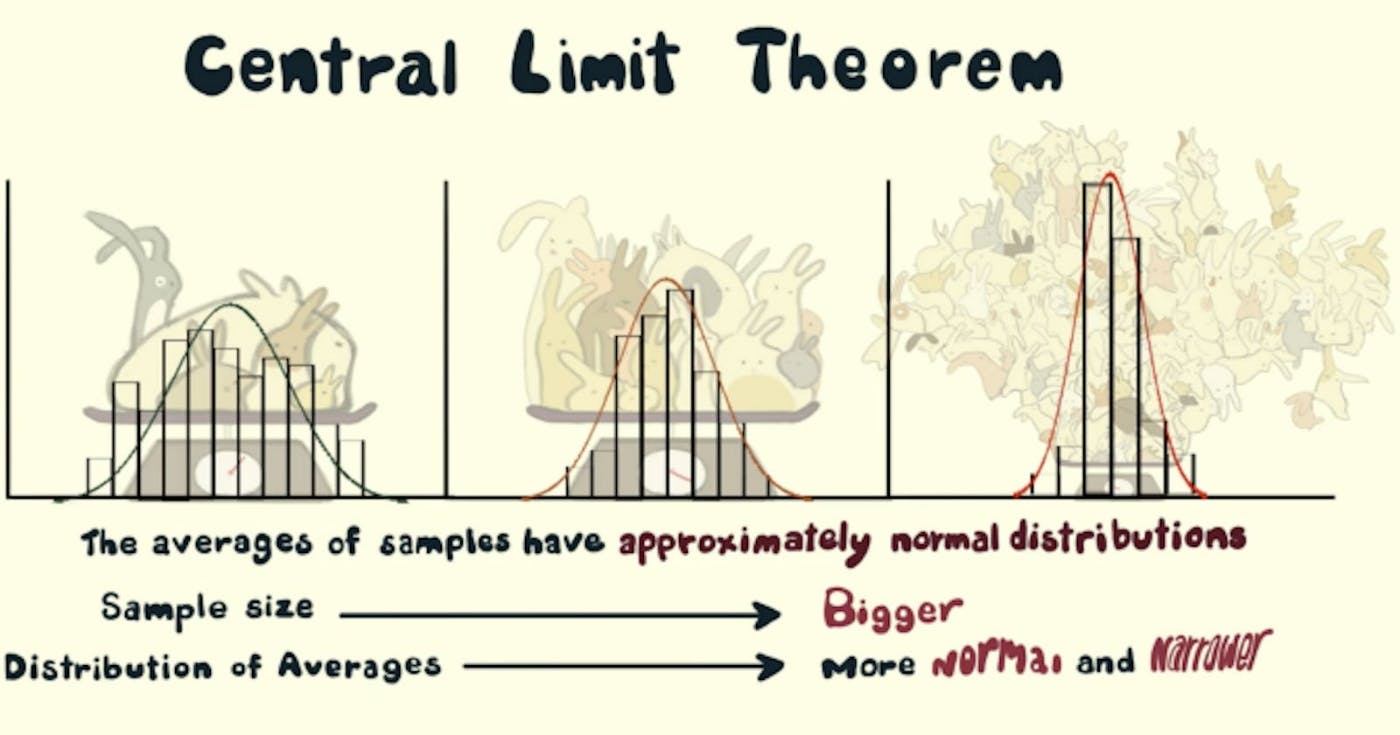
정의, 의의 및 적용 주요 내용: 전체 코드를 찾을 수 있습니다. 여기 GitHub에서 중심 극한 정리는 다음 현상을 포착합니다. 배포판을 받아보세요! (예를 들어 축구 경기에서 패스 횟수의 분포) 해당 분포(예: n = 5)에서 여러 번(예: m = 1000) n 샘플을 추출하기 시작합니다. 각 샘플 세트의 평균을 취합니다(따라서 m = 1000 평균이 됩니다). 수단의 분포는 (다소) 따릅니다. (x축에 평균을, y축에 빈도를 표시하면 유명한 종형 곡선을 얻을 수 있습니다.) 정규 분포를 더 작은 표준 편차를 얻으려면 n을 늘리고 정규 분포에 대한 더 나은 근사치를 얻으려면 m을 늘리십시오. 그런데 왜 관심을 가져야 합니까? 처리를 위해 전체 데이터를 로드할 수 없습니까? 문제 없습니다. 데이터에서 여러 샘플을 추출하고 중심 극한 정리를 사용하여 평균, 표준 편차, 합계 등과 같은 데이터 매개변수를 추정합니다. 시간과 비용 측면에서 리소스를 절약할 수 있습니다. 이제 모집단보다 훨씬 작은 표본을 사용하여 전체 모집단에 대한 추론을 도출할 수 있기 때문입니다! 특정 표본이 특정 모집단(또는 데이터 세트)에 속합니까? 표본평균, 모집단평균, 표본표준편차, 모집단표준편차를 이용하여 확인해 보겠습니다. 정의 알 수 없는 분포(균일, 이항 또는 완전히 무작위일 수 있음)가 있는 데이터세트가 주어지면 표본 평균은 정규 분포에 가까워집니다. 설명 데이터세트나 모집단을 선택하고 모집단에서 표본을 추출하기 시작한다고 가정해 보겠습니다. 10개의 표본을 채취하여 그 표본의 평균을 구하고 이 작업을 몇 번, 예를 들어 1000번 정도 계속한다고 가정해 보겠습니다. 1000개의 평균을 얻고 이를 플롯하면 표본 평균의 샘플링 분포라는 분포를 얻습니다. 이 샘플링 분포는 (다소간) 정규 분포를 따릅니다! 이것이 중심극한정리이다. 정규 분포에는 분석에 유용한 여러 가지 속성이 있습니다. 그림 1 표본 평균의 표본 분포(정규 분포를 따름) 정규 분포의 속성: 평균, 최빈값, 중앙값이 모두 동일합니다. 데이터의 68%가 평균의 1표준편차 내에 속합니다. 데이터의 95%가 평균의 2표준편차 내에 속합니다. 곡선은 중앙에서 대칭입니다(즉, 평균 μ를 중심으로). 또한, 표본평균의 표본분포 평균은 모집단 평균과 같습니다. μ가 모집단 평균이고 μX̅가 표본의 평균인 경우 다음을 의미합니다. 그림 2 모집단 평균 = 표본 평균 그리고 모집단의 표준편차(σ)는 표준편차 표본분포(σX̅)와 다음과 같은 관계를 갖습니다. σ가 모집단의 표준편차이고 σX̅가 표본평균의 표준편차이고 n이 표본 크기라면 다음과 같습니다. 그림 3 모집단 표준편차와 표본분포 표준편차의 관계 직관 모집단에서 여러 개의 표본을 추출하기 때문에 평균은 실제 모집단 평균과 같거나 가까운 경우가 많습니다. 따라서 표본 평균의 표본 분포에서 실제 모집단 평균과 동일한 피크(모드)를 기대할 수 있습니다. 여러 무작위 표본과 그 평균은 실제 모집단 평균 주위에 있습니다. 따라서 평균의 50%는 모집단 평균보다 크고 50%는 모집단 평균보다 작을 것이라고 가정할 수 있습니다(중앙값). 표본 크기를 10에서 20에서 30으로 늘리면 점점 더 많은 표본 평균이 모집단 평균에 가까워집니다. 따라서 해당 평균의 평균(평균)은 모집단 평균과 어느 정도 유사해야 합니다. 표본 크기가 모집단 크기와 동일한 극단적인 경우를 생각해 보십시오. 따라서 각 표본의 평균은 모집단 평균과 같습니다. 이는 가장 좁은 분포입니다(표본 평균의 표준 편차, 여기서는 0임). 따라서 표본 크기를 늘리면(10에서 20에서 30으로) 표준 편차가 감소하는 경향이 있습니다(표본 분포의 산포가 제한되고 더 많은 표본 평균이 모집단 평균에 집중되기 때문입니다). 이 현상은 표본 분포의 표준 편차가 표본 크기의 제곱근에 반비례하는 "그림 3"의 공식으로 표현됩니다. 점점 더 많은 샘플(1,000에서 5,000, 10,000)을 취하면 더 많은 샘플이 중심 극한 정리에 따라 동작하고 패턴이 더 깨끗해지기 때문에 샘플링 분포는 더 부드러운 곡선이 됩니다. "말은 싸다, 코드를 보여줘!" - 리누스 토발즈 이제 코드를 통해 중심 극한 정리를 시뮬레이션해 보겠습니다. 일부 수입품: import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math 사용하여 모집단을 만듭니다. 다양한 분포를 시도하여 데이터를 생성할 수 있습니다. 다음 코드는 (일종의) 단조 감소 분포를 생성합니다. random.randint() def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population 샘플을 생성하고 평균 횟수를 취합니다. sample_count def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list 일부 레이블과 함께 데이터 분포를 그리는 기능입니다. def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show() 코드를 실행하는 주요 기능은 다음과 같습니다. def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True) 전체 코드를 찾을 수 있습니다. 여기 GitHub에서 참고자료: 중심 극한 정리의 실제 사례 중심극한정리: 실제 적용 중심 극한 정리 소개 기계 학습을 위한 중심 극한 정리에 대한 간단한 소개 중심 극한 정리 표지 이미지 크레딧: Casey Dunn & Creature Cast on Vimeo 추천 도서(추천 동영상): khanacademy/중심극한정리 기계 학습 데이터 과학 통계 게시됨 여기에도