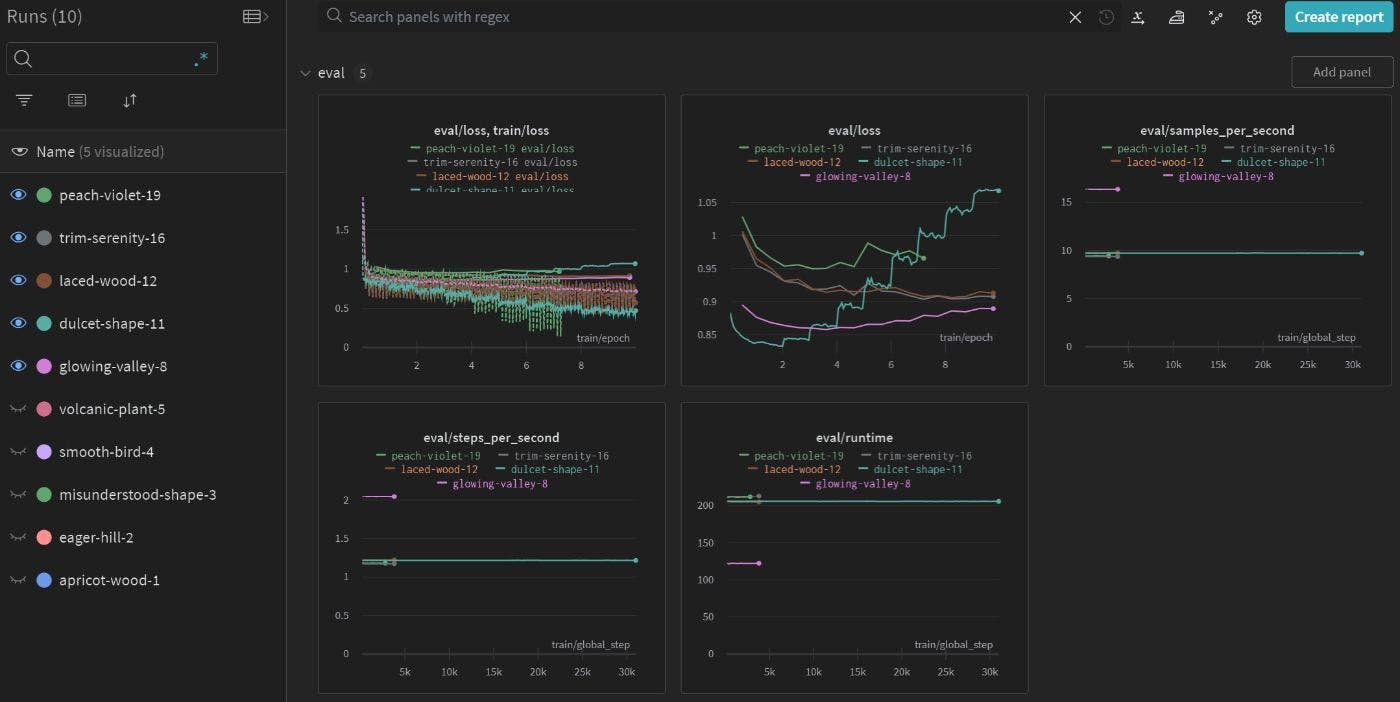
(LLM) стали модным словом в разработке программного обеспечения с момента выпуска ChatGPT. Его способность вести естественный диалог с людьми — лишь верхушка айсберга. Усовершенствованные такими инструментами, как LangChain или Semantic Kernel, LLM могут полностью изменить способ взаимодействия пользователей с программным обеспечением. Другими словами, LLM могут обеспечить синергию между функциями и источниками данных и обеспечить более эффективный и интуитивно понятный пользовательский интерфейс. Большие языковые модели Например, многие люди уже используют инструменты создания контента на основе искусственного интеллекта для своих следующих вирусных видеороликов. Типичный конвейер производства видео включает в себя написание сценариев, логистику, раскадровку, монтаж и маркетинг, и это лишь некоторые из них. Чтобы упростить процесс, LLM может помочь создателям контента проводить исследования при написании сценариев, приобретать реквизит для съемок, создавать раскадровки на основе сценария (возможно, потребуется стабильное распространение для создания изображений), облегчать процесс редактирования и писать привлекательный заголовок. /видеоописания для привлечения просмотров в социальных сетях. LLM — это ядро, которое организует все это, но при включении LLM в программный продукт может возникнуть несколько проблем: Если я буду использовать API OpenAI, стану ли я слишком зависим от этого сервиса? Что, если они поднимут цену? Что, если они изменят доступность услуги? Мне не нравится, как OpenAI подвергает цензуре контент или предоставляет неконструктивную обратную связь на определенные действия пользователя. (Или наоборот: мне не нравится, как цензура OpenAI игнорирует некоторые вещи, которые чувствительны в моем случае использования.) Если мои клиенты предпочитают частное облако или локальное развертывание, какие альтернативы у меня есть? ChatGPT Я просто хочу иметь контроль. Мне нужно настроить LLM, и я хочу, чтобы это было дешево. Именно из-за этих проблем мне интересно, может ли существовать эквивалент моделей OpenAI GPT с открытым исходным кодом. К счастью, замечательные сообщества открытого исходного кода уже делятся некоторыми очень многообещающими решениями. Я решил попробовать , эффективный по параметрам метод точной настройки для обучения вашего собственного LLM. В этом сообщении блога обсуждается процесс, проблемы, с которыми я столкнулся, как я их решил и что может произойти дальше. Если вы также хотите использовать эту технику для обучения собственному LLM, я надеюсь, что эта информация вам поможет. alpaca-lora Давай начнем! Обзор контента Что такое LLaMA, альпака и LoRA? Эксперимент по точной настройке Быстрое сканирование исходного кода Первая попытка Первое наблюдение Вторая попытка и (отчасти) успех Выход за пределы 7B Краткое содержание Что такое LLaMA, альпака и LoRA? — это коллекция базовых языковых моделей от Meta AI. Эти авторегрессионные модели имеют число параметров от 7B до 65B, и их можно использовать только в исследовательских целях. Meta недавно выпустила , которую можно использовать в коммерческих целях с некоторыми ограничениями. Что делает семейство моделей LLaMA особенным, так это его тренировочный корпус и производительность. Мета утверждает, что LLaMA обучается на общедоступных наборах данных. Его вариант 13B обеспечивает производительность, сравнимую с GPT-3 (модель 175B) в большинстве тестов. LLaMA LLaMA 2 — это попытка Стэнфорда создать LLM, выполняющий инструкции, на основе LLaMA. Это работает следующим образом: alpaca Попросите языковую модель сгенерировать тройки инструкция-ввод-ответ. Используйте сгенерированные данные для тонкой настройки LLaMA. После тонкой настройки LLaMA может следовать инструкциям пользователя и реагировать соответствующим образом. Вот сравнение ответа стандартного LLaMA и точно настроенного ответа LLaMA: { "instruction": "Answer user's question.", "input": "Can you put a medium voltage circuit breaker in a low voltage switchgear? Why? Explain in detail.", "vanilla LLaMA": { "answer": "Yes, you can put a medium voltage circuit breaker in a low voltage switchgear. The medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put....(repetition continues)" }, "fine-tuned LLaMA": { "answer": "No, it is not possible to put a medium voltage circuit breaker in a low voltage switchgear. This is because low voltage switchgear is designed to handle voltages up to 1 kV, while medium voltage switchgear is designed to handle voltages from 1 kV to 38 kV. The circuit breakers, contacts, and other components in low voltage switchgear are not suitable for the higher voltages and currents of medium voltage switchgear. Using a medium voltage circuit breaker in a low voltage switchgear could result in damage to the components and could pose a safety hazard." } } Как видите, точная настройка меняет поведение LLM довольно радикально. Ванильная модель застряла в цикле повторения. Хотя точно настроенная модель не дала на 100% правильный ответ, по крайней мере, ее ответ — громкое «Нет». Точная настройка является необходимым шагом для создания пригодного к использованию LLM. Во многих случаях достаточно развертывания точно настроенного LLM с открытым исходным кодом. Однако в некоторых конкретных случаях использования в бизнесе может быть предпочтительнее точно настроить модели на наборах данных, специфичных для конкретной предметной области. Самый большой недостаток альпаки — ее потребность в ресурсах. На его странице GitHub указано, что: По идее, для точной настройки модели 7B требуется около 7 x 4 x 4 = 112 ГБ видеопамяти. Это больше видеопамяти, чем может обработать графический процессор A100 80 ГБ. Мы можем обойти требование VRAM, используя . LoRA LoRA работает следующим образом: Выберите несколько весов в модели, например вес проекции запроса $W_q$ в модели преобразователя. Добавьте (да, арифметическое сложение) веса адаптера к выбранным весам. Заморозьте исходную модель, тренируйте только добавленный вес. Добавленный вес имеет некоторые особые свойства. Вдохновленный этой , Эдвард Ху и др. показал, что для исходного веса модели $W_o\in R^{d \times k}$ можно создать точно настроенный вес $W_o'=W_o+BA$ для последующих задач, где $B\in R^{d \times r}$ , $A \in R^{r \times k}$ и $r\ll min(d, k)$ — это «внутренний ранг» веса адаптера. Важно установить правильное значение $r$ для веса адаптера, поскольку меньшее значение $r$ снижает производительность модели, а большее значение $r$ увеличивает размер веса адаптера без пропорционального увеличения производительности. статьей Этот метод аналогичен усеченному SVD, который аппроксимирует матрицу, разлагая ее на несколько меньших матриц и сохраняя только несколько наибольших сингулярных значений. Предполагая, что $W_o\in R^{100 \times 100}$, полная точная настройка изменит 10 000 параметров. Точная настройка LoRA с $r=8$ разложит точно настроенный вес на две части: $B\in R^{100 \times 8}$ и $A\in R^{8 \times 100}$, каждая часть содержит 800 параметров (всего 1600 параметров). Количество обучаемых параметров уменьшено в 6,25 раза. После преобразования модели с помощью LoRA мы получили модель, которая имеет только ~1% обучаемых весов, однако в некоторых областях ее производительность значительно улучшена. Это позволит нам обучать модели 7B или 13B на более доступном оборудовании, таком как RTX 4090 или V100. Эксперимент по точной настройке Я провел эксперимент на Huawei Cloud с экземпляром виртуальной машины с графическим ускорением ( , 8vCPU, 64 ГБ ОЗУ, 1x V100 32 ГБ видеопамяти). Известно, что V100 не поддерживает тип данных bfloat16, а его тензорное ядро не поддерживает int8. ускорение. Эти два ограничения могут замедлить обучение смешанной точности и вызвать числовое переполнение во время обучения смешанной точности. Мы учтем это для дальнейшего обсуждения. p2s.2xlarge Быстрое сканирование исходного кода — это ядро проекта. Первый скрипт настраивает модели LLaMA, а второй скрипт использует точно настроенную модель для общения с пользователями. Давайте сначала посмотрим на основной поток : finetune.py generate.py finetune.py загрузка предварительно обученной большой модели фундамента model = LlamaForCausalLM.from_pretrained( base_model, # name of a huggingface compatible LLaMA model load_in_8bit=True, torch_dtype=torch.float16, device_map=device_map, ) загрузить токенизатор модели tokenizer = LlamaTokenizer.from_pretrained(base_model) tokenizer.pad_token_id = ( 0 # unk. we want this to be different from the eos token ) tokenizer.padding_side = "left" # Allow batched inference на основе шаблона обучения подготовьте входные данные модели с помощью двух функций: . tokenize generate_and_tokenize_prompt создать адаптированную модель LoRA, используя Huggingface PEFT config = LoraConfig( r=lora_r, # the lora rank lora_alpha=lora_alpha, # a weight scaling factor, think of it like learning rate target_modules=lora_target_modules, # transformer modules to apply LoRA to lora_dropout=lora_dropout, bias="none", task_type="CAUSAL_LM", ) model = get_peft_model(model, config) создайте экземпляр тренера и начните обучение trainer = transformers.Trainer( model=model, train_dataset=train_data, eval_dataset=val_data, args=transformers.TrainingArguments( ... Это довольно просто. В конце скрипт создает папку модели с контрольными точками, весами адаптеров и конфигурацией адаптера. Далее давайте посмотрим на основной поток generate.py : Модель нагрузки и вес адаптера model = LlamaForCausalLM.from_pretrained( base_model, device_map={"": device}, torch_dtype=torch.float16, ) model = PeftModel.from_pretrained( model, lora_weights, device_map={"": device}, torch_dtype=torch.float16, ) указать конфигурацию генерации generation_config = GenerationConfig( temperature=temperature, top_p=top_p, top_k=top_k, num_beams=num_beams, **kwargs, ) generate_params = { "input_ids": input_ids, "generation_config": generation_config, "return_dict_in_generate": True, "output_scores": True, "max_new_tokens": max_new_tokens, } определить функции для потокового и непотокового режима генерации: if stream_output: # streaming ... # Without streaming with torch.no_grad(): generation_output = model.generate( input_ids=input_ids, generation_config=generation_config, return_dict_in_generate=True, output_scores=True, max_new_tokens=max_new_tokens, ) s = generation_output.sequences[0] output = tokenizer.decode(s) yield prompter.get_response(output) Запустите сервер Gradio, чтобы протестировать модель: gr.Interface( ... Первая попытка В проекта указано, что следующие настройки позволяют получить LLaMA 7B с производительностью, сравнимой со Стэнфордской альпакой. На обнимающемся лице был указан . README.md «официальный» вес альпака-лоры python finetune.py \ --base_model='decapoda-research/llama-7b-hf' \ --num_epochs=10 \ --cutoff_len=512 \ --group_by_length \ --output_dir='./lora-alpaca' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --lora_r=16 \ --micro_batch_size=8 Однако, по моему опыту, это не привело к созданию пригодной для использования модели. Запустив его на V100, вы столкнетесь со следующими серьезными проблемами: загрузка модели с помощью приводит к ошибке типа данных. load_in_8bit сценарий привязки приведет к тому, что PEFT создаст недопустимый адаптер. Недопустимый адаптер не вносит изменений в исходную модель LLaMA и выдает только тарабарщину. модель очевидно, использовала неправильный токенизатор. Его токен Pad, токен bos и токен eos отличаются от официального токенизатора LLaMA. decapoda-research/llama-7b-hf как упоминалось ранее, в V100 отсутствует надлежащая поддержка смешанного обучения int8/fp16. Это приводит к неожиданному поведению, например и . training loss = 0.0 eval loss = NaN Покопавшись и потратив множество часов виртуальной машины, я нашел необходимые изменения, чтобы обучение работало на одном V100. ... # do not use decapoda-research/llama-7b-hf as base_model. use a huggingface LLaMA model that was properly converted and has a correct tokenizer, eg, yahma/llama-7b-hf or huggyllama/llama-7b. # decapoda-research/llama-7b-hf is likely to cause overflow/underflow on V100. train loss goes to 0 and eval loss becomes NaN. using yahma/llama-7b-hf or huggyllama/llama-7b somehow mitigates this issue model = LlamaForCausalLM.from_pretrained( base_model, load_in_8bit=True, # only work for 7B LLaMA. On a V100, set True to save some VRAM at the cost of slower training; set False to speed up training at the cost of more VRAM / smaller micro batch size torch_dtype=torch.float16, device_map=device_map, ) ... # comment out the following line if load_in_8bit=False model = prepare_model_for_int8_training(model) ... # set legacy=False to avoid unexpected tokenizer behavior. make sure no tokenizer warning was raised during tokenizer instantiation tokenizer = LlamaTokenizer.from_pretrained(base_model, legacy=False) ... # the following binding script results in invalid adapter. simply comment them out old_state_dict = model.state_dict model.state_dict = ( lambda self, *_, **__: get_peft_model_state_dict( self, old_state_dict() ) ).__get__(model, type(model)) ... # if load_in_8bit=True, need to cast data type during training with torch.autocast('cuda'): trainer.train(resume_from_checkpoint=resume_from_checkpoint) После внесения этих изменений эти аргументы обучения создают полезную модель. { "args": [ "--base_model", "yahma/llama-7b-hf", "--num_epochs=10", "--data_path", "yahma/alpaca-cleaned", "--output_dir", "./your output dir", "--cutoff_len=512", "--lora_target_modules=[q_proj,k_proj,v_proj,o_proj]", "--lora_r=16", "--micro_batch_size=2", "--batch_size=16", "--wandb_project", "your wandb project name" ], } Обратите внимание, что обучающий скрипт сохраняет не только «лучшую» модель (контрольную точку с наименьшей потерей оценки), но и пару контрольных точек. Я использовал wandb для регистрации потерь при обучении/оценке для дальнейшего анализа. Первое наблюдение Я задаю несколько случайных вопросов отточенной модели. Это дает некоторые разумные ответы. Вот один из примеров: Инструкция: внимательно ответьте на вопрос пользователя. Исходные данные: Что произойдет, если вы вытащите тележку с выключателем распределительного устройства? Ответ: Когда тележка с выключателем распределительного устройства «выкачена», это означает, что все выключатели в тележке разомкнуты и тележка находится в обесточенном состоянии. Обычно это делается во время обслуживания, ремонта или проверки грузовика. После того, как автоматические выключатели выдвинуты, на погрузчике можно безопасно работать, и его можно снова подать на питание после завершения необходимого технического обслуживания или ремонта. В этом примере запрашиваются внутренние знания LLM. Похоже, модель знала толк в распределительных устройствах. Однако когда я попытался эмпирически проверить его способность к рассуждению, он дал очень странный результат: Инструкция: Учитывая приведенную ниже информацию о проекте, ответьте на вопросы. Проект Chinese-Llama-2 направлен на улучшение понимания, создания и возможностей перевода большой языковой модели Llama-2 на китайский язык. С применением таких методов, как точная настройка LoRA, точная настройка инструкций с полным набором параметров и вторичное предварительное обучение, мы сердечно приглашаем вас загрузить и использовать соответствующие наборы данных, руководства по обучению и параметры модели. Входные данные: Какие методы используются в этом проекте? Ответ: Проект «Китайская Лама-2» направлен на улучшение понимания, создания и возможностей перевода большой языковой модели «Лама-2» на китайский язык. С применением таких методов, как точная настройка LoRA, точная настройка инструкций с полным набором параметров и вторичное предварительное обучение, мы сердечно приглашаем вас загрузить и использовать соответствующие наборы данных, руководства по обучению и параметры модели.</s> Как видите, модель любит повторять подсказку. Я называю это моделью , и другие разработчики также сообщали о таком поведении в . Его способность отвечать на вопросы становится лучше с более тщательно продуманными подсказками. Такое поведение — не то, что нам нужно в производственной системе, поскольку мы не можем гарантировать быструю эффективность для разных моделей. Модели должны быть менее чувствительны к подсказкам. Мы хотим как-то улучшить работу этого LLM. повторения подсказок вопросах репозитория На следующем занятии я расскажу, что вызвало эту проблему и как улучшить результаты тонкой настройки. Вторая попытка и (отчасти) успех Вот 3 вещи, которые я пытался улучшить при точной настройке: Маскировка потерь в подсказках (помогает избежать повторения подсказок) Отключите опцию (помогает повысить производительность, делает кривую потерь более гладкой) group-by-length Не доверяйте оценочной кривой потерь. Используйте контрольную точку с меньшими потерями при обучении, даже если ее оценочные потери могут быть выше, чем у «лучшей» контрольной точки. (помогает повысить производительность, поскольку потеря оценок здесь не лучшая матрица) Давайте объясним эти 3 пункта один за другим. Маскировка потерь в подсказках Я искал причины быстрого повторения, пока не нашел этот и . Они предложили исключить подсказки из расчета потерь. По сути, вы не хотите, чтобы модель выдавала токены подсказки. Маскирование подсказок во время обучения не побудит модель повторять токены подсказок. Это объясняется в таблице ниже: из трех тренировочных прогонов — единственный прогон, в котором не маскировались подсказки во время тренировки. Таким образом, его потери на обучение вначале выше. Я подозреваю, что если подсказки не маскируются при расчете потерь и обучение недостаточно, модель с большей вероятностью будет повторять подсказки, а не следовать инструкциям. пост официальное сообщение о коммите веса Лоры stoic-star-6 а) б) В исходном коде маскирование потерь осуществляется путем установки токенов подсказки на -100: Токены с индексами, установленными на , игнорируются (маскируются), потери вычисляются только для токенов с метками в . -100 [0, ..., config.vocab_size] Отключите опцию group-by-length Опция позволяет Huggingface группировать входные данные одинаковой длины в пакеты. Это помогает сэкономить использование VRAM при заполнении входных последовательностей. Однако это значительно уменьшит дисперсию выборки внутри одной партии. В процессе обучения мы обычно предпочитаем подвергать модель воздействию различных обучающих выборок. Установка для параметра значения уменьшает вариацию выборки. Это также вызывает колебания потерь во время обучения (например, две последовательные партии имеют дополненную длину 10 и 50. Более короткая партия имеет меньшие потери, а более длинная партия имеет более высокие потери. Это приводит к колеблющейся кривой потерь, как показано на рисунке. ниже). group-by-length Trainer group-by-length False С другой стороны, поскольку уменьшает вариации выборки внутри партии, я подозреваю, что производительность модели также может пострадать от этого. На рисунке ниже сравниваются потери при обучении с или без нее. Понятно, что усредненные потери выше для запуска , в котором включена . group-by-length group-by-length peach-violet-19 group-by-length Не доверяйте оценочной кривой потерь Я заметил, что потери в тренировках и потери в оценке различаются во всех моих забегах. Вот пример: В этом примере оптимальная контрольная точка возникает около . Если вы загрузите оптимальную контрольную точку, как предложено в исходном , вы, скорее всего, получите модель , как упоминалось в предыдущем сеансе. epoch=2 репозитории повторителя подсказок Загрузив контрольную точку модели ближе к концу обучения, я получил более производительную модель. Я задал тот же вопрос, что и раньше, и модель дала правильный ответ: Инструкция: Учитывая приведенную ниже информацию о проекте, ответьте на вопросы. Проект Chinese-Llama-2 направлен на улучшение понимания, создания и возможностей перевода большой языковой модели Llama-2 на китайский язык. С применением таких методов, как точная настройка LoRA, точная настройка инструкций с полным набором параметров и вторичное предварительное обучение, мы сердечно приглашаем вас загрузить и использовать соответствующие наборы данных, руководства по обучению и параметры модели. Входные данные: Какие методы используются в этом проекте? Ответ: В проекте Chinese-Llama-2 используются такие методы, как точная настройка LoRA, точная настройка инструкций с полным параметром и вторичное предварительное обучение.</s> Но судя по потере оценки, эта модель должна работать хуже. Что вызывает дилемму? Я думаю, что потери при оценке не являются хорошей матрицей для измерения производительности большой языковой модели. LLaMA использует для потери обучения и оценки: CrossEntropyLoss # modelling_llama.py from transformers library ... # forward function under LlamaForCausalLM class if labels is not None: # Shift so that tokens < n predict n shift_logits = logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() # Flatten the tokens loss_fct = CrossEntropyLoss() loss = loss_fct(shift_logits.view(-1, self.config.vocab_size), shift_labels.view(-1)) При тестировании на оценочном наборе модель может дать один и тот же ответ, но в другой формулировке: { "evaluation prompt": "What is 1 + 3?" "evaluation answer": "4." "prediction answer": "The answer is 4." } Оба ответа верны, но если прогнозируемый ответ не соответствует точному ответу оценки, потеря оценки будет высокой. В этом случае нам нужна лучшая матрица оценки для измерения эффективности модели. О правильной оценке мы побеспокоимся позже. А пока давайте предположим, что лучшей моделью является модель с наименьшими потерями при обучении. Выход за пределы 7B Я попробовал настроить модель 13B на V100. Хотя V100 может обрабатывать обучение как int8, так и fp16 на модели 7B, он просто не может обрабатывать обучение int8 на модели 13B. Если , модель 13B выдаст . Мы можем использовать некоторые инструменты отладки, чтобы понять, почему это происходит ( это вызвано переполнением/недополнением). load_int_8bit = True training_loss = 0.0 спойлер: Я использовал инструмент от Huggingface для проверки параметров во время обучения. При первом прямом проходе он обнаружил значения inf/nan: DebugUnderflowOverflow Точнее, улавливает отрицательные значения бесконечности во втором входе , как показано на рисунке ниже. Второй вход — . Я углубился немного глубже и обнаружил, что должна иметь очень большие отрицательные значения для элементов заполнения. По совпадению, отрицательные значения бесконечности находятся в начале каждой последовательности. Это наблюдение наводит меня на мысль, что на этом слое должны иметь место отрицательные значения бесконечности. Дальнейшее исследование также показало, что значения бесконечности не приводят к увеличению значений бесконечности в следующих нескольких слоях. Таким образом, переполнение , скорее всего, не является основной причиной ненормальной потери обучения. DebugUnderflowOverflow LlamaDecoderLayer attention_mask attention_mask LlamaDecoderLayer Затем я проверил выходные данные каждого слоя. Было совершенно ясно, что выходные данные последних слоев переполнены, как показано на рисунке ниже. Я считаю, что это вызвано ограниченной точностью весов int-8 (или ограниченным диапазоном . Вполне вероятно, что мог бы избежать этой проблемы). float16 bfloat16 Чтобы решить проблему переполнения, я использовал float16 во время обучения. У V100 недостаточно видеопамяти для обучения модели 13B, если только не были использованы некоторые хитрости. предоставляет несколько методов, таких как разгрузка ЦП, для уменьшения использования видеопамяти при обучении. Но самый простой трюк — включить контрольную точку градиента, вызвав перед началом обучения. Hugging Face DeepSpeed model.gradient_checkpointing_enable() Градиентная контрольная точка снижает скорость обучения за меньшее использование видеопамяти. Обычно во время прямого прохода активации вычисляются и сохраняются в памяти для использования во время обратного прохода. Это занимает дополнительную память. Однако при использовании градиентной контрольной точки вместо сохранения активаций во время прямого прохода они пересчитываются во время обратного прохода, тем самым экономя VRAM. Вот хорошая об этой технике. статья Мне удалось обучить Llama 13B с float16 и включенной контрольной точкой градиента: python finetune.py \ --base_model=yahma/llama-13b-hf \ --num_epochs=10 \ --output_dir 'your/output/dir' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --cutoff_len=1024 \ --lora_r=16 \ --micro_batch_size=4 \ --batch_size=128 \ --wandb_project 'alpaca_lora_13b' \ --train_on_inputs=False Модель 13B может решать некоторые сложные задачи, такие как распознавание имен. Я использую для теста, и это точный ответ модели 13B: пример запроса Все хорошо! Это захватывающее начало. Модель позволяет нам создавать сложные приложения с помощью LangChain. На данный момент нам все еще не хватает инструментов для автоматической оценки модели. Мы можем использовать Language Model Evaluation Harness для оценки наших моделей во многих тестовых случаях или даже создавать собственные тестовые примеры. Это тот же инструмент, который Hugging Face использует для своей таблицы лидеров Open LLM. Хотя оценка является важнейшим аспектом развития LLM, эта статья посвящена исключительно процессу обучения. Я могу обсудить оценку в будущей статье. Краткое содержание В этой статье мы представили концепцию больших моделей фундамента (LFM) и несколько методов тонкой настройки, которые заставляют LFM вести себя желаемым образом. Затем мы сосредоточились на LoRA, эффективном по параметрам методе тонкой настройки LFM, и объяснили код тонкой настройки, а также методы повышения производительности. Наконец, мы пошли еще дальше и успешно обучили модель Llama 13B на графическом процессоре V100. Хотя при обучении модели 13B возникли некоторые проблемы, мы обнаружили, что эти проблемы были вызваны аппаратными ограничениями, и предложили решения. В итоге мы получили хорошо настроенный LLM, который работает, но мы еще не оценили его эффективность количественно. Об авторе Привет! Меня зовут Вэй. Я специалист по решению проблем, старший специалист по искусственному интеллекту и руководитель проекта по аналитике в , а также . Я получил степень магистра машиностроения в Университете городов-побратимов Миннесоты и степень бакалавра машиностроения в Университете Иллинойса в Урбана-Шампейн. ABB эксперт Google по машинному обучению Мой технический стек сосредоточен на программировании на Python/C#, компьютерном зрении, машинном обучении, алгоритмах и микросервисах, но у меня также есть широкий круг интересов, таких как разработка игр (Unity), фронтальная/бэкенд-разработка, техническое лидерство, возился с одноплатными компьютерами и робототехникой. Я надеюсь, что эта статья сможет каким-то образом помочь людям. Спасибо за чтение и удачного решения проблем!