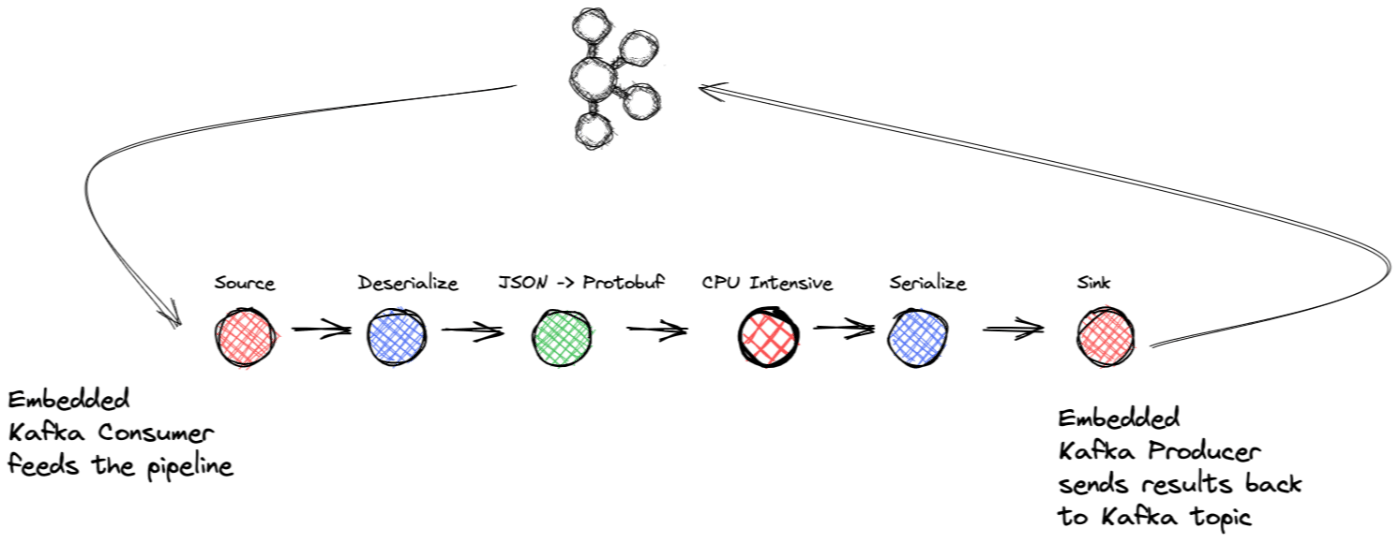
जब आप रुकते हैं और रोजमर्रा की जिंदगी के बारे में सोचते हैं, तो आप हर चीज को आसानी से एक घटना के रूप में देख सकते हैं। निम्नलिखित क्रम पर विचार करें: आपकी कार का "कम ईंधन" संकेतक चालू हो जाता है नतीजतन, आप ईंधन भरने के लिए अगले ईंधन स्टेशन पर रुक जाते हैं जब आप कार में गैस पंप करते हैं, तो आपको छूट पाने के लिए कंपनी के रिवॉर्ड क्लब में शामिल होने के लिए प्रेरित किया जाता है आप अंदर जाते हैं और साइन अप करते हैं और अपनी अगली खरीदारी के लिए क्रेडिट प्राप्त करते हैं हम यहाँ और आगे जा सकते थे, लेकिन मैंने अपनी बात कह दी है: जीवन घटनाओं का एक क्रम है। इस तथ्य को देखते हुए, आज आप एक नया सॉफ्टवेयर सिस्टम कैसे डिजाइन करेंगे? क्या आप अलग-अलग परिणाम एकत्र करेंगे और उन्हें कुछ मनमाने अंतराल पर संसाधित करेंगे या उन्हें संसाधित करने के लिए दिन के अंत तक प्रतीक्षा करेंगे? नहीं, तुम नहीं करोगे; आप प्रत्येक घटना के घटित होते ही उस पर कार्रवाई करना चाहेंगे। निश्चित रूप से, ऐसे मामले हो सकते हैं जहां आप अलग-अलग परिस्थितियों पर तुरंत प्रतिक्रिया नहीं दे सकते... एक बार में एक दिन के मूल्य के लेन-देन को डंप करने के बारे में सोचें। लेकिन फिर भी, आप जैसे ही डेटा प्राप्त करेंगे, आप कार्य करेंगे, यदि आप करेंगे तो एक बड़ी एकमुश्त घटना। तो, आप घटनाओं के साथ काम करने के लिए एक सॉफ्टवेयर सिस्टम कैसे लागू करते हैं? उत्तर स्ट्रीम प्रोसेसिंग है। स्ट्रीम प्रोसेसिंग क्या है? इवेंट डेटा से निपटने के लिए वास्तविक तकनीक बनना, स्ट्रीम प्रोसेसिंग सॉफ़्टवेयर डेवलपमेंट के लिए एक दृष्टिकोण है जो ईवेंट को एप्लिकेशन के प्राथमिक इनपुट या आउटपुट के रूप में देखता है। उदाहरण के लिए, सूचना पर कार्रवाई करने या संभावित धोखाधड़ी वाले क्रेडिट कार्ड से खरीदारी का जवाब देने का इंतजार करने का कोई मतलब नहीं है। दूसरी बार इसमें एक माइक्रोसर्विस में रिकॉर्ड के आने वाले प्रवाह को संभालना शामिल हो सकता है, और उन्हें सबसे कुशलता से संसाधित करना आपके आवेदन के लिए सबसे अच्छा है। जो भी उपयोग मामला है, यह कहना सुरक्षित है कि ईवेंट स्ट्रीमिंग दृष्टिकोण ईवेंट को संभालने का सबसे अच्छा तरीका है। इस ब्लॉग पोस्ट में, हम Apache Kafka®, .NET निर्माता और उपभोक्ता ग्राहक, और Microsoft से उपयोग करके एक इवेंट स्ट्रीमिंग एप्लिकेशन का निर्माण करेंगे। पहली नज़र में, हो सकता है कि आप इन तीनों को स्वचालित रूप से एक साथ काम करने वाले संभावित उम्मीदवारों के रूप में एक साथ न रखें। ज़रूर, काफ्का और .NET क्लाइंट एक बेहतरीन जोड़ी हैं, लेकिन TPL तस्वीर में कहाँ फिट बैठता है? टास्क पैरेलल लाइब्रेरी (TPL) का अधिक बार नहीं, थ्रूपुट एक महत्वपूर्ण आवश्यकता है और काफ्का और डाउनस्ट्रीम प्रसंस्करण से खपत के बीच प्रतिबाधा बेमेल के कारण अड़चनों से बचने के लिए, हम आम तौर पर जहाँ भी अवसर मिलता है, इन-प्रोसेस समानांतरकरण का सुझाव देते हैं। यह देखने के लिए आगे पढ़ें कि एक मजबूत और कुशल इवेंट-स्ट्रीमिंग एप्लिकेशन बनाने के लिए तीनों घटक एक साथ कैसे काम करते हैं। सबसे अच्छी बात यह है कि काफ्का ग्राहक और टीपीएल अधिकांश भारी भारोत्तोलन का ध्यान रखते हैं; आपको केवल अपने व्यावसायिक तर्क पर ध्यान देने की आवश्यकता है। इससे पहले कि हम एप्लिकेशन में गोता लगाएँ, आइए प्रत्येक घटक का संक्षिप्त विवरण दें। अपाचे काफ्का यदि स्ट्रीम प्रोसेसिंग इवेंट स्ट्रीम को संभालने के लिए वास्तविक मानक है, तो इवेंट स्ट्रीमिंग एप्लिकेशन के निर्माण के लिए वास्तविक मानक है। अपाचे काफ्का एक वितरित लॉग है जो अत्यधिक स्केलेबल, लोचदार, दोष-सहिष्णु और सुरक्षित तरीके से प्रदान किया जाता है। संक्षेप में, काफ्का दलालों (सर्वर) और ग्राहकों का उपयोग करता है। ब्रोकर काफ्का क्लस्टर की डिस्ट्रीब्यूटेड स्टोरेज लेयर बनाते हैं, जो डेटा सेंटर या क्लाउड क्षेत्रों को फैला सकती है। क्लाइंट ब्रोकर क्लस्टर से ईवेंट डेटा पढ़ने और लिखने की क्षमता प्रदान करते हैं। काफ्का क्लस्टर दोष-सहिष्णु हैं: यदि कोई ब्रोकर विफल रहता है, तो अन्य ब्रोकर निरंतर संचालन सुनिश्चित करने के लिए काम करेंगे। अपाचे काफ्का कंफ्लुएंट .NET क्लाइंट मैंने पिछले पैराग्राफ में उल्लेख किया था कि ग्राहक या तो काफ्का ब्रोकर क्लस्टर को लिखते हैं या उससे पढ़ते हैं। अपाचे काफ्का जावा क्लाइंट के साथ बंडल करता है, लेकिन कई अन्य क्लाइंट उपलब्ध हैं, अर्थात् .NET काफ्का निर्माता और उपभोक्ता, जो इस ब्लॉग पोस्ट में एप्लिकेशन के केंद्र में है। .NET निर्माता और उपभोक्ता .NET डेवलपर के लिए काफ्का के साथ इवेंट स्ट्रीमिंग की शक्ति लाते हैं। .NET क्लाइंट के बारे में अधिक जानकारी के लिए, देखें। दस्तावेज़ कार्य समानांतर पुस्तकालय टास्क पैरेलल लाइब्रेरी ( ) "सार्वजनिक प्रकारों और सिस्टम में एपीआई का एक सेट है। थ्रेडिंग और सिस्टम। थ्रेडिंग। टास्क नेमस्पेस," समवर्ती अनुप्रयोगों को लिखने के काम को सरल करता है। TPL निम्नलिखित विवरणों को प्रबंधित करके संगामिति को अधिक प्रबंधनीय कार्य बनाता है: टीपीएल 1. कार्य के विभाजन को संभालना 2. थ्रेडपूल पर शेड्यूलिंग थ्रेड्स 3. निम्न-स्तरीय विवरण जैसे रद्दीकरण, राज्य प्रबंधन, आदि। लब्बोलुआब यह है कि TPL का उपयोग करने से आपके एप्लिकेशन के प्रसंस्करण प्रदर्शन को अधिकतम किया जा सकता है, जबकि आपको व्यावसायिक तर्क पर ध्यान केंद्रित करने की अनुमति मिलती है। विशेष रूप से, आप TPL के सबसेट का उपयोग करेंगे। डेटाफ़्लो लाइब्रेरी डेटाफ्लो लाइब्रेरी एक अभिनेता-आधारित प्रोग्रामिंग मॉडल है जो इन-प्रोसेस मैसेज पासिंग और पाइपलाइनिंग कार्यों की अनुमति देता है। डेटाफ्लो घटक टीपीएल के प्रकार और शेड्यूलिंग इंफ्रास्ट्रक्चर पर निर्मित होते हैं और सी # भाषा के साथ समेकित रूप से एकीकृत होते हैं। काफ्का से पढ़ना आमतौर पर काफी तेज होता है, लेकिन प्रसंस्करण (डीबी कॉल या आरपीसी कॉल) आमतौर पर एक अड़चन है। समानांतरकरण के किसी भी अवसर का हम उपयोग कर सकते हैं जो ऑर्डरिंग गारंटी का त्याग किए बिना उच्च थ्रूपुट प्राप्त करेगा, विचार करने योग्य है। इस ब्लॉग पोस्ट में, हम .NET काफ्का क्लाइंट के साथ इन डेटाफ्लो घटकों का उपयोग एक स्ट्रीम प्रोसेसिंग एप्लिकेशन बनाने के लिए करेंगे जो डेटा के उपलब्ध होते ही उसे प्रोसेस कर देगा। डेटाफ्लो ब्लॉक इससे पहले कि हम आपके द्वारा बनाए जा रहे एप्लिकेशन में प्रवेश करें; हमें TPL डेटाफ़्लो लाइब्रेरी के बारे में कुछ पृष्ठभूमि की जानकारी देनी चाहिए। यहां वर्णित दृष्टिकोण सबसे अधिक लागू होता है जब आपके पास सीपीयू और आई/ओ-गहन कार्य होते हैं जिनके लिए उच्च थ्रूपुट की आवश्यकता होती है। TPL डेटाफ्लो लाइब्रेरी में ऐसे ब्लॉक होते हैं जो आने वाले डेटा या रिकॉर्ड को बफर और प्रोसेस कर सकते हैं, और ब्लॉक तीन श्रेणियों में से एक में आते हैं: स्रोत ब्लॉक - डेटा के स्रोत के रूप में कार्य करें, और अन्य ब्लॉक इससे पढ़ सकते हैं। लक्ष्य ब्लॉक - डेटा का रिसीवर या सिंक, जिसे अन्य ब्लॉकों द्वारा लिखा जा सकता है। प्रोपगेटर ब्लॉक - स्रोत और लक्ष्य ब्लॉक दोनों के रूप में व्यवहार करें। आप अलग-अलग ब्लॉक लेते हैं और उन्हें एक रैखिक प्रसंस्करण पाइपलाइन या प्रसंस्करण के अधिक जटिल ग्राफ बनाने के लिए जोड़ते हैं। निम्नलिखित दृष्टांतों पर विचार करें: डेटाफ्लो लाइब्रेरी कई पूर्वनिर्धारित ब्लॉक प्रकार प्रदान करती है जो तीन श्रेणियों में आते हैं: बफरिंग, निष्पादन और समूहीकरण। हम इस ब्लॉग पोस्ट के लिए विकसित परियोजना के लिए बफ़रिंग और निष्पादन प्रकारों का उपयोग कर रहे हैं। BufferBlock<T> एक सामान्य-उद्देश्य वाली संरचना है जो डेटा को बफ़र करती है और निर्माता/उपभोक्ता अनुप्रयोगों में उपयोग के लिए आदर्श है। बफ़रब्लॉक आने वाले डेटा को संभालने के लिए पहले-पहले, पहले-बाहर कतार का उपयोग करता है। बफ़रब्लॉक (और इसे विस्तारित करने वाली कक्षाएं) डेटाफ़्लो लाइब्रेरी में एकमात्र ब्लॉक प्रकार है जो सीधे संदेश लिखने और पढ़ने के लिए प्रदान करता है; अन्य प्रकार ब्लॉक से संदेश प्राप्त करने या संदेश भेजने की अपेक्षा करते हैं। इस कारण से, हमने स्रोत ब्लॉक बनाते समय और इंटरफ़ेस को लागू करते समय और इंटरफ़ेस को लागू करने वाले सिंक ब्लॉक को एक प्रतिनिधि के रूप में एक उपयोग किया। ISourceBlock ITargetBlock BufferBlock हमारे एप्लिकेशन में उपयोग किया जाने वाला अन्य डेटाफ़्लो ब्लॉक प्रकार है। डेटाफ़्लो लाइब्रेरी में अधिकांश ब्लॉक प्रकारों की तरह, आप ट्रांसफ़ॉर्मब्लॉक का एक उदाहरण बनाते हैं, जो एक प्रतिनिधि के रूप में कार्य करने के लिए प्रदान करता है, जिसे ट्रांसफ़ॉर्म ब्लॉक प्राप्त होने वाले प्रत्येक इनपुट रिकॉर्ड के लिए निष्पादित करता है। TransformBlock <TInput, TOutput> Func<TInput, TOutput> डेटाफ्लो ब्लॉक की दो आवश्यक विशेषताएं यह हैं कि आप उन रिकॉर्ड्स की संख्या को नियंत्रित कर सकते हैं जो इसे बफ़र करेंगे और समानांतरता का स्तर। अधिकतम बफ़र क्षमता सेट करके, जब एप्लिकेशन प्रोसेसिंग पाइपलाइन में किसी बिंदु पर लंबे समय तक प्रतीक्षा करता है, तो आपका एप्लिकेशन स्वचालित रूप से बैक प्रेशर लागू करेगा। डेटा के अति-संचय को रोकने के लिए यह बैक प्रेशर आवश्यक है। फिर एक बार जब समस्या कम हो जाती है और बफर आकार में घट जाता है, तो यह फिर से डेटा का उपभोग करेगा। किसी ब्लॉक के लिए संगामिति निर्धारित करने की क्षमता प्रदर्शन के लिए महत्वपूर्ण है। यदि एक ब्लॉक CPU या I/O गहन कार्य करता है, तो थ्रूपुट बढ़ाने के लिए काम को समानांतर करने की स्वाभाविक प्रवृत्ति होती है। लेकिन संगामिति जोड़ने से समस्या हो सकती है—संसाधन क्रम। यदि आप किसी ब्लॉक के कार्य में थ्रेडिंग जोड़ते हैं, तो आप डेटा के आउटपुट ऑर्डर की गारंटी नहीं दे सकते। कुछ मामलों में, आदेश कोई मायने नहीं रखता है, लेकिन जब यह मायने रखता है, तो यह विचार करने के लिए एक गंभीर व्यापार-बंद है: संगामिति बनाम प्रोसेसिंग ऑर्डर आउटपुट के साथ उच्च थ्रूपुट। सौभाग्य से, आपको डेटाफ्लो लाइब्रेरी के साथ यह समझौता नहीं करना है। जब आप एक ब्लॉक की समानता को एक से अधिक पर सेट करते हैं, तो ढांचा गारंटी देता है कि यह इनपुट रिकॉर्ड के मूल क्रम को बनाए रखेगा (ध्यान दें कि समानांतरता के साथ क्रम बनाए रखना कॉन्फ़िगर करने योग्य है, डिफ़ॉल्ट मान सत्य होने के साथ)। यदि डेटा का मूल क्रम ए, बी, सी है, तो आउटपुट ऑर्डर ए, बी, सी होगा। मुझे पता है कि मैं था, इसलिए मैंने इसका परीक्षण किया और पाया कि यह विज्ञापन के रूप में काम करता है। हम इस परीक्षण के बारे में इस पोस्ट में थोड़ी देर बाद बात करेंगे। ध्यान दें कि समानता को बढ़ाना केवल ऑपरेशंस या साहचर्य के साथ किया जाना चाहिए, जिसका अर्थ है कि ऑर्डर या ऑपरेशंस के समूह को बदलने से परिणाम प्रभावित नहीं होगा। स्टेटलेस स्टेटफुल और कम्यूटेटिव इस बिंदु पर, आप देख सकते हैं कि यह कहाँ जा रहा है। आपके पास एक काफ्का विषय है जो उन घटनाओं का प्रतिनिधित्व करता है जिन्हें आपको सबसे तेज़ तरीके से संभालने की आवश्यकता है। तो आप एक स्ट्रीमिंग एप्लिकेशन बनाने जा रहे हैं जिसमें .NET KafkaConsumer के साथ एक स्रोत ब्लॉक शामिल है, व्यावसायिक तर्क को पूरा करने के लिए प्रसंस्करण ब्लॉक, और एक सिंक ब्लॉक जिसमें .NET KafkaProducer शामिल है, अंतिम परिणाम को काफ्का विषय पर वापस लिखने के लिए। यहां एप्लिकेशन के उच्च-स्तरीय दृश्य का उदाहरण दिया गया है: आवेदन में निम्नलिखित संरचना होगी: स्रोत ब्लॉक: एक .NET KafkaConsumer और एक प्रतिनिधि को लपेटना BufferBlock ट्रांसफ़ॉर्म ब्लॉक: डिसेरिएलाइज़ेशन ट्रांसफॉर्म ब्लॉक: ऑब्जेक्ट खरीदने के लिए आने वाले JSON डेटा को मैप करना रूपांतरण ब्लॉक: सीपीयू-गहन कार्य (नकली) ट्रांसफ़ॉर्म ब्लॉक: सीरियलाइज़ेशन टारगेट ब्लॉक: .NET KafkaProducer और डेलिगेट को रैप करना BufferBlock अगला एप्लिकेशन के समग्र प्रवाह का विवरण है और एक शक्तिशाली इवेंट-स्ट्रीमिंग एप्लिकेशन बनाने के लिए काफ्का और डेटाफ्लो लाइब्रेरी का लाभ उठाने के बारे में कुछ महत्वपूर्ण बिंदु हैं। एक इवेंट स्ट्रीमिंग एप्लिकेशन यहां हमारा परिदृश्य है: आपके पास एक काफ्का विषय है जो आपके ऑनलाइन स्टोर से खरीदारी का रिकॉर्ड प्राप्त करता है, और आने वाला डेटा प्रारूप JSON है। आप खरीद विवरण के लिए एमएल संदर्भ लागू करके इन खरीद घटनाओं को संसाधित करना चाहते हैं। इसके अतिरिक्त, आप JSON रिकॉर्ड को Protobuf स्वरूप में रूपांतरित करना चाहेंगे, क्योंकि यह डेटा के लिए कंपनी-व्यापी स्वरूप है. बेशक, आवेदन के लिए थ्रूपुट आवश्यक है। एमएल ऑपरेशंस सीपीयू इंटेंसिव हैं, इसलिए आपको एप्लिकेशन थ्रूपुट को अधिकतम करने का एक तरीका चाहिए, ताकि आप एप्लिकेशन के उस हिस्से को समानांतर करने का लाभ उठा सकें। पाइपलाइन में डेटा का उपभोग स्रोत ब्लॉक से शुरू करते हुए, आइए स्ट्रीमिंग एप्लिकेशन के महत्वपूर्ण बिंदुओं का भ्रमण करें। मैंने पहले इंटरफ़ेस को लागू करने का उल्लेख किया था, और चूंकि भी लागू करता है, हम इसे सभी इंटरफ़ेस विधियों को संतुष्ट करने के लिए एक प्रतिनिधि के रूप में उपयोग करेंगे। तो स्रोत ब्लॉक कार्यान्वयन काफ्का उपभोक्ता और बफरब्लॉक को लपेटेगा। हमारे स्रोत ब्लॉक के अंदर, हमारे पास एक अलग थ्रेड होगा जिसकी एकमात्र जिम्मेदारी उपभोक्ता के लिए उन रिकॉर्ड्स को पास करना है जो उसने बफर में खपत किए हैं। वहां से, बफर पाइपलाइन में अगले ब्लॉक के लिए रिकॉर्ड अग्रेषित करेगा। ISourceBlock BufferBlock ISourceBlock बफ़र में रिकॉर्ड को अग्रेषित करने से पहले, ( कॉल द्वारा लौटाया गया) एक एब्स्ट्रैक्शन द्वारा लपेटा जाता है, जो कुंजी और मान के अतिरिक्त, मूल विभाजन और ऑफ़सेट को कैप्चर करता है, जो कि एप्लिकेशन के लिए महत्वपूर्ण है—और मैं शीघ्र ही समझाऊंगा कि क्यों। यह भी ध्यान देने योग्य है कि संपूर्ण पाइपलाइन अमूर्तता के साथ काम करती है, इसलिए किसी भी परिवर्तन के परिणामस्वरूप एक नया ऑब्जेक्ट होता है जो कुंजी, मान और अन्य आवश्यक फ़ील्ड को लपेटता है जैसे मूल ऑफ़सेट उन्हें संपूर्ण पाइपलाइन के माध्यम से संरक्षित करता है। ConsumeRecord Consumer.consume Record Record Record प्रसंस्करण ब्लॉक एप्लिकेशन कई अलग-अलग ब्लॉकों में प्रसंस्करण को तोड़ देता है। प्रत्येक ब्लॉक प्रसंस्करण श्रृंखला में अगले चरण से जुड़ता है, इसलिए स्रोत ब्लॉक पहले ब्लॉक से जुड़ता है, जो डीरिएलाइजेशन को संभालता है। जबकि .NET KafkaConsumer रिकॉर्ड्स के डिसेरिएलाइज़ेशन को संभाल सकता है, हमारे पास सीरियलाइज्ड पेलोड पर उपभोक्ता पास है और एक ट्रांसफ़ॉर्म ब्लॉक में डीरियलाइज़ करता है। Deserialization CPU इंटेंसिव हो सकता है, इसलिए इसे इसके प्रोसेसिंग ब्लॉक में डालने से हमें जरूरत पड़ने पर ऑपरेशन को समानांतर करने की अनुमति मिलती है। डिसेरिएलाइज़ेशन के बाद, रिकॉर्ड दूसरे ट्रांसफ़ॉर्म ब्लॉक में प्रवाहित होते हैं जो JSON पेलोड को प्रोटोबॉफ़ प्रारूप में खरीद डेटा मॉडल ऑब्जेक्ट में परिवर्तित करता है। अधिक दिलचस्प हिस्सा तब आता है जब डेटा अगले ब्लॉक में जाता है, खरीद लेनदेन को पूरी तरह से पूरा करने के लिए आवश्यक सीपीयू-गहन कार्य का प्रतिनिधित्व करता है। एप्लिकेशन इस भाग का अनुकरण करता है, और आपूर्ति किया गया फ़ंक्शन एक से तीन सेकंड के बीच कहीं भी यादृच्छिक समय के साथ सोता है। यह सिम्युलेटेड प्रोसेसिंग ब्लॉक है जहां हम डेटाफ्लो ब्लॉक फ्रेमवर्क की शक्ति का लाभ उठाते हैं। जब आप किसी डेटाफ्लो ब्लॉक को इंस्टेंट करते हैं, तो आप एक डेलिगेट Func इंस्टेंस प्रदान करते हैं, जो उसके सामने आने वाले प्रत्येक रिकॉर्ड पर लागू होता है और एक इंस्टेंस। मैंने पहले डेटाफ्लो ब्लॉक को कॉन्फ़िगर करने का उल्लेख किया था, लेकिन हम यहां फिर से जल्दी से उनकी समीक्षा करेंगे। में दो आवश्यक गुण होते हैं: उस ब्लॉक के लिए अधिकतम बफर आकार और समानांतरकरण की अधिकतम डिग्री। ExecutionDataflowBlockOptions ExecutionDataflowBlockOptions जबकि हम पाइपलाइन में सभी ब्लॉकों के लिए बफर आकार कॉन्फ़िगरेशन को 10,000 रिकॉर्ड पर सेट करते हैं, हम अपने सिम्युलेटेड सीपीयू इंटेंसिव को छोड़कर, जहां हम इसे 4 पर सेट करते हैं, डिफ़ॉल्ट समानांतरकरण स्तर 1 के साथ बने रहते हैं। ध्यान दें कि डिफ़ॉल्ट डेटाफ्लो बफर आकार है असीमित। हम अगले खंड में प्रदर्शन के निहितार्थों पर चर्चा करेंगे, लेकिन अभी के लिए, हम एप्लिकेशन अवलोकन को पूरा करेंगे। सघन प्रोसेसिंग ब्लॉक एक सीरियलाइज़िंग ट्रांसफ़ॉर्म ब्लॉक को आगे बढ़ाता है जो सिंक ब्लॉक को फीड करता है, जो तब .NET KafkaProducer को लपेटता है और काफ्का विषय के लिए अंतिम परिणाम तैयार करता है। सिंक ब्लॉक उत्पादन के लिए एक प्रतिनिधि और एक अलग थ्रेड का भी उपयोग करता है। थ्रेड बफ़र से अगला उपलब्ध रिकॉर्ड पुनर्प्राप्त करता है। फिर यह को कॉल करता है। लपेटने वाले प्रतिनिधि में गुजरने वाली विधि - उत्पादन अनुरोध पूरा होने के बाद निर्माता I / O थ्रेड प्रतिनिधि को निष्पादित करेगा। BufferBlock KafkaProducer.Produce DeliveryReport Action Action यह एप्लिकेशन के उच्च-स्तरीय पूर्वाभ्यास को पूरा करता है। अब, आइए हमारे सेटअप के एक महत्वपूर्ण हिस्से पर चर्चा करें - कमिटिंग ऑफ़सेट को कैसे संभालना है - जो कि महत्वपूर्ण है क्योंकि हम उपभोक्ता से रिकॉर्ड पाइपलाइन कर रहे हैं। ऑफसेट करना काफ्का के साथ डेटा संसाधित करते समय, आप समय-समय पर ऑफ़सेट (ऑफ़सेट एक काफ्का विषय में एक रिकॉर्ड की तार्किक स्थिति है) रिकॉर्ड करेंगे, आपके आवेदन ने सफलतापूर्वक एक निश्चित बिंदु तक संसाधित किया है। तो कोई ऑफ़सेट क्यों करता है? उत्तर देने के लिए यह एक आसान प्रश्न है: जब आपका उपभोक्ता या तो नियंत्रित तरीके से या त्रुटि से बंद हो जाता है, तो यह अंतिम ज्ञात प्रतिबद्ध ऑफ़सेट से प्रसंस्करण फिर से शुरू कर देगा। समय-समय पर ऑफ़सेट करने से, आपका उपभोक्ता रिकॉर्ड को फिर से प्रोसेस नहीं करेगा या कम से कम एक न्यूनतम राशि आपके एप्लिकेशन को कुछ रिकॉर्ड संसाधित करने के बाद बंद कर देनी चाहिए, लेकिन कमिट करने । इस दृष्टिकोण को कम से कम एक बार प्रसंस्करण के रूप में जाना जाता है, जो गारंटी देता है कि रिकॉर्ड को कम से कम एक बार संसाधित किया जाता है, और त्रुटियों के मामले में, उनमें से कुछ को पुन: संसाधित किया जा सकता है, लेकिन यह एक बढ़िया विकल्प है जब विकल्प डेटा हानि का जोखिम उठाना है। काफ्का बिल्कुल एक बार प्रसंस्करण गारंटी भी प्रदान करता है, और जब तक हम इस ब्लॉग पोस्ट में लेन-देन नहीं करेंगे, आप काफ्का में लेनदेन के बारे में अधिक पढ़ सकते हैं . से पहले यह ब्लॉग पोस्ट जबकि ऑफसेट करने के कई अलग-अलग तरीके हैं, सबसे सरल और सबसे बुनियादी तरीका ऑटो-कमिट दृष्टिकोण है। उपभोक्ता रिकॉर्ड पढ़ता है, और एप्लिकेशन उन्हें प्रोसेस करता है। कॉन्फ़िगर करने योग्य समय बीतने के बाद (रिकॉर्ड टाइमस्टैम्प के आधार पर), उपभोक्ता पहले से उपभोग किए गए रिकॉर्ड के ऑफसेट को प्रतिबद्ध करेगा। आमतौर पर, ऑटो-कमिटिंग एक उचित तरीका है; एक विशिष्ट उपभोग-प्रक्रिया लूप में, आप उपभोक्ता के पास तब तक नहीं लौटेंगे जब तक कि आपने पहले उपभोग किए गए सभी रिकॉर्ड को सफलतापूर्वक संसाधित नहीं कर लिया हो। यदि कोई अनपेक्षित त्रुटि या शटडाउन होता है, तो कोड कभी भी उपभोक्ता के पास वापस नहीं आता है, इसलिए कोई कमिट नहीं होता है। लेकिन यहां हमारे आवेदन में, हम पाइपलाइनिंग कर रहे हैं- हम खपत रिकॉर्ड लेते हैं और उन्हें एक बफर में धकेलते हैं और अधिक उपभोग करने के लिए वापस लौटते हैं-सफल प्रसंस्करण के लिए कोई प्रतीक्षा नहीं है। का लाभ उठाएंगे, जो अगले पैरामीटर के लिए एक एकल पैरामीटर - एक - और इसे (अन्य ऑफ़सेट के साथ) संग्रहीत करता है। ध्यान दें कि विपरीत है कि ऑटो-कमिंग जावा एपीआई के साथ कैसे काम करता है। पाइपलाइनिंग दृष्टिकोण के साथ, हम कम से कम एक बार प्रसंस्करण की गारंटी कैसे देते हैं? हम विधि IConsumer.StoreOffset TopicPartitionOffset ऑफ़सेट प्रबंधन के लिए यह दृष्टिकोण तो प्रतिबद्ध प्रक्रिया इस तरह से संचालित होती है: जब सिंक ब्लॉक काफ्का को उत्पादन के लिए एक रिकॉर्ड प्राप्त करता है, तो वह इसे एक्शन प्रतिनिधि को भी प्रदान करता है। जब निर्माता कॉलबैक निष्पादित करता है, तो यह उपभोक्ता को मूल ऑफ़सेट (स्रोत ब्लॉक में एक ही उदाहरण) पास करता है, और उपभोक्ता StoreOffset विधि का उपयोग करता है। आपके पास अभी भी उपभोक्ता के लिए ऑटो-कमिट सक्षम है, लेकिन आप प्रतिबद्ध होने के लिए ऑफ़सेट प्रदान कर रहे हैं बनाम उपभोक्ता ने आँख बंद करके इस बिंदु तक उपभोग किए गए नवीनतम ऑफ़सेट को प्रतिबद्ध किया है। तो भले ही एप्लिकेशन पाइपलाइनिंग का उपयोग करता है, यह ब्रोकर से एक पावती प्राप्त करने के बाद ही करता है, जिसका अर्थ है कि ब्रोकर और प्रतिकृति दलालों के न्यूनतम सेट ने रिकॉर्ड संग्रहीत किया है। इस तरह से काम करने से एप्लिकेशन तेजी से आगे बढ़ सकता है क्योंकि ब्लॉक अपना काम करते समय उपभोक्ता लगातार पाइपलाइन ला सकता है और फीड कर सकता है। यह दृष्टिकोण संभव है क्योंकि .NET उपभोक्ता क्लाइंट थ्रेड-सुरक्षित है (कुछ तरीके नहीं हैं और इस तरह प्रलेखित हैं), इसलिए हम अपने एकल उपभोक्ता को स्रोत और सिंक ब्लॉक थ्रेड्स दोनों में सुरक्षित रूप से काम कर सकते हैं। निर्माण चरण के दौरान किसी भी त्रुटि के लिए, एप्लिकेशन त्रुटि को लॉग करता है और रिकॉर्ड को वापस नेस्टेड में रखता है ताकि निर्माता ब्रोकर को रिकॉर्ड भेजने का पुनः प्रयास करे। लेकिन यह पुनर्प्रयास तर्क आँख बंद करके किया जाता है, और व्यवहार में, आप शायद अधिक मजबूत समाधान चाहते हैं। BufferBlock प्रदर्शन निहितार्थ अब जब हमने यह जान लिया है कि एप्लिकेशन कैसे काम करता है, आइए प्रदर्शन संख्या देखें। सभी परीक्षण एक macOS बिग सुर (11.6) लैपटॉप पर स्थानीय रूप से निष्पादित किए गए थे, इसलिए इस परिदृश्य में आपका माइलेज भिन्न हो सकता है। प्रदर्शन परीक्षण सेटअप सीधा है: JSON प्रारूप में एक काफ्का विषय के लिए 1M रिकॉर्ड तैयार करें। यह कदम समय से पहले किया गया था और परीक्षण माप में शामिल नहीं किया गया था। काफ्का डेटाफ्लो-सक्षम एप्लिकेशन प्रारंभ करें और सभी ब्लॉकों में समानांतरकरण को 1 (डिफ़ॉल्ट) पर सेट करें एप्लिकेशन तब तक चलता है जब तक कि यह 1M रिकॉर्ड को सफलतापूर्वक संसाधित नहीं कर लेता, फिर यह बंद हो जाता है सभी रिकॉर्ड को संसाधित करने में लगने वाले समय को रिकॉर्ड करें दूसरे दौर के लिए एकमात्र अंतर नकली CPU-गहन ब्लॉक के लिए MaxDegreeOfParallelism को चार पर सेट करना था। यहाँ परिणाम हैं: अभिलेखों की संख्या समवर्ती कारक समय (मिनट) 1M 1 38 1M 4 9 तो बस एक कॉन्फ़िगरेशन सेट करके, हमने इवेंट ऑर्डर को बनाए रखते हुए थ्रूपुट में काफी सुधार किया। इसलिए अधिकतम समांतरता को चार तक सक्षम करके, हम चार से अधिक कारक द्वारा अपेक्षित गति-अप प्राप्त करते हैं। लेकिन इस प्रदर्शन सुधार का महत्वपूर्ण हिस्सा यह है कि आपने कोई समवर्ती कोड नहीं लिखा है, जिसे सही तरीके से करना मुश्किल होगा। इससे पहले ब्लॉग पोस्ट में, मैंने यह पुष्टि करने के लिए एक परीक्षण का उल्लेख किया था कि डेटाफ्लो ब्लॉक के साथ समवर्ती घटना क्रम को संरक्षित करता है, तो चलिए अब इसके बारे में बात करते हैं। परीक्षण में निम्नलिखित चरण शामिल थे: काफ्का विषय के लिए 1M पूर्णांक (0-999,999) का उत्पादन करें पूर्णांक प्रकारों के साथ कार्य करने के लिए संदर्भ एप्लिकेशन को संशोधित करें सिम्युलेटेड रिमोट प्रोसेस ब्लॉक के लिए एक के समवर्ती स्तर के साथ एप्लिकेशन को चलाएं - एक काफ्का विषय के लिए उत्पादन करें एप्लिकेशन को चार के समवर्ती स्तर के साथ फिर से चलाएँ और संख्याओं को दूसरे काफ्का विषय पर प्रस्तुत करें दोनों परिणाम विषयों से पूर्णांकों का उपभोग करने के लिए एक प्रोग्राम चलाएँ और उन्हें स्मृति में एक सरणी में संग्रहीत करें दोनों सरणियों की तुलना करें और पुष्टि करें कि वे समान क्रम में हैं इस परीक्षण का परिणाम यह था कि दोनों सरणियों में 0 से 999,999 के क्रम में पूर्णांक शामिल थे, यह साबित करते हुए कि एक से अधिक के समानांतरता के स्तर के साथ डेटाफ्लो ब्लॉक का उपयोग करने से आने वाले डेटा के प्रसंस्करण क्रम को बनाए रखा जाता है। आप में डेटाफ़्लो समानांतरवाद के बारे में अधिक विस्तृत जानकारी प्राप्त कर सकते हैं। दस्तावेज़ीकरण सारांश पोस्ट में, हमने एक मजबूत, उच्च-थ्रूपुट इवेंट स्ट्रीमिंग एप्लिकेशन बनाने के लिए .NET काफ्का क्लाइंट और टास्क पैरेलल लाइब्रेरी का उपयोग करने का तरीका पेश किया। काफ्का उच्च-प्रदर्शन इवेंट स्ट्रीमिंग प्रदान करता है, और टास्क पैरेलल लाइब्रेरी आपको सभी विवरणों को संभालने के लिए बफरिंग के साथ समवर्ती एप्लिकेशन बनाने के लिए बिल्डिंग ब्लॉक्स देता है, जिससे डेवलपर्स को व्यावसायिक तर्क पर ध्यान केंद्रित करने की अनुमति मिलती है। जबकि एप्लिकेशन के लिए परिदृश्य थोड़ा काल्पनिक है, उम्मीद है, आप दो तकनीकों के संयोजन की उपयोगिता देख सकते हैं। इसे आज़माइए- . इस यहाँ GitHub रिपॉजिटरी है यहाँ भी प्रकाशित हुआ।