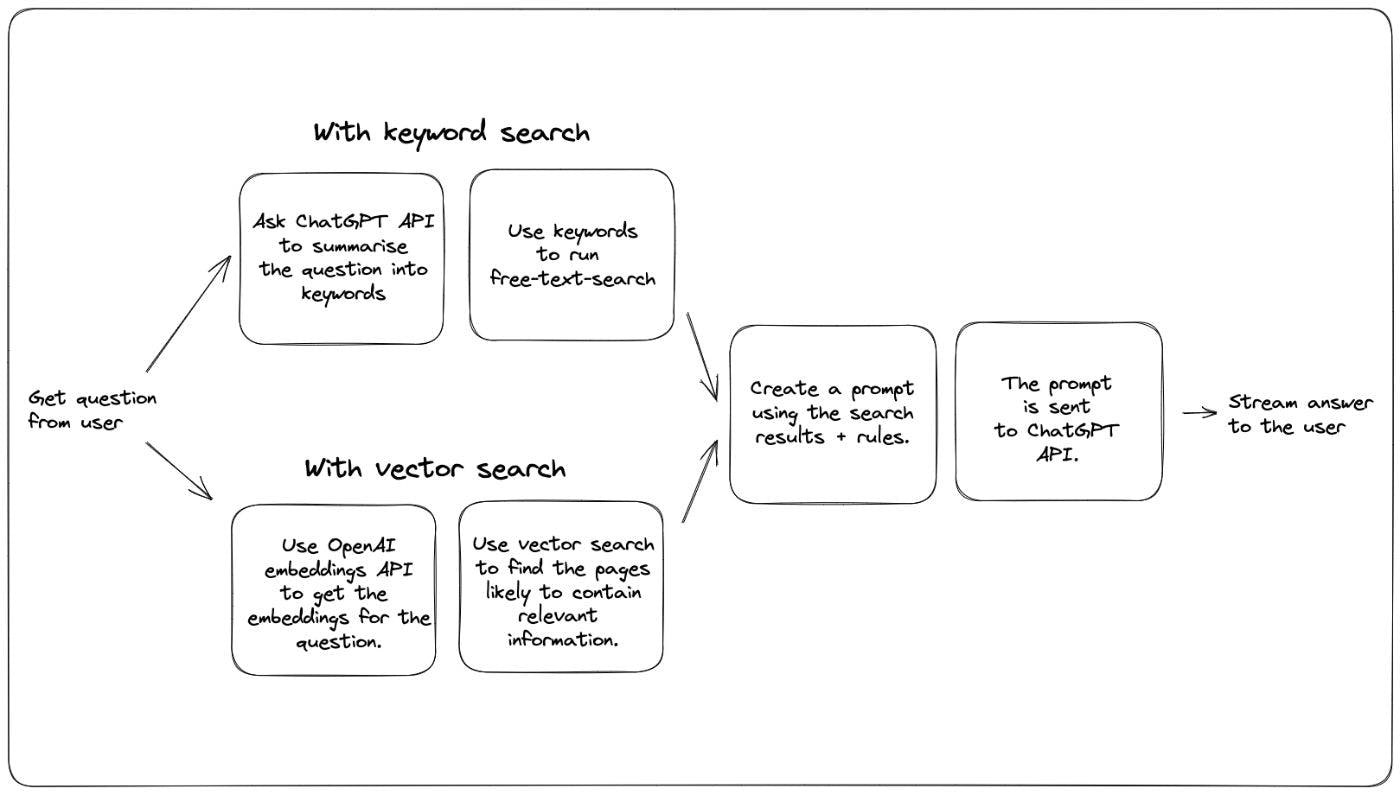
先週、 からの質問に答える Q&A ボットを追加しました。 OpenAI GPT モデルは Xata ドキュメントでトレーニングされていませんが、これは ChatGPT 技術を活用して Xata ドキュメントからの質問に答えます。 ドキュメント これを行う方法は、Simon Willison がこの で提案したアプローチを使用することです。同じアプローチは、 にもあります。アイデアは次のとおりです。 ブログ投稿 OpenAI クックブック ドキュメントに対してテキスト検索を実行して、ユーザーからの質問に最も関連するコンテンツを見つけます。 次の一般的な形式でプロンプトを生成します。 With these rules: {rules} And this text: {context} Given the above text, answer the question: {question} Answer: プロンプトを ChatGPT API に送信し、モデルに回答を完了させます。 これは非常にうまく機能し、比較的低いモデル温度 (温度の概念はこの で説明されています) と組み合わせると、答えがドキュメンテーション。 ブログ記事 このアプローチの主な制限は、上記の 2 番目のステップで作成するプロンプトには、最大 4000 トークン (~3000 ワード) が必要であることです。これは、最初のステップである、最も関連性の高いドキュメントを選択するためのテキスト検索が非常に重要になることを意味します。検索ステップが適切に機能し、適切なコンテキストが提供される場合、ChatGPT も適切で的を射た結果を生成するために適切に機能する傾向があります。 では、ドキュメント内で最も関連性の高いコンテンツを見つける最善の方法は何でしょうか? OpenAI クックブックや Simon のブログでは、セマンティック検索と呼ばれるものを使用しています。セマンティック検索は、言語モデルを活用して、質問とコンテンツの両方の埋め込みを生成します。埋め込みは、いくつかの次元でテキストを表す数値の配列です。同様の埋め込みを持つテキストの断片は、同様の意味を持ちます。これは、質問の埋め込みに最も類似した埋め込みを持つコンテンツの断片を見つけることが良い戦略であることを意味します。 より古典的なキーワード検索に基づく別の可能な戦略は、次のようになります。 次のようなプロンプトで、質問からキーワードを抽出するように ChatGPT に依頼します。 Extract keywords for a search query from the text provided. Add synonyms for words where a more common one exists. 提供されたキーワードを使用してフリーテキスト検索を実行し、上位の結果を選択します 1 つの図にまとめると、2 つのメソッドは次のようになります。 ドキュメントで両方を試してみたところ、いくつかの長所と短所に気づきました。 いくつかの結果を比較することから始めましょう。どちらも同じデータベースに対して実行され、どちらも ChatGPT モデルを使用します。ランダム性が含まれているため、各質問を 2 ~ 3 回実行し、最良の結果と思われるものを選びました。 gpt-3.5-turbo 質問: Xata CLI をインストールするにはどうすればよいですか? ベクトル検索で答える: キーワード検索で答える: : どちらのバージョンも正しい答えを提供しましたが、ベクトル検索の方がもう少し完全です。どちらも正しいドキュメント ページを見つけましたが、キーワード戦略の場合、ハイライト ベースのヒューリスティックが短いテキスト チャンクを選択したと思います。 評決 勝者: ベクトル検索。 スコア: 1-0 質問: Xata を Deno でどのように使用しますか? ベクトル検索で答える: キーワード検索で答える: ベクトル検索の結果は期待外れでした。ドキュメントの Deno 専用ページをなぜか見逃していました。他にも Deno 関連のコンテンツは見つかりましたが、非常に役立つ例を含むページは見つかりませんでした。 評決: 勝者:キーワード検索。 スコア: 1-1 質問: カスタム列タイプを含む CSV ファイルをインポートするにはどうすればよいですか? ベクトル検索の場合: キーワード検索の場合: どちらも適切なページ (「CSV ファイルのインポート」) を見つけましたが、キーワード検索バージョンの方がより完全な回答を得ることができました。まぐれではないことを確認するために、これを複数回実行しました。違いは、テキスト断片の選択方法 (キーワード検索の場合はキーワードの隣、ベクトル検索の場合はページの先頭から) によるものだと思います。 評決: 勝者:キーワード検索。 スコア: 1-2 質問: Users という名前のテーブルを email 列でフィルタリングするにはどうすればよいですか? ベクトル検索の場合: キーワード検索の場合: ベクター検索は、ChatGPT が回答を作成するために使用できるより多くの例がある「フィルタリング」ページを見つけたため、これでよりうまくいきました。メソッド名に「filter」ではなく「query」を使用しているため、キーワード検索の回答が微妙に壊れています。 評決: 勝者: ベクトル検索。 スコア: 2-2 質問: Xata とは何ですか? ベクトル検索の場合: キーワード検索の場合: どちらの回答も非常に優れているため、これは引き分けです。 2 人は異なるページを選択して回答をまとめましたが、どちらもうまく機能しており、勝者を選ぶことはできません。 評決: スコア: 3-3 構成とチューニング これは、キーワード検索に使用される Xata リクエストのサンプルです。 // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "What is Xata?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "If you answer with Markdown snippets, prefer the GitHub flavour.", "Your name is DanGPT" ], "searchType": "keyword", "search": { "fuzziness": 1, "target": [ "slug", { "column": "title", "weight": 4 }, "content", "section", { "column": "keywords", "weight": 4 } ], "boosters": [ { "valueBooster": { "column": "section", "value": "guide", "factor": 18 } } ] } } そして、これはベクトル検索に使用するものです: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "How do I get a record by id?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "Your name is DanGPT" ], "searchType": "vector", "vectorSearch": { "column": "embeddings", "contentColumn": "content", "filter": { "section": "guide" } } } ご覧のとおり、キーワード検索バージョンにはより多くの設定があり、あいまいさとブースターと列の重みを構成しています。ベクトル検索はフィルターのみを使用します。これはキーワード検索のプラスと言えます。検索を調整するためのダイヤルが増えるため、より良い回答が得られます。しかし、それはより多くの作業でもあり、ベクトル検索の結果は、この調整をしなくても非常に良好です。 私たちの場合、ドキュメント検索機能用にキーワード検索を既に調整しています。そのため、必ずしも余分な作業は必要ありませんでした。ChatGPT で遊んでいるうちに、ドキュメントと検索の改善も発見されました。また、Xata はたまたまキーワード検索を調整するための非常に優れた UI を備えているため、作業を開始するのは難しくありませんでした (それについては別のブログ投稿を計画しています)。 ベクトル検索でブースターや列の重みなどを使用できない理由はありませんが、Xata にはまだありません。また、キーワードを作成するのと同じくらい簡単にする他のソリューションも知りません。検索チューニング。そして、一般的に、キーワード検索にはより多くの先行技術がありますが、ベクトル検索が追いつく可能性は十分にあります。 今のところ、キーワード検索が勝者と呼ぶつもりです スコア: 3-4 快適 私たちのドキュメントには、Xata のドッグフーディングという検索機能がすでにあったので、チャット ボットに拡張するのは非常に簡単でした。 Xata はベクター検索もネイティブにサポートするようになりましたが、それを使用するには、すべてのドキュメント ページに埋め込みを追加し、適切なチャンク戦略を考え出す必要がありました。テキスト埋め込みを作成するために OpenAI 埋め込み API を使用しましたが、これは最小限のコストで済みました。 勝者:キーワード検索 スコア 3-5 レイテンシー キーワード検索アプローチでは、ChatGPT API への追加の往復が必要です。これにより、UI でのストリーミングが開始された結果にレイテンシが追加されます。私の測定では、これにより約 1.8 秒の余分な時間が追加されます。 ベクトル検索の場合: キーワード検索の場合: ここでの合計時間とコンテンツのダウンロード時間は、生成された応答の長さに大きく依存するため、関係ありません。 「サーバーの応答を待っています」バー (緑色のバー) を見て比較します。 注: 勝者: ベクトル探索 スコア: 4-5 料金 キーワード検索バージョンでは、ChatGPT API に対して追加の API 呼び出しを行う必要があります。一方、ベクトル検索バージョンでは、データベース内のすべてのドキュメントと質問の埋め込みを生成する必要があります。 多くのドキュメントについて話している場合を除き、これを引き分けと呼びます。 スコア: 5-6 結論 スコアはタイトです!私たちの場合、今のところキーワード検索を使用しています。これは主に、より多くのチューニング方法があり、その結果、一連のテスト問題に対してわずかに優れた回答が生成されるためです。また、検索に加えた改善は、検索とチャットの両方のユースケースに自動的に利益をもたらします。より多くの調整オプションを使用してベクトル検索機能を改善しているため、将来的にはベクトル検索またはハイブリッド アプローチに切り替える可能性があります。 独自のドキュメントやあらゆる種類のナレッジ ベース用に同様のチャット ボットをセットアップしたい場合は、Xata ask エンドポイントを使用して上記を簡単に実装できます。無料で 、 に参加してください。私は個人的にあなたがそれを実行するのを手伝ってくれることをうれしく思います! アカウントを作成し Discord