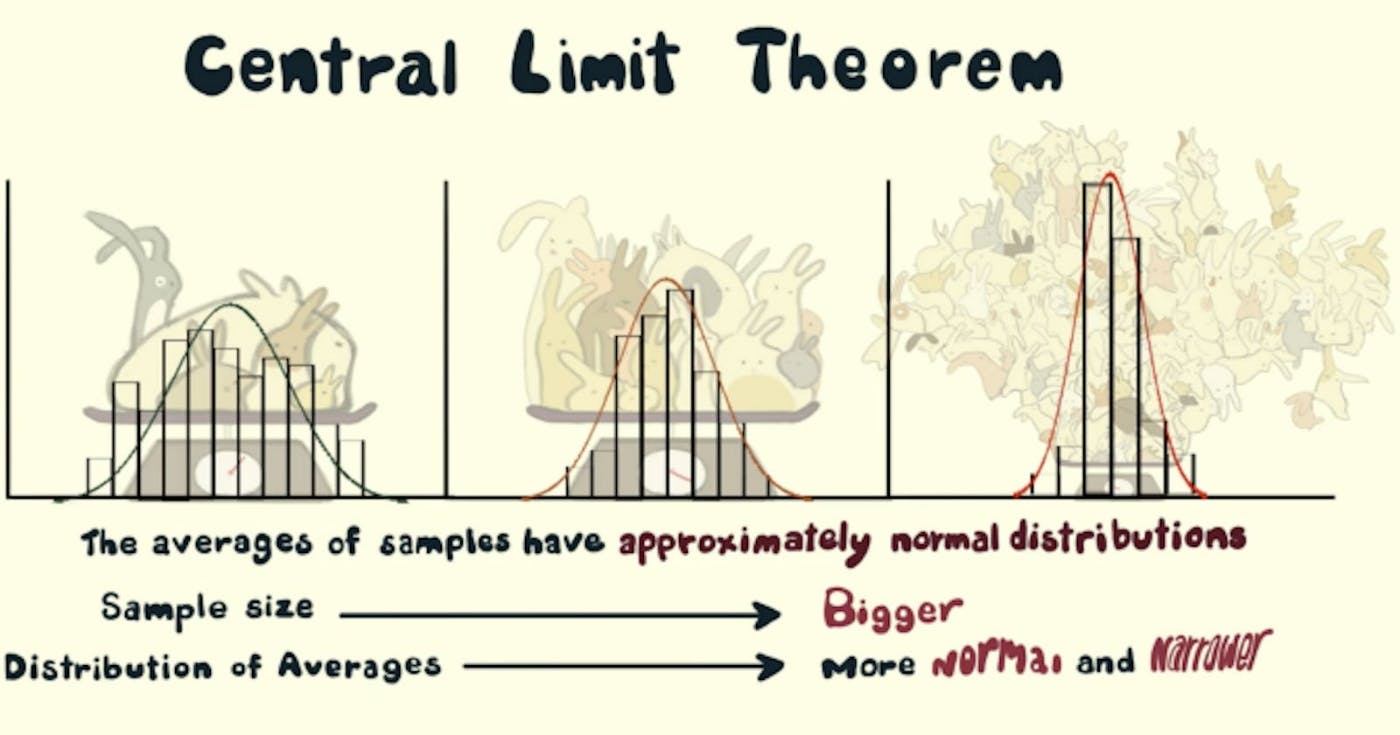
परिभाषा, महत्व और अनुप्रयोग टीएलडीआर: आप पूरा कोड पा सकते हैं। यहां GitHub पर केंद्रीय सीमा प्रमेय निम्नलिखित घटना को दर्शाता है: कोई भी वितरण ले लो! (फुटबॉल मैच में पासों की संख्या का वितरण कहें) उस वितरण से n नमूने लेना शुरू करें (मान लें n = 5) कई बार [मान लें m = 1000] बार। प्रत्येक नमूना सेट का माध्य लें (इसलिए हमारे पास m = 1000 माध्य होगा) साधनों का वितरण होगा। (यदि आप x-अक्ष पर माध्य और y-अक्ष पर उनकी आवृत्ति आलेखित करते हैं तो आपको वह प्रसिद्ध घंटी वक्र मिलेगा।) सामान्य रूप से (कम या ज्यादा) वितरित छोटा मानक विचलन प्राप्त करने के लिए n बढ़ाएँ और सामान्य वितरण का बेहतर सन्निकटन प्राप्त करने के लिए m बढ़ाएँ। लेकिन मुझे इसकी परवाह क्यों करनी चाहिए? क्या आप प्रसंस्करण के लिए संपूर्ण डेटा लोड करने में असमर्थ हैं? कोई समस्या नहीं, डेटा से कई नमूने निकालें और माध्य, मानक विचलन, योग आदि जैसे डेटा मापदंडों का अनुमान लगाने के लिए केंद्रीय सीमा प्रमेय का उपयोग करें। यह आपके समय और धन के संदर्भ में संसाधनों की बचत कर सकता है। क्योंकि अब, हम जनसंख्या से काफी छोटे नमूनों पर काम कर सकते हैं और पूरी जनसंख्या के लिए निष्कर्ष निकाल सकते हैं! क्या एक निश्चित नमूना एक निश्चित जनसंख्या (या डेटा सेट) से संबंधित है? आइए नमूना माध्य, जनसंख्या माध्य, नमूना मानक विचलन और जनसंख्या मानक विचलन का उपयोग करके जाँच करें। परिभाषा अज्ञात वितरण वाले डेटासेट को देखते हुए (यह एक समान, द्विपद या पूरी तरह से यादृच्छिक हो सकता है), नमूना साधन सामान्य वितरण का अनुमान लगाएगा। स्पष्टीकरण यदि हम कोई डेटासेट या जनसंख्या लेते हैं और हम जनसंख्या से नमूने लेना शुरू करते हैं, मान लीजिए कि हम 10 नमूने लेते हैं और उन नमूनों का माध्य लेते हैं, और हम ऐसा करते रहते हैं, ऐसा करने के बाद, कुछ बार, मान लीजिए 1000 बार, हमें 1000 साधन मिलते हैं और जब हम इसे आलेखित करते हैं, तो हमें एक वितरण मिलता है जिसे नमूना साधनों का नमूना वितरण कहा जाता है। यह नमूना वितरण (कमोबेश) सामान्य वितरण का अनुसरण करता है! यह केन्द्रीय सीमा प्रमेय है। एक सामान्य वितरण में कई गुण होते हैं जो विश्लेषण के लिए उपयोगी होते हैं। चित्र.1 नमूना साधनों का नमूना वितरण (सामान्य वितरण के बाद) सामान्य वितरण के गुण: माध्य, बहुलक और माध्यिका सभी समान हैं। 68% डेटा माध्य के एक मानक विचलन के अंतर्गत आता है। 95% डेटा माध्य के दो मानक विचलनों के अंतर्गत आता है। वक्र केंद्र में सममित है (यानी, माध्य के आसपास, μ)। इसके अलावा, नमूना साधनों के नमूना वितरण का माध्य जनसंख्या माध्य के बराबर है। यदि μ जनसंख्या माध्य है और μX̅ नमूने का माध्य है, तो इसका मतलब है: चित्र 2 जनसंख्या माध्य = नमूना माध्य और जनसंख्या के मानक विचलन (σ) का मानक विचलन नमूनाकरण वितरण (σX̅) से निम्नलिखित संबंध है: यदि σ जनसंख्या का मानक विचलन है और σX̅ नमूना साधनों का मानक विचलन है, और n नमूना आकार है, तो हमारे पास है चित्र.3 जनसंख्या मानक विचलन और नमूना वितरण मानक विचलन के बीच संबंध अंतर्ज्ञान चूंकि हम आबादी से कई नमूने ले रहे हैं, इसलिए अक्सर साधन वास्तविक आबादी के बराबर (या करीब) होंगे। इसलिए, हम वास्तविक जनसंख्या माध्य के बराबर नमूना साधनों के नमूना वितरण में एक शिखर (मोड) की उम्मीद कर सकते हैं। एकाधिक यादृच्छिक नमूने और उनके साधन वास्तविक जनसंख्या माध्य के आसपास होंगे। इसलिए, हम मान सकते हैं कि 50% साधन जनसंख्या माध्य से अधिक होंगे और 50% उससे (माध्यिका) से कम होंगे। यदि हम नमूना आकार (10 से 20 से 30) बढ़ाते हैं, तो अधिक से अधिक नमूना साधन जनसंख्या माध्य के करीब आ जाएंगे। इसलिए, उन साधनों का औसत (माध्य) कमोबेश जनसंख्या माध्य के समान होना चाहिए। उस चरम मामले पर विचार करें जहां नमूना आकार जनसंख्या आकार के बराबर है। इसलिए, प्रत्येक नमूने के लिए, माध्य जनसंख्या माध्य के समान होगा। यह सबसे संकीर्ण वितरण है (नमूना साधनों का मानक विचलन, यहां 0 है)। इसलिए, जैसे-जैसे हम नमूना आकार बढ़ाते हैं (10 से 20 से 30 तक) मानक विचलन कम होता जाएगा (क्योंकि नमूना वितरण में प्रसार सीमित होगा और अधिक नमूना साधन जनसंख्या माध्य की ओर केंद्रित होंगे)। इस घटना को "चित्र 3" के सूत्र में कैद किया गया है, जहां नमूना वितरण का मानक विचलन नमूना आकार के वर्गमूल के व्युत्क्रमानुपाती होता है। यदि हम अधिक से अधिक नमूने (1,000 से 5,000 से 10,000 तक) लेते हैं, तो नमूना वितरण अधिक सहज वक्र होगा, क्योंकि अधिक नमूने केंद्रीय सीमा प्रमेय के अनुसार व्यवहार करेंगे, और पैटर्न साफ-सुथरा होगा। "बातचीत सस्ती है, मुझे कोड दिखाओ!" - लिनस टोरवाल्ड्स तो, आइए कोड के माध्यम से केंद्रीय सीमा प्रमेय का अनुकरण करें: कुछ आयात: import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math उपयोग करके एक जनसंख्या बनाएं। आप डेटा उत्पन्न करने के लिए विभिन्न वितरण आज़मा सकते हैं। निम्नलिखित कोड एक प्रकार का नीरस रूप से घटता हुआ वितरण उत्पन्न करता है: random.randint() def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population नमूने बनाएं, और उनका माध्य बार लें: sample_count def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list कुछ लेबलों के साथ डेटा के वितरण को प्लॉट करने का कार्य। def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show() कोड चलाने का मुख्य कार्य: def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True) आप पूरा कोड पा सकते हैं। यहां GitHub पर सन्दर्भ: कार्रवाई में केंद्रीय सीमा प्रमेय केंद्रीय सीमा प्रमेय: एक वास्तविक जीवन अनुप्रयोग केंद्रीय सीमा प्रमेय का परिचय मशीन लर्निंग के लिए केंद्रीय सीमा प्रमेय का एक संक्षिप्त परिचय केंद्रीय सीमा प्रमेय कवर छवि क्रेडिट: केसी डन और क्रिएचर वीमियो पर कास्ट सुझाए गए पाठ (सुझाए गए वीडियो): खानाअकादमी/केंद्रीय-सीमा-प्रमेय मशीन लर्निंग डेटा विज्ञान आँकड़े भी प्रकाशित किया गया यहाँ