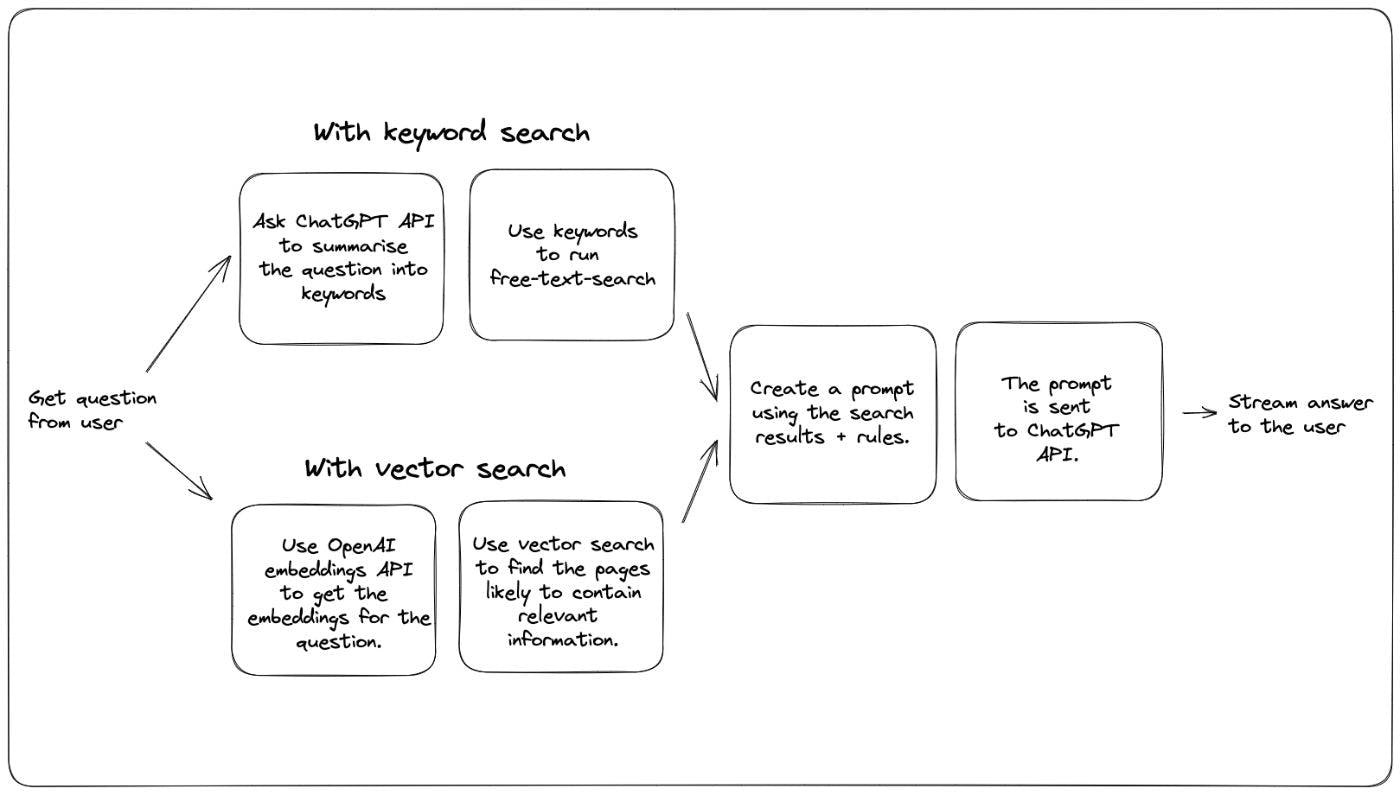
지난 주에 우리는 의 질문에 답변하는 Q&A 봇을 추가했습니다. 이는 OpenAI GPT 모델이 Xata 문서에서 교육받은 적이 없더라도 ChatGPT 기술을 활용하여 Xata 문서의 질문에 답합니다. 문서 이를 수행하는 방법은 이 에서 Simon Willison이 제안한 접근 방식을 사용하는 것입니다. 에서도 동일한 접근 방식을 찾을 수 있습니다. 아이디어는 다음과 같습니다. 블로그 게시물 OpenAI 요리책 문서에 대해 텍스트 검색을 실행하여 사용자가 묻는 질문과 가장 관련성이 높은 콘텐츠를 찾으세요. 다음과 같은 일반 형식으로 프롬프트를 생성합니다. With these rules: {rules} And this text: {context} Given the above text, answer the question: {question} Answer: ChatGPT API에 프롬프트를 보내고 모델이 답변을 완료하도록 합니다. 우리는 이것이 매우 잘 작동한다는 것을 알았으며 상대적으로 낮은 모델 온도(온도의 개념은 이 에 설명되어 있음)와 결합되어 답변을 찾을 수 있는 한 올바른 결과와 코드 조각을 생성하는 경향이 있습니다. 선적 서류 비치. 블로그 게시물 이 접근 방식의 주요 제한 사항은 위의 두 번째 단계에서 빌드하는 프롬프트에 최대 4000개의 토큰(~3000단어)이 있어야 한다는 것입니다. 이는 가장 관련성이 높은 문서를 선택하기 위한 첫 번째 단계인 텍스트 검색이 정말 중요해진다는 것을 의미합니다. 검색 단계가 제대로 작동하고 올바른 컨텍스트를 제공하는 경우 ChatGPT는 정확하고 요점이 분명한 결과를 생성하는 데에도 좋은 역할을 하는 경향이 있습니다. 그렇다면 문서에서 가장 관련성이 높은 콘텐츠를 찾는 가장 좋은 방법은 무엇입니까? OpenAI 요리책과 Simon의 블로그는 의미론적 검색을 사용합니다. 의미 체계 검색은 언어 모델을 활용하여 질문과 콘텐츠 모두에 대한 임베딩을 생성합니다. 임베딩은 여러 차원의 텍스트를 나타내는 숫자 배열입니다. 유사한 임베딩을 가진 텍스트 조각은 비슷한 의미를 갖습니다. 이는 좋은 전략이 질문 임베딩과 가장 유사한 임베딩이 있는 콘텐츠 조각을 찾는 것임을 의미합니다. 보다 고전적인 키워드 검색을 기반으로 하는 또 다른 가능한 전략은 다음과 같습니다. 다음과 같은 프롬프트를 사용하여 ChatGPT에 질문에서 키워드를 추출하도록 요청하세요. Extract keywords for a search query from the text provided. Add synonyms for words where a more common one exists. 제공된 키워드를 사용하여 자유 텍스트 검색을 실행하고 상위 결과를 선택하세요. 단일 다이어그램으로 표현하면 두 가지 방법은 다음과 같습니다. 우리는 문서에서 두 가지를 모두 시도했고 몇 가지 장단점을 발견했습니다. 몇 가지 결과를 비교하는 것부터 시작해 보겠습니다. 둘 다 동일한 데이터베이스에 대해 실행되며 둘 다 ChatGPT 모델을 사용합니다. 무작위성이 포함되어 있으므로 각 질문을 2~3회 실행하고 가장 좋은 결과처럼 보이는 것을 선택했습니다. gpt-3.5-turbo 질문: Xata CLI를 어떻게 설치합니까? 벡터 검색으로 답변: 키워드 검색으로 답변: : 두 버전 모두 정답을 제공했지만 벡터 검색 버전이 좀 더 완벽합니다. 둘 다 이에 대한 올바른 문서 페이지를 찾았지만 키워드 전략의 경우 하이라이트 기반 휴리스틱이 더 짧은 텍스트 덩어리를 선택한 것 같습니다. 평결 승자: 벡터 검색. 점수: 1-0 질문: Deno에서 Xata를 어떻게 사용하나요? 벡터 검색으로 답변: 키워드 검색으로 답변: 우리 문서의 전용 Deno 페이지를 놓친 벡터 검색에 대한 실망스러운 결과입니다. 다른 Deno 관련 콘텐츠를 찾았지만 매우 유용한 예제가 포함된 페이지는 찾지 못했습니다. 평결: 승자: 키워드 검색. 점수: 1-1 질문: 사용자 정의 열 유형이 포함된 CSV 파일을 어떻게 가져올 수 있나요? 벡터 검색의 경우: 키워드 검색: 둘 다 올바른 페이지를 찾았지만("CSV 파일 가져오기") 키워드 검색 버전이 더 완전한 답변을 얻었습니다. 나는 이것이 우연이 아닌지 확인하기 위해 이것을 여러 번 실행했습니다. 차이점은 텍스트 조각을 선택하는 방식(키워드 검색의 경우 키워드 옆, 벡터 검색의 경우 페이지 시작 부분부터)에서 비롯되는 것 같습니다. 평결: 승자: 키워드 검색. 점수: 1-2 질문: 이메일 열을 기준으로 Users라는 테이블을 필터링하려면 어떻게 해야 합니까? 벡터 검색의 경우: 키워드 검색: 벡터 검색은 ChatGPT가 답변을 구성하는 데 사용할 수 있는 더 많은 예가 있는 "필터링" 페이지를 찾았기 때문에 이 검색에서 더 나은 결과를 얻었습니다. 키워드 검색 답변은 메서드 이름에 "filter" 대신 "query"를 사용하기 때문에 미묘하게 깨졌습니다. 평결: 승자: 벡터 검색. 점수: 2-2 질문: Xata란 무엇입니까? 벡터 검색의 경우: 키워드 검색: 두 답변 모두 꽤 좋기 때문에 이번 답변은 무승부입니다. 두 사람은 답변을 요약하기 위해 서로 다른 페이지를 선택했지만 둘 다 잘 수행했으며 승자를 선택할 수 없습니다. 평결: 점수: 3-3 구성 및 튜닝 다음은 키워드 검색에 사용되는 샘플 Xata 요청입니다. // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "What is Xata?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "If you answer with Markdown snippets, prefer the GitHub flavour.", "Your name is DanGPT" ], "searchType": "keyword", "search": { "fuzziness": 1, "target": [ "slug", { "column": "title", "weight": 4 }, "content", "section", { "column": "keywords", "weight": 4 } ], "boosters": [ { "valueBooster": { "column": "section", "value": "guide", "factor": 18 } } ] } } 그리고 이것이 벡터 검색에 사용되는 것입니다: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "How do I get a record by id?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "Your name is DanGPT" ], "searchType": "vector", "vectorSearch": { "column": "embeddings", "contentColumn": "content", "filter": { "section": "guide" } } } 보시다시피 키워드 검색 버전에는 퍼지 및 부스터 및 열 가중치를 구성하는 더 많은 설정이 있습니다. 벡터 검색은 필터만 사용합니다. 나는 이것을 키워드 검색의 장점이라고 부릅니다. 검색을 조정할 수 있는 다이얼이 더 많아지고 따라서 더 나은 답변을 얻을 수 있습니다. 그러나 이는 더 많은 작업이 필요하며 이러한 조정 없이도 벡터 검색의 결과는 상당히 좋습니다. 우리의 경우에는 문서 검색 기능에 대한 키워드 검색을 이미 조정했습니다. 따라서 반드시 추가 작업이 필요한 것은 아니었고 ChatGPT를 사용하면서 문서와 검색도 개선되었음을 발견했습니다. 또한 Xata는 키워드 검색을 조정하는 데 아주 좋은 UI를 갖고 있으므로 작업을 시작하는 것이 어렵지 않았습니다(이에 대해서는 별도의 블로그 게시물을 계획하고 있습니다). 벡터 검색에 부스터와 열 가중치 등이 없을 이유가 없습니다. 하지만 Xata에는 아직 그런 기능이 없으며 키워드를 만드는 것만큼 쉽게 만드는 다른 솔루션도 없습니다. 검색 튜닝. 그리고 일반적으로 키워드 검색에 대한 선행기술이 더 많지만, 벡터 검색이 따라잡을 가능성이 상당히 높습니다. 지금은 키워드 검색이 승자라고 하겠습니다. 점수: 3-4 편의 우리 문서에는 이미 dog-fooding Xata라는 검색 기능이 있었기 때문에 채팅 봇으로 확장하는 것이 매우 간단했습니다. 이제 Xata는 기본적으로 벡터 검색도 지원하지만 이를 사용하려면 모든 문서 페이지에 임베딩을 추가하고 좋은 청킹 전략을 찾아야 했습니다. 우리는 최소한의 비용으로 텍스트 임베딩을 생성하기 위해 OpenAI 임베딩 API를 사용했습니다. 승자: 키워드 검색 점수 3-5 지연 시간 키워드 검색 접근 방식에는 ChatGPT API에 대한 추가 왕복이 필요합니다. 이로 인해 UI에서 스트리밍되기 시작한 결과에 대기 시간이 추가됩니다. 내 측정에 따르면 약 1.8초의 추가 시간이 추가됩니다. 벡터 검색의 경우: 키워드 검색: 여기서 총 시간과 콘텐츠 다운로드 시간은 생성된 응답의 길이에 따라 달라지므로 관련이 없습니다. 비교하려면 "서버 응답 대기 중" 막대(녹색)를 살펴보세요. 참고: 승자: 벡터 검색 점수: 4-5 비용 키워드 검색 버전은 ChatGPT API에 대한 추가 API 호출을 수행해야 하는 반면, 벡터 검색 버전은 질문과 함께 데이터베이스의 모든 문서에 대한 임베딩을 생성해야 합니다. 많은 문서에 대해 이야기하는 것이 아니라면 이것을 넥타이라고 부를 것입니다. 점수: 5-6 결론 점수가 빡빡해요! 우리의 경우 지금은 키워드 검색을 사용했습니다. 주로 키워드 검색을 조정할 수 있는 방법이 더 많고 그 결과 테스트 질문 세트에 대해 약간 더 나은 답변을 생성하기 때문입니다. 또한 검색에 대한 개선 사항은 검색 및 채팅 사용 사례 모두에 자동으로 도움이 됩니다. 더 많은 조정 옵션을 통해 벡터 검색 기능을 개선하고 있으므로 향후 벡터 검색 또는 하이브리드 접근 방식으로 전환할 수도 있습니다. 자신의 문서 또는 모든 종류의 지식 기반을 위해 유사한 채팅 봇을 설정하려는 경우 Xata 질문 끝점을 사용하여 위의 내용을 쉽게 구현할 수 있습니다. 무료로 에 가입하세요. 개인적으로 귀하가 설정하고 실행하는 데 도움을 드리고 싶습니다! 계정을 만들고 Discord