
5,724 чтения
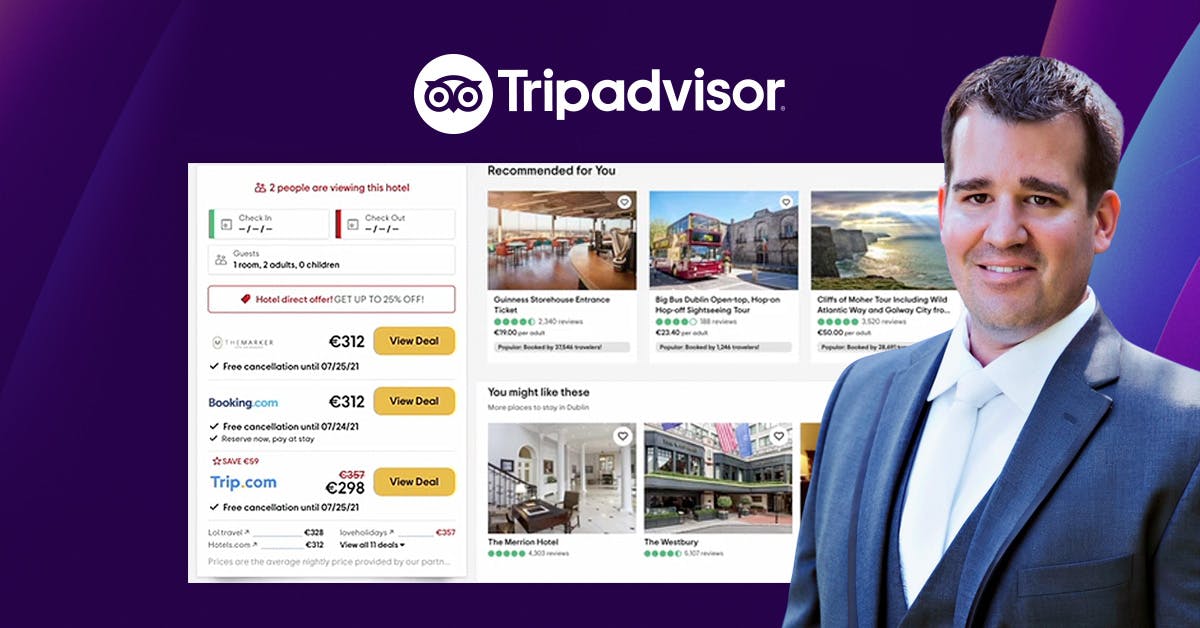
Как TripAdvisor предоставляет персонализацию в режиме реального времени в масштабе с помощью ML
by
2025/07/22





































































Story's Credibility


Story's Credibility
About Author

Monstrously Fast + Scalable NoSQL. Start Fast. Scale Fearlessly
КОММЕНТАРИИ












