets Безопасность: слой, о котором все забывают Most RAG demos ignore access control because it slows down the prototype. In production, it’s a primary constraint. If your system indexes HR documents, legal contracts, and engineering specs together, you need a deterministic entitlement path from user → allowed chunks, and retrieval must be constrained by that path before any content reaches an LLM. Модель, которая имеет тенденцию к масштабированию, является предварительно отфильтрованным поиском: вычислительные права (RBAC/ABAC), извлечение только из кусков с совместимыми атрибутами ACL, перенастройка в разрешенном наборе кандидатов и запись того, какие доказательства были доступны. Помимо ACL, корпоративные развертывания обычно требуют некоторого сочетания обнаружения / маскировки PII, шифрования в покое, краткосрочных токенов для доступа к источнику и записи аудита, которые захватывают запросы, извлеченные частичные идентификаторы, цитаты и версии документов. Еще одна современная проблема, которую стоит серьезно рассмотреть, - это быстрое впрыскивание контента внутри документов. Monitoring: Closing the Loop Мониторинг: закрытие цепи Если вы эксплуатируете одну из этих систем более нескольких недель, вы увидите дрейф. Документы изменяются, распределение запросов изменяется, трубопровод поглощения изменяется, а компоненты модели обновляются. Практически, вы хотите отслеживать здоровье восстановления (recall@k против золотого набора, точность контекста, реранкер-лифт), здоровье генерации (точность цитирования, проверки заземления/верности, показатели отказов) и оперативное здоровье (p50/p95 задержка, стоимость за запрос, задержка потребления от обновления документа до индекса, который можно найти).Самые эффективные команды, которые я видел, поддерживают золотой набор данных оценки — исправленные вопросы с ожидаемыми исходными документами — и запускают его по графику и по изменениям событий (новые встраивания, новая хроническая логика, новые партии документов). Инструменты, такие как Phoenix, TruLens или коммерческие платформы могут помочь, но более крупный дифференциатор Одной из областей, которую часто недооценивают, является версирование и воспроизводимость.Когда вы меняете модели OCR, выкручиваете логику, встраиваете модели, реранкеры или просьбы о генерации, вам нужен способ отследить, какие версии были выпущены, какие ответы. Choosing Your Stack Выбираем свой стек Для многих команд привлекательна управляемая настройка: поглощение с помощью управляемого инструмента Document AI или трубопровода на основе Unstructured, хостированная векторная база данных, слой оркестрации, такой как LlamaIndex или LangChain, и реранкер (открытый или управляемый). Другие предпочитают развертывание с открытым исходным кодом с использованием Qdrant/Weaviate/OpenSearch, Haystack или аналогичной оркестрации, а также автономные модели для контроля и предсказуемости затрат. Любой подход может работать, если он поддерживает основы: осознанное поглощение документов, гибридное восстановление, правоприменительное обеспечение, дружественные к происхождению цитаты, оценочные трубопроводы и версифика С архитектурной стороны, системы, как правило, становятся более простыми в работе, когда они разделяются четко: работники поглощения, которые работают асинхронно и могут быть безопасно перезагружены; служба получения без государства, которая обеспечивает политику и возвращает доказательства; и служба генерации, которая работает с ограниченным контекстом и четким происхождением.