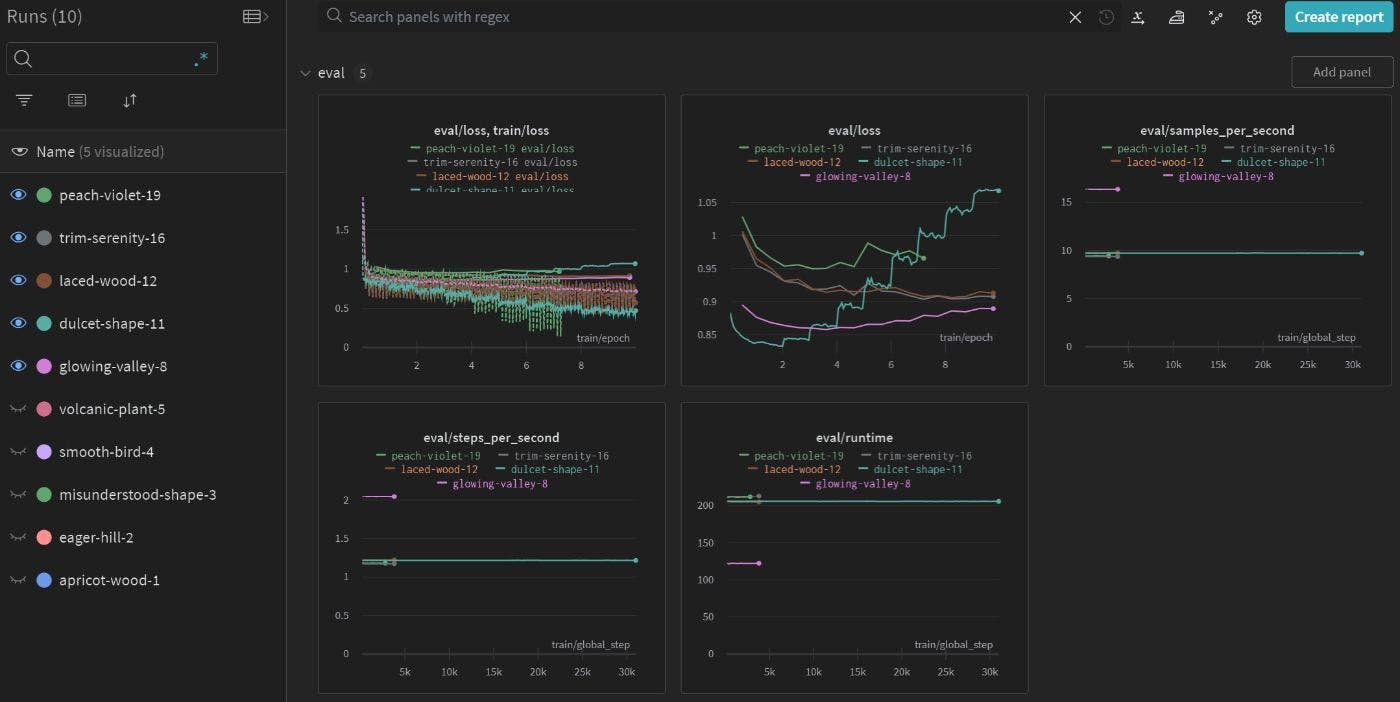
चैटजीपीटी के जारी होने के बाद से (एलएलएम) सॉफ्टवेयर विकास में चर्चा का विषय बन गए हैं। मनुष्यों के साथ स्वाभाविक बातचीत करने की इसकी क्षमता हिमशैल की नोक मात्र है। लैंगचेन या सिमेंटिक कर्नेल जैसे उपकरणों के साथ उन्नत, एलएलएम में उपयोगकर्ताओं के सॉफ़्टवेयर के साथ इंटरैक्ट करने के तरीके को पूरी तरह से बदलने की क्षमता है। दूसरे शब्दों में, एलएलएम कार्यात्मकताओं और डेटा स्रोतों के बीच तालमेल बना सकते हैं, और अधिक कुशल और सहज उपयोगकर्ता अनुभव प्रदान कर सकते हैं। बड़े भाषा मॉडल उदाहरण के लिए, कई लोग पहले से ही अपने अगले वायरल वीडियो के लिए एआई-आधारित सामग्री निर्माण टूल का उपयोग कर रहे हैं। एक विशिष्ट वीडियो उत्पादन पाइपलाइन में स्क्रिप्टिंग, लॉजिस्टिक्स, स्टोरीबोर्डिंग, संपादन और मार्केटिंग, बस कुछ ही नाम शामिल हैं। प्रक्रिया को सुव्यवस्थित करने के लिए, एलएलएम सामग्री रचनाकारों को स्क्रिप्ट लिखते समय अनुसंधान में मदद कर सकता है, शूट के लिए प्रॉप्स खरीद सकता है, स्क्रिप्ट के आधार पर स्टोरीबोर्ड तैयार कर सकता है (छवि निर्माण के लिए स्थिर प्रसार की आवश्यकता हो सकती है), संपादन प्रक्रिया को सुविधाजनक बना सकता है, और आकर्षक शीर्षक लिख सकता है /सोशल मीडिया पर विचार आकर्षित करने के लिए वीडियो विवरण। एलएलएम वह मूल है जो इन सभी को व्यवस्थित करता है, लेकिन सॉफ्टवेयर उत्पाद में एलएलएम को शामिल करते समय कई चिंताएं हो सकती हैं: यदि मैं OpenAI की API का उपयोग करता हूँ, तो क्या मैं इस सेवा पर बहुत अधिक निर्भर हो जाऊँगा? यदि वे कीमत बढ़ा दें तो क्या होगा? यदि वे सेवा उपलब्धता बदल दें तो क्या होगा? मुझे यह पसंद नहीं है कि कैसे OpenAI सामग्री को सेंसर करता है या कुछ उपयोगकर्ता इनपुट पर गैर-रचनात्मक प्रतिक्रिया प्रदान करता है। (या दूसरे तरीके से: मुझे यह पसंद नहीं है कि कैसे OpenAI सेंसरशिप कुछ चीजों को नजरअंदाज कर देती है जो मेरे उपयोग के मामले में संवेदनशील हैं।) यदि मेरे ग्राहक निजी क्लाउड या ऑन-प्रिमाइसेस परिनियोजन पसंद करते हैं, तो मेरे पास क्या विकल्प हैं? चैटजीपीटी मैं बस नियंत्रण रखना चाहता हूं. मुझे एलएलएम को अनुकूलित करने की आवश्यकता है और मैं इसे सस्ता चाहता हूं। इन्हीं चिंताओं के कारण, मुझे आश्चर्य है कि क्या ओपनएआई के जीपीटी मॉडल के बराबर कोई ओपन-सोर्स हो सकता है। सौभाग्य से, अद्भुत ओपन-सोर्स समुदाय पहले से ही कुछ बहुत ही आशाजनक समाधान साझा कर रहे हैं। मैंने आज़माने का निर्णय लिया, जो आपके स्वयं के एलएलएम के प्रशिक्षण के लिए एक पैरामीटर-कुशल फ़ाइन-ट्यूनिंग विधि है। यह ब्लॉग पोस्ट इस प्रक्रिया, मेरे सामने आने वाली समस्याओं, मैंने उन्हें कैसे हल किया, और आगे क्या हो सकता है, पर चर्चा करता है। यदि आप भी अपने स्वयं के एलएलएम के प्रशिक्षण के लिए तकनीक का उपयोग करना चाहते हैं, तो मुझे आशा है कि जानकारी मदद कर सकती है। अल्पाका-लोरा चलो शुरू करें! सामग्री अवलोकन LLaMA, अल्पाका और LoRA क्या है? फाइन-ट्यूनिंग प्रयोग स्रोत कोड को शीघ्रता से स्कैन करना पहला प्रयास पहला अवलोकन दूसरा प्रयास और (कुछ हद तक) सफलता 7बी से आगे जाना सारांश LLaMA, अल्पाका और LoRA क्या है? मेटा एआई के फाउंडेशन भाषा मॉडल का एक संग्रह है। इन ऑटोरेग्रेसिव मॉडल में पैरामीटर संख्या 7B से 65B तक होती है, और इनका उपयोग केवल अनुसंधान उद्देश्यों के लिए किया जा सकता है। मेटा ने हाल ही में जारी किया है, जिसका कुछ सीमाओं के साथ व्यावसायिक उपयोग किया जा सकता है। LLaMA मॉडल परिवार को जो चीज़ विशेष बनाती है, वह है इसका प्रशिक्षण कोष और प्रदर्शन। मेटा बताता है कि LLaMA को सार्वजनिक रूप से उपलब्ध डेटासेट पर प्रशिक्षित किया जाता है। इसका 13बी वेरिएंट अधिकांश बेंचमार्क पर जीपीटी-3 (एक 175बी मॉडल) के बराबर प्रदर्शन हासिल करता है। एलएलएएमए LLaMA 2 एलएलएएमए पर आधारित निर्देश-अनुसरण करने वाला एलएलएम बनाने का स्टैनफोर्ड का प्रयास है। यह इस तरह काम करता है: अल्पाका निर्देश-इनपुट-प्रतिक्रिया त्रिक उत्पन्न करने के लिए एक भाषा मॉडल से पूछें। LLaMA को ठीक करने के लिए जेनरेट किए गए डेटा का उपयोग करें। फाइन-ट्यूनिंग के बाद, LLaMA उपयोगकर्ता के निर्देशों का पालन करने और उसके अनुसार प्रतिक्रिया देने में सक्षम है। यहां वेनिला एलएलएएमए की प्रतिक्रिया और सुव्यवस्थित एलएलएएमए प्रतिक्रिया के बीच तुलना की गई है: { "instruction": "Answer user's question.", "input": "Can you put a medium voltage circuit breaker in a low voltage switchgear? Why? Explain in detail.", "vanilla LLaMA": { "answer": "Yes, you can put a medium voltage circuit breaker in a low voltage switchgear. The medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put....(repetition continues)" }, "fine-tuned LLaMA": { "answer": "No, it is not possible to put a medium voltage circuit breaker in a low voltage switchgear. This is because low voltage switchgear is designed to handle voltages up to 1 kV, while medium voltage switchgear is designed to handle voltages from 1 kV to 38 kV. The circuit breakers, contacts, and other components in low voltage switchgear are not suitable for the higher voltages and currents of medium voltage switchgear. Using a medium voltage circuit breaker in a low voltage switchgear could result in damage to the components and could pose a safety hazard." } } जैसा कि आप देख सकते हैं, फाइन-ट्यूनिंग एलएलएम व्यवहार को काफी हद तक बदल देती है। वेनिला मॉडल दोहराव पाश में फंस गया है। हालाँकि सुव्यवस्थित मॉडल ने 100% सही प्रतिक्रिया नहीं दी, कम से कम इसका उत्तर एक शानदार "नहीं" है। प्रयोग करने योग्य एलएलएम के उत्पादन के लिए फाइन-ट्यूनिंग एक आवश्यक कदम है। कई मामलों में, एक ओपन-सोर्स फाइन-ट्यून एलएलएम तैनात करना पर्याप्त है। हालाँकि, कुछ अनुकूलित व्यावसायिक उपयोग के मामलों में, डोमेन-विशिष्ट डेटासेट पर मॉडल को ठीक करना बेहतर हो सकता है। अल्पाका की सबसे बड़ी खामी इसकी संसाधन आवश्यकता है। इसका GitHub पेज बताता है कि: सहजता से, 7बी मॉडल को फाइन-ट्यूनिंग करने के लिए लगभग 7 x 4 x 4 = 112 जीबी वीआरएएम की आवश्यकता होती है। यह A100 80GB GPU से अधिक VRAM है जिसे संभाल सकता है। हम उपयोग करके VRAM आवश्यकता को बायपास कर सकते हैं। LoRA का लोरा इस तरह काम करता है: किसी मॉडल में कुछ वज़न चुनें, जैसे ट्रांसफार्मर मॉडल में क्वेरी प्रोजेक्शन वज़न $W_q$। चयनित वज़न में एडाप्टर वज़न जोड़ें (हाँ, अंकगणितीय जोड़)। मूल मॉडल को फ्रीज करें, केवल अतिरिक्त वजन को प्रशिक्षित करें। अतिरिक्त वजन में कुछ विशेष गुण होते हैं। इस से प्रेरित होकर, एडवर्ड हू एट अल। दिखाया गया है कि एक मूल मॉडल वजन $W_o\in R^{d \times k}$ के लिए, आप डाउनस्ट्रीम कार्यों के लिए एक सुव्यवस्थित वजन $W_o'=W_o+BA$ का उत्पादन कर सकते हैं, जहां $B\in R^{d \times r}$ , $A \in R^{r \times k}$ और $r\ll min(d, k)$ एडाप्टर वजन की "आंतरिक रैंक" है। एडॉप्टर वजन के लिए उचित $r$ सेट करना महत्वपूर्ण है, क्योंकि छोटा $r$ मॉडल के प्रदर्शन को कम करता है, और बड़ा $r$ आनुपातिक प्रदर्शन लाभ के बिना एडॉप्टर वजन आकार को बढ़ाता है। पेपर यह तकनीक ट्रंकेटेड एसवीडी के समान है, जो एक मैट्रिक्स को कई छोटे मैट्रिक्स में विघटित करके और केवल कुछ सबसे बड़े एकवचन मानों को रखकर अनुमानित करता है। $W_o\in R^{100 \times 100}$ मानते हुए, एक पूर्ण फाइन-ट्यूनिंग से 10,000 पैरामीटर बदल जाएंगे। $r=8$ के साथ LoRA फाइन-ट्यूनिंग से फाइन-ट्यून किए गए वजन को 2 भागों में विघटित किया जाएगा, $B\in R^{100 \times 8}$ और $A\in R^{8 \times 100}$, प्रत्येक भाग में 800 पैरामीटर (कुल 1600 पैरामीटर) हैं। प्रशिक्षण योग्य पैरामीटरों की संख्या 6.25 गुना कम हो गई है। लोआरए के साथ मॉडल को बदलने के बाद, हमें एक मॉडल मिला जिसमें केवल ~ 1% प्रशिक्षण योग्य वजन है, फिर भी कुछ डोमेन में इसके प्रदर्शन में काफी सुधार हुआ है। यह हमें RTX 4090 या V100 जैसे अधिक सुलभ हार्डवेयर पर 7B या 13B मॉडल को प्रशिक्षित करने की अनुमति देगा। फाइन-ट्यूनिंग प्रयोग मैंने Huawei क्लाउड पर GPU-त्वरित VM इंस्टेंस ( , 8vCPU, 64GB RAM, 1x V100 32GB VRAM) के साथ प्रयोग चलाया। यह ज्ञात है कि V100 bfloat16 डेटा प्रकार का समर्थन नहीं करता है, और इसका टेंसर कोर int8 का समर्थन नहीं करता है। त्वरण. ये 2 सीमाएँ मिश्रित परिशुद्धता प्रशिक्षण को धीमा कर सकती हैं और मिश्रित परिशुद्धता प्रशिक्षण के दौरान संख्यात्मक अतिप्रवाह का कारण बन सकती हैं। हम इसे बाद की चर्चा के लिए ध्यान में रखेंगे। p2s.2xlarge स्रोत कोड को शीघ्रता से स्कैन करना और परियोजना के मूल हैं। पहली स्क्रिप्ट एलएलएएमए मॉडल को फाइन-ट्यून करती है, और दूसरी स्क्रिप्ट उपयोगकर्ताओं के साथ चैट करने के लिए फाइन-ट्यून मॉडल का उपयोग करती है। आइए सबसे पहले के मुख्य प्रवाह पर एक नज़र डालें: finetune.py generate.py finetune.py पूर्व-प्रशिक्षित बड़े फाउंडेशन मॉडल को लोड करना model = LlamaForCausalLM.from_pretrained( base_model, # name of a huggingface compatible LLaMA model load_in_8bit=True, torch_dtype=torch.float16, device_map=device_map, ) मॉडल के टोकननाइज़र को लोड करें tokenizer = LlamaTokenizer.from_pretrained(base_model) tokenizer.pad_token_id = ( 0 # unk. we want this to be different from the eos token ) tokenizer.padding_side = "left" # Allow batched inference प्रशिक्षण टेम्पलेट के आधार पर, दो कार्यों, और के साथ मॉडल इनपुट तैयार करें। tokenize generate_and_tokenize_prompt हगिंगफेस के का उपयोग करके एक LoRA अनुकूलित मॉडल बनाएं PEFT config = LoraConfig( r=lora_r, # the lora rank lora_alpha=lora_alpha, # a weight scaling factor, think of it like learning rate target_modules=lora_target_modules, # transformer modules to apply LoRA to lora_dropout=lora_dropout, bias="none", task_type="CAUSAL_LM", ) model = get_peft_model(model, config) एक प्रशिक्षक उदाहरण बनाएं और प्रशिक्षण शुरू करें trainer = transformers.Trainer( model=model, train_dataset=train_data, eval_dataset=val_data, args=transformers.TrainingArguments( ... यह बहुत आसान है. अंत में, स्क्रिप्ट चेकपॉइंट, एडॉप्टर वेट और एडॉप्टर कॉन्फ़िगरेशन के साथ एक मॉडल फ़ोल्डर तैयार करती है। के मुख्य प्रवाह को देखें आगे, आइए generate.py : लोड मॉडल और एडॉप्टर वजन model = LlamaForCausalLM.from_pretrained( base_model, device_map={"": device}, torch_dtype=torch.float16, ) model = PeftModel.from_pretrained( model, lora_weights, device_map={"": device}, torch_dtype=torch.float16, ) जनरेशन कॉन्फ़िगरेशन निर्दिष्ट करें generation_config = GenerationConfig( temperature=temperature, top_p=top_p, top_k=top_k, num_beams=num_beams, **kwargs, ) generate_params = { "input_ids": input_ids, "generation_config": generation_config, "return_dict_in_generate": True, "output_scores": True, "max_new_tokens": max_new_tokens, } स्ट्रीमिंग और गैर-स्ट्रीमिंग जेनरेशन मोड के लिए फ़ंक्शन परिभाषित करें: if stream_output: # streaming ... # Without streaming with torch.no_grad(): generation_output = model.generate( input_ids=input_ids, generation_config=generation_config, return_dict_in_generate=True, output_scores=True, max_new_tokens=max_new_tokens, ) s = generation_output.sequences[0] output = tokenizer.decode(s) yield prompter.get_response(output) मॉडल का परीक्षण करने के लिए ग्रेडियो सर्वर प्रारंभ करें: gr.Interface( ... पहला प्रयास प्रोजेक्ट के ने कहा कि निम्नलिखित फाइन-ट्यून सेटिंग्स स्टैनफोर्ड अल्पाका के तुलनीय प्रदर्शन के साथ LLaMA 7B का उत्पादन करती हैं। हगिंगफेस पर एक साझा किया गया था। README.md "आधिकारिक" अल्पाका-लोरा वजन python finetune.py \ --base_model='decapoda-research/llama-7b-hf' \ --num_epochs=10 \ --cutoff_len=512 \ --group_by_length \ --output_dir='./lora-alpaca' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --lora_r=16 \ --micro_batch_size=8 हालाँकि, मेरे अनुभव में, इससे कोई उपयोगी मॉडल नहीं मिला। इसे V100 पर चलाने से निम्नलिखित शो-स्टॉपिंग समस्याएं सामने आएंगी: मॉडल को के साथ लोड करने से डेटा प्रकार में त्रुटि होती है। load_in_8bit एक बाइंडिंग स्क्रिप्ट के कारण PEFT एक अमान्य एडॉप्टर उत्पन्न करेगा। अमान्य एडॉप्टर मूल LLaMA मॉडल में कोई बदलाव नहीं करता है और केवल अस्पष्टता पैदा करता है। मॉडल ने स्पष्ट रूप से गलत टोकननाइज़र का उपयोग किया। इसका पैड टोकन, बॉस टोकन और ईओएस टोकन एलएलएएमए के आधिकारिक टोकननाइज़र से अलग हैं। decapoda-research/llama-7b-hf जैसा कि पहले उल्लेख किया गया है, V100 में int8/fp16 मिश्रित प्रशिक्षण के लिए उचित समर्थन का अभाव है। यह अप्रत्याशित व्यवहार का कारण बनता है, जैसे और । training loss = 0.0 eval loss = NaN चारों ओर खोजबीन करने और कई वीएम घंटे बर्बाद करने के बाद, मुझे एक ही वी100 पर प्रशिक्षण कार्य करने के लिए आवश्यक परिवर्तन मिले। ... # do not use decapoda-research/llama-7b-hf as base_model. use a huggingface LLaMA model that was properly converted and has a correct tokenizer, eg, yahma/llama-7b-hf or huggyllama/llama-7b. # decapoda-research/llama-7b-hf is likely to cause overflow/underflow on V100. train loss goes to 0 and eval loss becomes NaN. using yahma/llama-7b-hf or huggyllama/llama-7b somehow mitigates this issue model = LlamaForCausalLM.from_pretrained( base_model, load_in_8bit=True, # only work for 7B LLaMA. On a V100, set True to save some VRAM at the cost of slower training; set False to speed up training at the cost of more VRAM / smaller micro batch size torch_dtype=torch.float16, device_map=device_map, ) ... # comment out the following line if load_in_8bit=False model = prepare_model_for_int8_training(model) ... # set legacy=False to avoid unexpected tokenizer behavior. make sure no tokenizer warning was raised during tokenizer instantiation tokenizer = LlamaTokenizer.from_pretrained(base_model, legacy=False) ... # the following binding script results in invalid adapter. simply comment them out old_state_dict = model.state_dict model.state_dict = ( lambda self, *_, **__: get_peft_model_state_dict( self, old_state_dict() ) ).__get__(model, type(model)) ... # if load_in_8bit=True, need to cast data type during training with torch.autocast('cuda'): trainer.train(resume_from_checkpoint=resume_from_checkpoint) ये परिवर्तन करने के बाद, ये प्रशिक्षण तर्क एक प्रयोग करने योग्य मॉडल तैयार करते हैं। { "args": [ "--base_model", "yahma/llama-7b-hf", "--num_epochs=10", "--data_path", "yahma/alpaca-cleaned", "--output_dir", "./your output dir", "--cutoff_len=512", "--lora_target_modules=[q_proj,k_proj,v_proj,o_proj]", "--lora_r=16", "--micro_batch_size=2", "--batch_size=16", "--wandb_project", "your wandb project name" ], } ध्यान दें कि प्रशिक्षण स्क्रिप्ट न केवल "सर्वोत्तम" मॉडल (न्यूनतम ईवल हानि के साथ चेकपॉइंट) को बचाती है, बल्कि कुछ चेकपॉइंट्स को भी बचाती है। मैंने आगे के विश्लेषण के लिए प्रशिक्षण/नुकसान का मूल्यांकन करने के लिए wandb का उपयोग किया। पहला अवलोकन मैं सुव्यवस्थित मॉडल पर कुछ यादृच्छिक प्रश्न डालता हूँ। यह कुछ उचित प्रतिक्रियाएँ उत्पन्न करता है। यहाँ एक उदाहरण है: निर्देश: उपयोगकर्ता के प्रश्न का उत्तर सावधानी से दें। इनपुट: जब आप स्विचगियर सर्किट ब्रेकर ट्रक को रैक से निकालते हैं तो क्या होता है? प्रतिक्रिया: जब एक स्विचगियर सर्किट ब्रेकर ट्रक को "रैक आउट" किया जाता है, तो इसका मतलब है कि ट्रक के सभी सर्किट ब्रेकर खुल गए हैं और ट्रक गैर-ऊर्जावान स्थिति में है। यह आम तौर पर तब किया जाता है जब ट्रक की सेवा, मरम्मत या निरीक्षण किया जा रहा हो। एक बार जब सर्किट ब्रेकरों को रैक कर दिया जाता है, तो ट्रक पर काम करना सुरक्षित होता है और आवश्यक रखरखाव या मरम्मत पूरी होने के बाद इसे फिर से सक्रिय किया जा सकता है। यह उदाहरण एलएलएम के आंतरिक ज्ञान पर सवाल उठाता है। ऐसा लगता है कि मॉडल को स्विचगियर्स के बारे में बहुत कुछ पता था। हालाँकि, जब मैंने अनुभवजन्य रूप से इसकी तर्क क्षमता का परीक्षण करने की कोशिश की, तो इसने एक बहुत ही अजीब परिणाम दिया: निर्देश: किसी प्रोजेक्ट के बारे में नीचे दी गई जानकारी देते हुए प्रश्नों के उत्तर दें। चीनी-लामा-2 परियोजना का लक्ष्य बड़े भाषा मॉडल लामा-2 की चीनी भाषा में समझ, निर्माण, अनुवाद क्षमताओं को बढ़ाना है। लोआरए फाइन-ट्यूनिंग, फुल-पैरामीटर इंस्ट्रक्शन फाइन-ट्यूनिंग और सेकेंडरी प्री-ट्रेनिंग जैसी विधियों के अनुप्रयोग के साथ, हम आपको संबंधित डेटासेट, प्रशिक्षण गाइड और मॉडल पैरामीटर को डाउनलोड करने और उपयोग करने के लिए सौहार्दपूर्वक आमंत्रित करते हैं। इनपुट: इस परियोजना में किन विधियों का उपयोग किया जाता है? प्रतिक्रिया: चीनी-लामा-2 परियोजना का लक्ष्य बड़े भाषा मॉडल लामा-2 की चीनी भाषा में समझ, निर्माण, अनुवाद क्षमताओं को बढ़ाना है। लोआरए फाइन-ट्यूनिंग, फुल-पैरामीटर इंस्ट्रक्शन फाइन-ट्यूनिंग और सेकेंडरी प्री-ट्रेनिंग जैसी विधियों के अनुप्रयोग के साथ, हम आपको संबंधित डेटासेट, प्रशिक्षण गाइड और मॉडल पैरामीटर को डाउनलोड करने और उपयोग करने के लिए सौहार्दपूर्वक आमंत्रित करते हैं।</s> जैसा कि आप देख सकते हैं, मॉडल प्रॉम्प्ट को दोहराना पसंद करता है। मैं इसे मॉडल कहता हूं, और अन्य डेवलपर्स भी में इस व्यवहार की रिपोर्ट कर रहे थे। प्रश्नों का उत्तर देने की इसकी क्षमता अधिक सावधानी से डिज़ाइन किए गए संकेतों के साथ बेहतर होती जाती है। यह व्यवहार वह नहीं है जो हम उत्पादन प्रणाली में चाहते हैं, क्योंकि हम विभिन्न मॉडलों में त्वरित प्रभावशीलता की गारंटी नहीं दे सकते। मॉडलों को संकेतों के प्रति कम संवेदनशील होना होगा। हम किसी तरह इस एलएलएम के प्रदर्शन में सुधार करना चाहते हैं। प्रॉम्प्ट-रिपीटर रेपो मुद्दों अगले सत्र में, मैं चर्चा करूंगा कि इस समस्या का कारण क्या है और फाइन-ट्यूनिंग परिणामों को कैसे सुधारा जाए। दूसरा प्रयास और (कुछ हद तक) सफलता फ़ाइन-ट्यूनिंग परिणाम को बेहतर बनाने के लिए मैंने यहां तीन चीज़ें दी हैं: संकेतों पर नुकसान को छुपाएं (त्वरित पुनरावृत्ति से बचने में मदद करता है) विकल्प बंद करें (प्रदर्शन को बेहतर बनाने में मदद करता है, हानि वक्र को आसान बनाता है) group-by-length ईवल लॉस कर्व पर भरोसा न करें। ऐसे चेकपॉइंट का उपयोग करें जिसमें कम प्रशिक्षण हानि हो, भले ही इसका मूल्यांकन नुकसान "सर्वोत्तम" चेकपॉइंट से अधिक हो सकता है। (प्रदर्शन को बेहतर बनाने में मदद करता है, क्योंकि ईवल लॉस यहां सबसे अच्छा मैट्रिक्स नहीं है) आइये इन 3 बिंदुओं को एक-एक करके समझाते हैं। संकेत मिलने पर नुकसान छुपाएं मैं त्वरित पुनरावृत्ति के कारणों की तलाश कर रहा था जब तक कि मुझे यह और नहीं मिला। उन्होंने सुझाव दिया कि नुकसान की गणना में संकेतों को बाहर रखा जाना चाहिए। मूलतः, आप मॉडल को प्रॉम्प्ट टोकन आउटपुट के लिए प्रोत्साहित नहीं करना चाहते। प्रशिक्षण के दौरान संकेतों को छिपाने से मॉडल को शीघ्र टोकन दोहराने के लिए प्रोत्साहित नहीं किया जाएगा। नीचे दिया गया चार्ट इसे समझाता है: 3 प्रशिक्षण रन में से, एकमात्र रन है जो प्रशिक्षण के दौरान संकेतों को छिपा नहीं पाता है। इस प्रकार शुरुआत में इसका प्रशिक्षण नुकसान अधिक होता है। मुझे संदेह है कि यदि नुकसान की गणना करते समय संकेतों को छुपाया नहीं जाता है, और प्रशिक्षण अपर्याप्त है, तो मॉडल में निर्देशों का पालन करने के बजाय संकेतों को दोहराने की अधिक संभावना होगी। पोस्ट आधिकारिक लोरा वेट कमिट संदेश stoic-star-6 ए) बी) स्रोत कोड में, प्रॉम्प्ट टोकन को -100 पर सेट करके हानि मास्किंग की जाती है: पर सेट सूचकांक वाले टोकन को नजरअंदाज कर दिया जाता है (नकाब लगाया जाता है), नुकसान की गणना केवल में लेबल वाले टोकन के लिए की जाती है। -100 [0, ..., config.vocab_size] विकल्प बंद करें group-by-length विकल्प हगिंगफेस के समान लंबाई के इनपुट को बैचों में समूहित करने की अनुमति देता है। यह इनपुट अनुक्रमों को पैडिंग करते समय वीआरएएम उपयोग को बचाने में मदद करता है। हालाँकि, यह एक ही बैच के भीतर नमूना भिन्नता को काफी कम कर देगा। प्रशिक्षण प्रक्रिया के दौरान, हम आम तौर पर मॉडल को विभिन्न प्रकार के प्रशिक्षण नमूनों के सामने उजागर करना पसंद करते हैं। पर सेट करने से नमूना भिन्नता कम हो जाती है। यह प्रशिक्षण के दौरान नुकसान में उतार-चढ़ाव का कारण बनता है (उदाहरण के लिए, दो लगातार बैचों की गद्देदार लंबाई 10 और 50 है। छोटे बैच में कम नुकसान होता है, और लंबे बैच में अधिक नुकसान होता है। इसके परिणामस्वरूप एक दोलनशील नुकसान वक्र होता है, जैसा कि चित्र में दिखाया गया है नीचे)। group-by-length Trainer group-by-length False दूसरी ओर, चूंकि इन-बैच नमूना भिन्नता को कम करती है, मुझे संदेह है कि मॉडल का प्रदर्शन भी इससे प्रभावित हो सकता है। नीचे दिया गया आंकड़ा के साथ या उसके बिना प्रशिक्षण हानि की तुलना करता है। यह स्पष्ट है कि रन के लिए औसत हानि अधिक है, जिसमें सक्षम है। group-by-length group-by-length peach-violet-19 group-by-length ईवल लॉस कर्व पर भरोसा न करें मैंने देखा कि मेरे सभी रनों में प्रशिक्षण हानि और ईवल हानि अलग-अलग हैं। यहाँ एक उदाहरण है: इस उदाहरण में, इष्टतम चेकपॉइंट के आसपास होता है। यदि आप मूल द्वारा सुझाए गए इष्टतम चेकपॉइंट को लोड करते हैं, तो आपको पिछले सत्र में उल्लिखित मॉडल मिलने की संभावना है। epoch=2 रेपो प्रॉम्प्ट-रिपीटर प्रशिक्षण के अंत में एक मॉडल चेकपॉइंट लोड करके, मुझे एक अधिक प्रदर्शन करने वाला मॉडल मिला। मैंने पहले जैसा ही प्रश्न पूछा और मॉडल ने सही उत्तर दिया: निर्देश: किसी प्रोजेक्ट के बारे में नीचे दी गई जानकारी देते हुए प्रश्नों के उत्तर दें। चीनी-लामा-2 परियोजना का लक्ष्य बड़े भाषा मॉडल लामा-2 की चीनी भाषा में समझ, निर्माण, अनुवाद क्षमताओं को बढ़ाना है। लोआरए फाइन-ट्यूनिंग, फुल-पैरामीटर इंस्ट्रक्शन फाइन-ट्यूनिंग और सेकेंडरी प्री-ट्रेनिंग जैसी विधियों के अनुप्रयोग के साथ, हम आपको संबंधित डेटासेट, प्रशिक्षण गाइड और मॉडल पैरामीटर को डाउनलोड करने और उपयोग करने के लिए सौहार्दपूर्वक आमंत्रित करते हैं। इनपुट: इस परियोजना में किन विधियों का उपयोग किया जाता है? प्रतिक्रिया: चीनी-लामा-2 परियोजना लोआरए फाइन-ट्यूनिंग, पूर्ण-पैरामीटर निर्देश फाइन-ट्यूनिंग और माध्यमिक पूर्व-प्रशिक्षण जैसी विधियों का उपयोग करती है।</s> लेकिन मूल्यांकन हानि को देखते हुए, इस मॉडल को और भी खराब प्रदर्शन करना चाहिए। दुविधा का कारण क्या है? मुझे लगता है कि बड़े भाषा मॉडल के प्रदर्शन को मापने के लिए मूल्यांकन हानि एक अच्छा मैट्रिक्स नहीं है। एलएलएएमए प्रशिक्षण और मूल्यांकन हानि के लिए का उपयोग करता है: CrossEntropyLoss # modelling_llama.py from transformers library ... # forward function under LlamaForCausalLM class if labels is not None: # Shift so that tokens < n predict n shift_logits = logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() # Flatten the tokens loss_fct = CrossEntropyLoss() loss = loss_fct(shift_logits.view(-1, self.config.vocab_size), shift_labels.view(-1)) मूल्यांकन सेट पर परीक्षण करते समय, एक मॉडल अलग-अलग शब्दों के साथ एक ही उत्तर दे सकता है: { "evaluation prompt": "What is 1 + 3?" "evaluation answer": "4." "prediction answer": "The answer is 4." } दोनों उत्तर सही हैं, लेकिन यदि पूर्वानुमानित उत्तर मूल्यांकन उत्तर से सटीक मेल नहीं खाता है, तो मूल्यांकन हानि अधिक होगी। इस मामले में, हमें मॉडल के प्रदर्शन को मापने के लिए एक बेहतर मूल्यांकन मैट्रिक्स की आवश्यकता है। उचित मूल्यांकन की चिंता हम बाद में करेंगे. अभी के लिए, आइए मान लें कि सबसे अच्छा मॉडल वह है जिसमें सबसे कम प्रशिक्षण हानि हो। 7बी से आगे जाना मैंने V100 पर 13B मॉडल को फ़ाइन-ट्यूनिंग करने का प्रयास किया। जबकि V100 7B मॉडल पर int8 और fp16 दोनों प्रशिक्षण को संभाल सकता है, यह 13B मॉडल पर int8 प्रशिक्षण को संभाल नहीं सकता है। यदि , तो 13B मॉडल उत्पन्न करेगा। ऐसा क्यों होता है यह समझने के लिए हम कुछ डिबगिंग टूल का उपयोग कर सकते हैं ( यह ओवरफ्लो/अंडरफ्लो के कारण होता है)। load_int_8bit = True training_loss = 0.0 स्पॉइलर अलर्ट: मैंने प्रशिक्षण के दौरान मापदंडों का निरीक्षण करने के लिए हगिंगफेस के टूल का उपयोग किया। पहले फॉरवर्ड पास में, इसने inf/nan मानों का पता लगाया: DebugUnderflowOverflow अधिक विशेष रूप से, के दूसरे इनपुट में नकारात्मक अनंत मानों को पकड़ा, जैसा कि नीचे दिए गए चित्र में दिखाया गया है। दूसरा इनपुट है। मैंने थोड़ा और गहराई में जाकर पाया कि पैडिंग तत्वों के लिए बहुत बड़े नकारात्मक मान होने चाहिए। संयोगवश, नकारात्मक अनंत मान प्रत्येक अनुक्रम की शुरुआत में हैं। यह अवलोकन मुझे विश्वास दिलाता है कि इस परत पर नकारात्मक अनंत मान घटित होने चाहिए। आगे की जांच से यह भी पता चला कि अनंत मानों के कारण अगली कुछ परतों में अधिक अनंत मान नहीं बने। इसलिए, पर अतिप्रवाह संभवतः असामान्य प्रशिक्षण हानि का मूल कारण नहीं है। DebugUnderflowOverflow LlamaDecoderLayer attention_mask attention_mask LlamaDecoderLayer इसके बाद, मैंने प्रत्येक परत के आउटपुट का निरीक्षण किया। यह बहुत स्पष्ट था कि अंतिम परतों के आउटपुट ओवरफ्लो हो रहे हैं, जैसा कि नीचे दिए गए चित्र में दिखाया गया है। मेरा मानना है कि यह int-8 वज़न की सीमित परिशुद्धता (या 16 की सीमित सीमा) के कारण होता है। यह संभावना है कि इस समस्या से बच सकता है। float16 bfloat16 अतिप्रवाह समस्या को हल करने के लिए, मैंने प्रशिक्षण के दौरान फ्लोट16 का उपयोग किया। V100 में 13B मॉडल के प्रशिक्षण के लिए पर्याप्त VRAM नहीं है जब तक कि कुछ तरकीबों का उपयोग न किया गया हो। प्रशिक्षण वीआरएएम उपयोग को कम करने के लिए सीपीयू ऑफलोडिंग जैसे कई तरीके प्रदान करता है। लेकिन सबसे सरल तरकीब प्रशिक्षण शुरू होने से पहले को कॉल करके ग्रेडिएंट चेकपॉइंटिंग को सक्षम करना है। हगिंग फेस डीपस्पीड model.gradient_checkpointing_enable() ग्रेडिएंट चेकपॉइंटिंग कम वीआरएएम उपयोग के लिए प्रशिक्षण गति को बंद कर देती है। आमतौर पर, फॉरवर्ड पास के दौरान, सक्रियणों की गणना की जाती थी और बैकवर्ड पास के दौरान उपयोग के लिए मेमोरी में संग्रहीत किया जाता था। यह अतिरिक्त मेमोरी लेता है. हालाँकि, ग्रेडिएंट चेकपॉइंटिंग के साथ, फॉरवर्ड पास के दौरान सक्रियणों को संग्रहीत करने के बजाय, उन्हें बैकवर्ड पास के दौरान फिर से गणना की जाती है, इस प्रकार वीआरएएम की बचत होती है। इस तकनीक के बारे में यहां एक अच्छा है। लेख मैं फ्लोट16 और ग्रेडिएंट चेकपॉइंटिंग सक्षम के साथ लामा 13बी को प्रशिक्षित करने में सक्षम था: python finetune.py \ --base_model=yahma/llama-13b-hf \ --num_epochs=10 \ --output_dir 'your/output/dir' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --cutoff_len=1024 \ --lora_r=16 \ --micro_batch_size=4 \ --batch_size=128 \ --wandb_project 'alpaca_lora_13b' \ --train_on_inputs=False 13बी मॉडल नाम इकाई पहचान जैसे कुछ उन्नत कार्यों को संभाल सकता है। मैं परीक्षण के लिए उपयोग करता हूं और यह 13बी मॉडल की सटीक प्रतिक्रिया है: एक उदाहरण संकेत का सब अच्छा है! यह एक रोमांचक शुरुआत है. मॉडल हमें लैंगचेन के साथ जटिल एप्लिकेशन बनाने की अनुमति देता है। इस बिंदु पर, हमारे पास अभी भी स्वचालित मॉडल मूल्यांकन के लिए उपकरण गायब हैं। हम कई परीक्षण मामलों पर अपने मॉडलों का मूल्यांकन करने के लिए भाषा मॉडल मूल्यांकन हार्नेस का उपयोग कर सकते हैं, या यहां तक कि अपने स्वयं के परीक्षण मामले भी बना सकते हैं। यह वही टूल है जिसका उपयोग हगिंग फेस अपने ओपन एलएलएम लीडरबोर्ड के लिए करता है। जबकि मूल्यांकन एलएलएम विकास का एक महत्वपूर्ण पहलू है, यह लेख पूरी तरह से प्रशिक्षण प्रक्रिया पर केंद्रित है। मैं भविष्य के लेख में मूल्यांकन पर चर्चा कर सकता हूं। सारांश इस लेख में, हमने बड़े फाउंडेशन मॉडल (एलएफएम) की अवधारणा और कई फाइन-ट्यूनिंग विधियों को पेश किया है जो एलएफएम को वांछित व्यवहार करते हैं। फिर हमने एलएफएम को फाइन-ट्यूनिंग के लिए एक पैरामीटर-कुशल विधि लोआरए पर ध्यान केंद्रित किया, और फाइन-ट्यूनिंग कोड के साथ-साथ प्रदर्शन सुधार तकनीकों को भी समझाया। अंत में, हम एक कदम आगे बढ़े और V100 GPU पर Llama 13B मॉडल को सफलतापूर्वक प्रशिक्षित किया। हालाँकि 13बी मॉडल प्रशिक्षण में कुछ समस्याएँ आईं, हमने पाया कि ये समस्याएँ हार्डवेयर सीमाओं के कारण उत्पन्न हुई थीं और समाधान प्रस्तुत किए गए। अंत में, हमें एक बेहतर एलएलएम मिला जो काम करता है, लेकिन हमने अभी तक एलएलएम के प्रदर्शन का मात्रात्मक मूल्यांकन नहीं किया है। लेखक के बारे में नमस्ते! मेरा नाम वेई है. मैं एक समर्पित समस्या समाधानकर्ता, में वरिष्ठ एआई विशेषज्ञ और एनालिटिक्स प्रोजेक्ट लीड और हूं। मेरे पास मिनेसोटा ट्विन सिटीज़ विश्वविद्यालय से मैकेनिकल इंजीनियरिंग में एमएस और अर्बाना-शैंपेन में इलिनोइस विश्वविद्यालय से मैकेनिकल इंजीनियरिंग में बीएस की डिग्री है। एबीबी मशीन लर्निंग Google डेवलपर विशेषज्ञ मेरा टेक स्टैक पायथन/सी# प्रोग्रामिंग, कंप्यूटर विज़न, मशीन लर्निंग, एल्गोरिदम और माइक्रो-सर्विसेज पर केंद्रित है, लेकिन मेरे पास गेम डेवलपमेंट (यूनिटी), फ्रंट/बैक-एंड डेवलपमेंट, तकनीकी नेतृत्व जैसे व्यापक हित भी हैं। सिंगल बोर्ड कंप्यूटर और रोबोटिक्स के साथ छेड़छाड़। मुझे उम्मीद है कि यह लेख किसी तरह से लोगों की मदद कर सकता है। पढ़ने के लिए धन्यवाद, और समस्या-समाधान का आनंद लें!