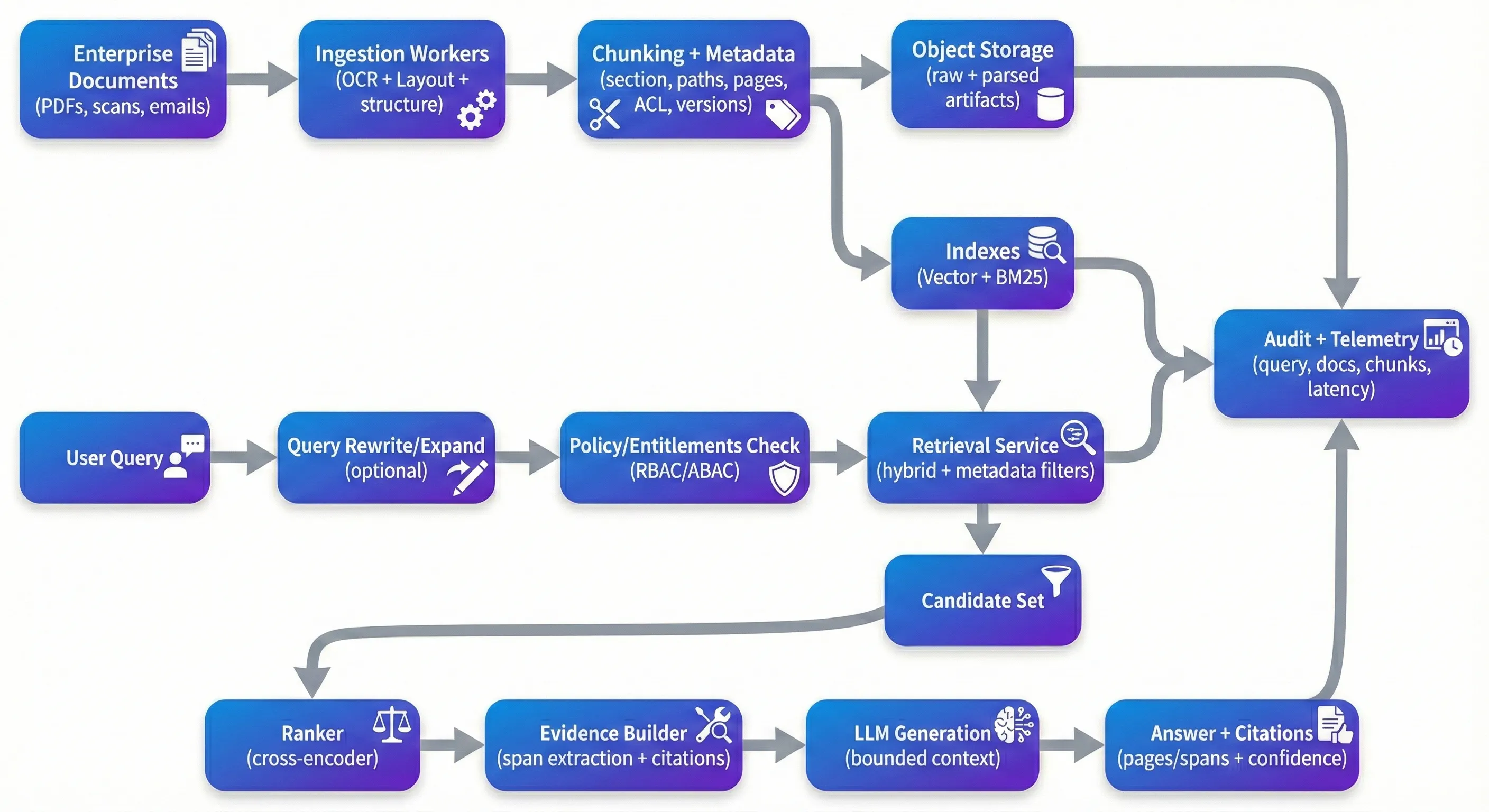
RAG არის ყველა სახის – და ეს არ არის შეუზღუდავი. ეს არის ერთ-ერთი ყველაზე პრაქტიკული გზა, რათა დიდი დოკუმენტის კოლექციები შეამოწმოთ, გარეშე შექმნათ ცუდი, დონეზე სპეციფიკაციური ანზერები თითოეული კითხვის ტიპისთვის. ცუდი არის, რომ ის, რაც მუშაობს კონტროლირებული დომინას, ხშირად სწრაფად შეუზღუდავს, როდესაც თქვენ დააყენებთ რეალური საწარმოო PDFs: სკანირებული კონტაქტები, კონფიდენციალურობის დოკუმენტები, სამედიცინო დოკუმენტები, პოლიტიკა, და ხანგრძლივი კურსი დიზაინი და ხარისხის პრობლემები, რომლებიც მათთან ერთად მოდის. წარმოებისას, "RAG პრობლემა" მას შემდეგ, რაც გუნდი შეჩერდება, ეს rarely იმიტომ, რომ კონტაქტური ეძებს "მე არ მუშაობს." ეს იმიტომ, რომ სისტემა არ შეუძლია მუდმივად დააყენოთ პასუხი სწორი ნომერი, არ შეუძლია საიმედოად მოცულობა, ან არ შეუძლია შეფასება და გააუმჯობესება, გარეშე შეკუმშვის რამ. თუ თქვენ არ შეგიძლიათ გაიგოთ პარტნიორებს, რა ვერსია დოკუმენტი მხარს უჭერს მოთხოვნას - ან უზრუნველყოს, რომ მომხმარებლის გაქირავება - თქვენ არ გაქვთ პროდუქტი. თქვენ გაქვთ ექსპერიმენტი. The Demo Trap Demo ფანჯარა ძირითადად Prototypes იღებს იგივე გზა: დოკუმენტების დატოვება vector store, ჩამოტვირთვა top-k კუნძულები, და გთხოვთ LLM სინთეზი. სუფთა, კარგად სტრუქტურული ტექსტი, რომელიც შეიძლება გამოიყურება შესანიშნავი. პრობლემა არის, რა ხდება შემდეგი. სკანირებული PDFs მოდის rotated ან distorted. Multi-კოლადის წაიკითხვის ბრძანება შეხვდება. ტაბლეები დაკარგავს სტრუქტურა გატოვების დროს. Chunking გატოვებს mid-argument. Retrieval მოგცემს “შემატა საკმარისი” კონტაქტი, რომელიც იხილება რეპუტაცია, მაგრამ ნამდვილად არ მხარს უჭერს. და მოდელი, რაც ის წარმოება, თქვენ გააუმჯობესებთ სხვადასხვა თვისებები, ვიდრე demo. თქვენ გსურთ, რომ სისტემა არის საიმედო შეშფოთებული ინტენსიები, რეპუტაციის მეშვეობით pipeline ცვლილებები, და მხარდაჭერა ქვემოთ შეამოწმება. ეს იმას ნიშნავს, რომ შეუძლიათ წაიკითხოთ პასუხი უკან კონკრეტული ნიმუში, და ძლიერი ნიმუში, როდესაც ნიმუში არის რბილი: გააუმჯობესება კითხვები, უარყოფითი ქცევა, ან წარმოადგენს "ბედნიერი ხელმისაწვდომი ნიმუში" უარყოფითი უარყოფითი. ეს ასევე იმას ნიშნავს, რომ ხელმისაწვდომი კონტროლი, როგორც ნაწილი მოპოვება - არ არის, როგორც ნიმუში Ingestion: Where Quality Is Won or Lost დახურვა: სადაც ხარისხი იღებს ან დაკარგა თუ თქვენ აშენდა რამდენიმე ამ სისტემებს, თქვენ სწრაფად იპოვებთ, რომ ინგლისება უფრო მეტია, ვიდრე ყველაზე downstream tricks. დოკუმენტის AI preprocessing არ არის გემრიელი, მაგრამ ეს არის ადგილი, სადაც თქვენ ან შენარჩუნებთ სტრუქტურა - ან მუდმივად დაკარგავთ. საწარმოო დოკუმენტებისთვის, OCR მხოლოდ არ არის საკმარისი; თქვენ ზოგადად საჭირო OCR- ის მოწყობილობები layout detection, reading-order reconstruction, და სტრუქტურა ექსტრაქცია, რომელიც ხელსაყრელი ხელსაყრელი ზომები, სექციები და ტაბლეები. მართული ინსტრუმენტები, როგორიცაა Google Document AI, Azure Document Intelligence, და Amazon Textract, შეიძლება მოიცავს ბევრი ადგილი Chunking არის ადგილი, სადაც გუნდი ხშირად შეუზღუდავი მოცულობა. მარტივი karakters ან token splitting არის სწრაფი, მაგრამ იგი ხელს უწყობს გადარჩენა სემანტიკური შეზღუდვა – ეს არის მხოლოდ შეზღუდვა მომხმარებელს ხელს უწყობს კონტაქტები და პოლიტიკები. Adaptive chunking, რომელიც შემდეგ ეფექტურობა, სექცია შეზღუდვა, და მაგიდა შეზღუდვა, როგორც წესი, გაუმჯობესებს ორივე მოპოვების და downstream grounding. იგი ასევე გაძლევთ provenance გრძნობს ბუნებრივი საბოლოო მომხმარებლისთვის: instead of surfaceing a opaque internal ID such as chunk_4892, თქვენ შეგიძლიათ ეფუძნოთ რაღაც რეიტინგი შეიძლება დაუყოვნებლივ შეამოწმ Metadata არის კიდევ ერთი ფართობი, რომელიც გამოიყურება არჩეული, სანამ თქვენ უნდა. პრაქტიკაში, metadata არის ის, რაც საშუალებას გაძლევთ ფილტრაცია, მახასიათებლები და რეპუტაცია. სასარგებლო chunk-level metadata ზოგადად მოიცავს დოკუმენტის IDs, ნაწილების გზა, გვერდის ნომრები, დროის ბეჭდვა (ფუნქციური თარიღი, ბოლო მორგებული, ინტეგრირებული at), ექსტრაქციული უსაფრთხოების სიმბოლოები, და ვერსია identifiers (document hash, chunking version, embedding model version). საწარმოო კონტაქტში, ხელმისაწვდომი კონტროლის თვისებები (ტატორი, department, confidentiality, role tags) უნდა იყოს პირველი კლასის, რადგან ისინი The Retrieval Stack That Actually Works Retrieval Stack, რომელიც ნამდვილად მუშაობს პრაქტიკაში, ჰიბრიდული მოპოვება - თხევადი შეფუთვა და რისკური მოპოვება, როგორიცაა BM25 - ხშირად უფრო ძლიერია, განსაკუთრებით როდესაც მომხმარებლები კითხვებს კლასის ნომერი, identifier, akronyms, ან სიტყვები. თხევადი მოპოვება განიცდიან სიტყვური მიზნით კარგად; რისკური მოპოვება ანკირებს თქვენ სწორი პირობები და რისკული ტოკიები, რომ შეფუთვა ხშირად გააუმჯობესებს. Reranking ხშირად არის ადგილი, სადაც სისტემები გააკეთა ყველაზე დიდი ცვლილება რეპუტაციის ხარისხის, არა იმის გამო, რომ ეს არის მექანიკური, არამედ იმის გამო, რომ იგი შეცვალოს საერთო შეცდომა რეჟიმში: პირველი მოპოვების კომპლექტი შეიცავს “Kindy-Related” კუნძულები, და თქვენ უნდა გააუმჯობესოთ ნამდვილად დაკავშირებული კუნძულები ზედაპირზე. Cross-encoder re-rankers (დაპოვებული მოდელები, როგორიცაა bge-reranker ან მართული API, როგორიცაა Cohere ranker) რეპუტაცია კუნძულ კუნძულები გამოყენებით გლუვი კითხვები-დაწვრილებით ურთიერთობები. გუნდები ხშირად იხილებენ ნაცვლად გაზრდის შეკითხვები და გაფართოება არის კიდევ ერთი გაფართოება, რომელიც ადვილია ადრე და შემდეგ აღსანიშნოს. მომხმარებლები ბუნებრივ არ შეკითხვებს კითხვებს, როგორიცაა დოკუმენტები დარეგისტრირებულია. შეტყობინების ნაბიჯი შეუძლია გაფართოებას, ნორმალურიზონტებს და მრავალფეროვანი კითხვებს შეტყობინებას მოკლე კითხვებს. ეს არ უნდა იყოს ფანტასტიკური - მაგრამ საჭიროა შეამოწმოება, რადგან შეტყობინება შეუძლია გამოიწვიოს მომხმარებლის მიზნით. Security: The Layer Everyone Forgets უსაფრთხოება: Layer Everyone Forgets ყველაზე RAG დომები შეუზღუდავი ხელმისაწვდომობის კონტროლი, რადგან ეს იძლევა Prototype. საწარმოში, ეს არის ძირითადი შეზღუდვა. თუ თქვენი სისტემა ინდუსტირებს HR დოკუმენტები, სამედიცინო კონტაქტები, და ინჟინერი სპეციფიკაციები ერთად, თქვენ უნდა აირჩიოთ deterministic უფლებების გზა მომხმარებელს → გაძლევთ ნაწილები, და მოპოვება უნდა იყოს შეზღუდული ამ გზა, სანამ ნებისმიერი შინაარსის მოდის LLM. მოდელი, რომელიც ხელს უწყობს ზრდა, არის წინასწარ ფირფიცირებული მოპოვება: კომპიუტერული უფლებები (RBAC / ABAC), მოპოვება მხოლოდ ნაწილები ერთად თავსებადი ACL თვისებები, reerank ინტეგრირებული კლიენტების კომპლექტი, და დაჯავშნა, თუ რა ნიმუში ხელმისაწვდომია. ეს არის ასევე, სადაც "მათე მონაცემები არ არის უპირატესობრივი" ნომერი გამოჩნდება პრაქტიკაში - გარეშე ნაწილის დონეზე ტაქტიზაცია, თქვენ დასრულდება გატვირთული ხაზები ან ღირებულ, რთული შემდეგ ფირფიტები. ACL- ის გარდა, საწარმოო განთავსების მოთხოვნებს ჩვეულებრივ საჭიროა PII- ის აღჭურვილობა / შეკუმშვის კომბინაცია, ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულებრივ ჩვეულ Monitoring: Closing the Loop კონფიგურაცია: დახურვა loop თუ თქვენ გაქვთ ერთ-ერთი ამ სისტემები მეტი რამდენიმე კვირის განმავლობაში, თქვენ ნახავთ drift. დოკუმენტები ცვლილებები, კითხვის გაფართოების ცვლილებები, ingestion pipeline ცვლილებები, და მოდელის კომპონენტები განახლება. გარეშე მონიტორინგი და შეფასება, ხარისხის მშვიდობლად შეჩერება, სანამ მომხმარებლები შეწყვიტოს Trust ინსტრუმენტი. ძირითადად, თქვენ გსურთ შეამოწმოთ მოპოვების ჯანმრთელობა (recall@k vs. gold set, კონტექსტალური სიზუსტით, reranker lift), გენერაციის ჯანმრთელობა (დაპოვების სიზუსტით, groundedness/faithfulness კონცენტრატორები, რეკლამა სიზუსტით) და ოპერაციული ჯანმრთელობა (p50/p95 მოპოვების სიზუსტით, ღირებულება კითხვისთვის, ingestion lag from document update to searchable index). ყველაზე ეფექტური გუნდი, რომელიც მე ვხედავთ, შეინარჩუნებს ოქროს შეფასების მონაცემთა კომპლექტი - მოთხოვნის წყარო დოკუმენტებთან შეამოწმებული კითხვები - და აწარმოებს იგი გრაფიკით და ცვლილებ ერთ-ერთი ტერიტორია, რომელიც ხშირად შეუზღუდავი არის ვერსიაფიკაცია და რეპუტაცია. როდესაც თქვენ შეცვალოს OCR მოდელები, chunking ლოგიკური, შეფუთვა მოდელები, reerankers, ან გენერაციის მოთხოვნილებები, თქვენ უნდა გზა, რათა შეამოწმოთ, რა ვერსია წარმოებული, რომელიც პასუხი. ეს არის ის, რაც გაძლევთ გადარჩენა და რეპუტაცია შესაძლებელია თვის შემდეგ. Choosing Your Stack აირჩიეთ თქვენი Stack კლასის გადაწყვეტილებები მნიშვნელოვანია, მაგრამ შესაძლებლობები უფრო მნიშვნელოვანია. მრავალი გუნდისთვის მენეჯერიული დადებითი კონფიგურაცია მოყვანილია: ინგლისება მენეჯერირებული დოკუმენტის AI ინსტრუმენტზე ან არქიტექტრირებული დაფუძნებული pipeline- ის მეშვეობით, მენეჯერირებული კონფიგურაციის მონაცემები, ანქიტექტრირების ფართობი, როგორიცაა LlamaIndex ან LangChain, და ნერანკერები (დაპრიენტული ან მენეჯერირებული). სხვები prefer open-source განახლების გამოყენებით Qdrant/Weaviate/OpenSearch, Haystack ან მსგავსი ანქიტექტრირება, და თვითმმართველობის მოდელები კონტროლის და ღირებულების არქიტექტურის მხრივ, სისტემები იძლევა ადვილად მუშაობა, როდესაც ისინი სუფთა დაშორებულია: ingestion მუშაობა, რომელიც იძლევა asynchronously და შეუძლია უსაფრთხოდ გადაიხადოს; სტატისტიკა გარეშე მოპოვების მომსახურება, რომელიც მოცუწოდებს პოლიტიკა და გადაიხადოს გამოცდილება; და გენერაციის მომსახურება, რომელიც მუშაობს შეზღუდული კონტაქტი და ნათელი საწყისი. ტიპიური რეიტინგული განახლება მოიცავს API Gateway, სამუშაო კოდექსი (Kafka / RabbitMQ), ინტენსიური შენახვა ნედლეულის დოკუმენტები და შეამოწმებული მცენარეთა, index layer ( +dense sparse), პლატფორმა centralized logging / metrics