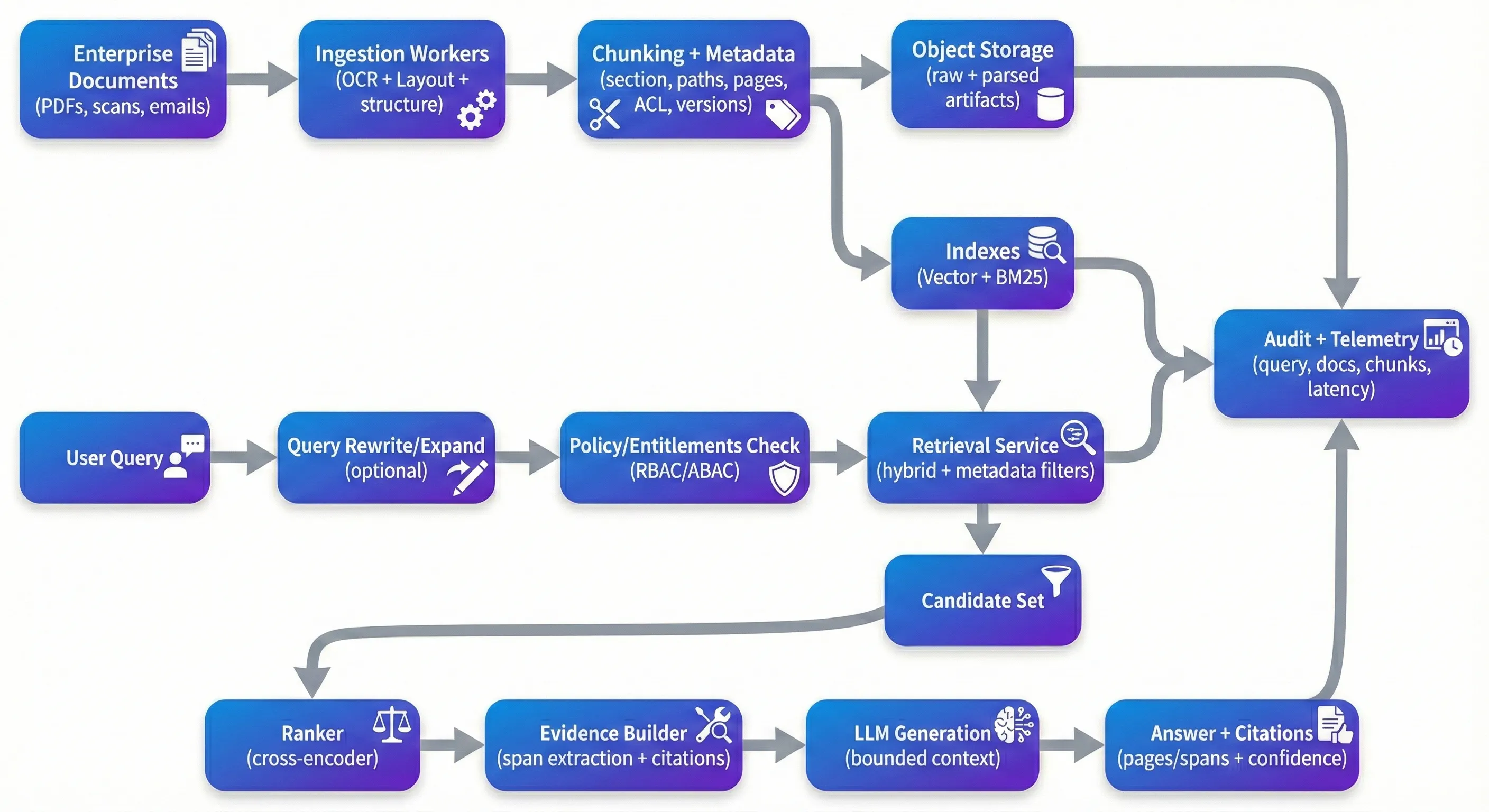
RAG נמצא בכל מקום – וזה לא מפתיע. זוהי אחת הדרכים המעשיות ביותר להפוך אוספים גדולים של מסמכים לחשופים מבלי לבנות מחקרים חלשים, ספציפיים לשדה עבור כל סוג של שאלה. הבעיה היא כי מה שעובד בדמו מבוקש לעתים קרובות מתדרדר במהירות כאשר אתה מטיל אותו מול PDF האמיתי של הארגון: חוזי סריקה, תיעוד תאימות, רשומות רפואיות, מדיניות, ואת הזנב הארוך של בעיות עיצוב ואיכות שמגיעות איתם. כאשר צוותים תקועים, זה לעתים רחוקות בגלל חיפוש וקטור "לא עובד". זה בגלל המערכת לא יכולה לקבוע תשובות באופן עקבי על הראיות הנכונות, לא יכול לאכוף את הזכויות באופן אמין, או לא ניתן להעריך ולשפר מבלי לשבור דברים. The Demo Trap עקבו אחרי demo trap רוב הפרוטוטיפים פועלים באותו נתיב: להוריד מסמכים לחנות וקטור, להוריד חתיכות top-k, ולבקש LLM לסנתז. על טקסט נקי, מבוסס היטב, זה יכול להיראות מצוין. הבעיה היא מה שקורה בהמשך. קבצי PDF סורקים מגיעים סובבים או מעוותים. סדר קריאה רב-עמוד מתמוטט. טבלאות מאבדות מבנה במהלך החילוץ. Chunking מחולק באמצע הטענה. Retrieval מחזיר את הקשר "קרוב מספיק" שמקרא באופן סביר אבל לא באמת תומך בטענה. והמודל, עושה את מה שהוא אופטימיזציה לעשות, עונה באופן שוטף בכל מקרה. בייצור, אתה אופטימיזציה עבור מאפיינים שונים מאשר דמו.היית רוצה שהמערכת תהיה אמין מעל כניסות מבולבלות, ניתן לשחזר לאורך שינויים צינור, ולהגן תחת בדיקה.זה אומר להיות מסוגל לעקוב אחר תשובה חזרה עד ראיות ספציפיות, ויש כפתיחות חזקות כאשר ראיות חלשות: ברור שאלות, התנהגות דחייה, או מציג "הראיות הזמינות הטובות ביותר" עם חוסר ודאות מפורשת. Ingestion: Where Quality Is Won or Lost תזונה: איפה האיכות ניצחה או אבודה אם אתה בונה כמה מערכות אלה, אתה לומד במהירות כי אכילת קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קובץ קוב Chunking הוא המקום שבו צוותים לעתים קרובות להעריך את המורכבות. חלוקה פשוטה של תווים או תוויות היא מהירה, אבל היא נוטה לחתוך גבולות סמנטיים – בדיוק הגבולות המעניינים את המשתמשים בחוזה ובמדיניות. Adaptive chunking אשר עוקב אחרי כותרות, גבולות סעיף, וגבולות טבלה משפר בדרך כלל את החיפוש ואת הקרקע למטה. מטא-נתונים הם אזור נוסף אשר נוטה להיראות אופציונלי עד שאתה צריך את זה. בפועל, מטא-נתונים הם מה שהופך מסנן, מעקב, ושחזור אפשרי. מטא-נתונים שימושיים ברמה של חתיכות בדרך כלל כוללים מזהה מסמכים, נתיבי סעיף, מספרים של עמודים, תווי זמן (תאריך אפקטיבי, שונה לאחרונה, נלקח ב), אותות ביטחון חיסול, מזהה גירסה (מסמך hash, גירסה צונן, גירסת מודל מוטבע). בהקשרים ארגוניים, תכונות בקרת גישה (שכר, מחלקה, פרטיות, תווי תפקידים) צריכים להיות ברמה הראשונה, כי הם מכריעים ישירות חיפוש ועידות. The Retrieval Stack That Actually Works ה-Retrieval Stack שעובד באמת חיפוש דמיון וקטור הוא בסיס טוב, אבל זה לעתים רחוקות מספיק לבד עבור מסמכים ארגוניים.פרקטיקה, חיפוש היברידי-הדבקות צפופות בתוספת החיפוש לקסולוגי צפופות כמו BM25 - נוטה להיות חזקה יותר, במיוחד כאשר משתמשים שואלים עם מספרים של סעיפים, מזהים, אקרונומיות או ביטויים מדויקים. דירוג מחדש הוא לעתים קרובות המקום שבו מערכות עושים את הקפיצה הגדולה ביותר באיכות הנחשבת, לא משום שזה קסום, אלא משום שהוא מתקן מצב כישלון נפוץ: קבוצת החיפוש הראשונית מכילה חתיכות "קינדה רלוונטיות", ואתה צריך לקדם את החתיכות הרלוונטיות באמת למעלה. דירוג מחדש בין-קודר (מודלים פתוחים כגון bge-reranker או APIs מנוהלים כגון Cohere ranker) דירוג מחדש חתיכות מועמד באמצעות אינטראקציה עמוקה יותר של שאלה-עבר. צוותים בדרך כלל רואים עלייה ניכרת של דיוק הקשר כאשר דירוג מחדש נמדד כראוי (למשל, על קבוצת זהב עם מקורות צפויים כתיבת מחדש של השאילתות והרחבה היא עוד תרומה שניתן לפספס בהקדם ולאחר מכן לגלות מחדש מאוחר יותר. המשתמשים אינם מתייחסים באופן טבעי לשאלות כדרך כתיבת המסמכים. צעד של כתיבת מחדש יכול להרחיב אקרונומיות, לנורמליזציה של ישויות ולחלק שאלות רבות לשאלות תת-שאלות ידידותיות לחיפוש. זה לא חייב להיות פנטסי – אבל הוא זקוק להתבוננות, כי כתיבת מחדש בלתי נשלטת יכולה להתרחק מכוונת המשתמש. Security: The Layer Everyone Forgets אבטחה: שכבה שכולם שוכחים רוב דמויות RAG להתעלם שליטה גישה כי זה להאט את הפרוטוטיפ, בייצור, זהו מכשול עיקרי.אם המערכת שלך אינדקס מסמכים HR, חוזה משפטי, ופרטים הנדסיים יחד, אתה צריך נתיב גישה דטרמיניסטי ממשתמש → מותר חתיכות, והחזרה חייבת להיות מוגבלת על ידי נתיב זה לפני כל תוכן מגיע LLM. הדפוס שנועד להגדיל הוא חיפוש מראש מסנן: זכויות חישוב (RBAC / ABAC), להוריד רק מחתיכות עם תכונות ACL תואמות, לגרד מחדש בתוך קבוצת המועמדים המוסמכים, ולכתוב אילו ראיות נכנסו.זה גם המקום שבו "מטא-נתונים אינם אופציונליים" נקודה מופיעה בפועל - ללא תגית ברמה של חתיכות, אתה בסופו של דבר עם גבולות זורמים או יקרים, חלשים פוסט-סנורות. מעבר ל-ACL, יישומים עסקיים בדרך כלל צריכים שילוב מסוים של זיהוי / מסתירה של PII, הצפנה במנוחה, טוקי חיים קצרים עבור גישה למקור, ורישום בקרה שמקבלת שאילתות, זיהוי חתיכות, ציטוטים, וגרסאות מסמכים. דאגה מודרנית נוספת שווה לקחת ברצינות היא הזרקה מיידית של תוכן בתוך מסמכים. אתה לא צריך להתייחס לכל מסמך כאל עוינות, אבל אתה צריך שערים בסיסיים, כך שהוראות המוטבעים בטקסט המקור לא יכול להחליף את הכללים של המערכת שלך - במיוחד סביב גישה, שליטה, וכיצד המודל מותר להתנהג. Monitoring: Closing the Loop תגית: Closing the Loop אם אתה מפעיל אחת מהמערכות האלה במשך יותר משבועיים, תראה דלף.המסמכים משתנים, ההפצה של השאילתות משתנה, צינור ההזנה משתנה, והרכיבים של המודל מתעדכנים. למעשה, אתה רוצה לעקוב אחר בריאות החיפוש (Recall@k נגד ערכת זהב, דיוק הקשר, ריאנקר להרים), בריאות הדור (דיוקת ציטוט, בדיקת קרקע / נאמנות, שיעורי דחייה), ואת בריאות התפעול (p50 / p95 עיכוב, עלות לשאול, עיכוב אכילה מהעדכון מסמך לאנדקס ניתן לחפש). הצוותים היעילים ביותר שראיתי לשמור על ערכת נתונים הערכה זהב - שאלות שנקבעו עם מסמכים מקוריים צפויים - ולפעול אותו על לוח זמנים ועל אירועים שינויים (הדבקים חדשים, לוגיקה חדשה, מנות מסמכים חדשות). כלי כמו פיניקס, TruLens, או פלטפורמות מסחריות יכול לעזור, אבל ההבדל הגדול אזור אחד שנחשב לעתים קרובות פחות מוערך הוא גרסאות ושיפוצים.כאשר אתה משנה מודלים OCR, סימון לוגיקה, שילוב מודלים, Rerankers, או דרישות ייצור, אתה צריך דרך לעקוב אחר מה גרסאות יצרו אשר עונה. Choosing Your Stack בחר את הסטייק שלך החלטות קובץ חשובות, אבל יכולות חשובות יותר. עבור קבוצות רבות, התקנה ממוקדת בניהול היא אטרקטיבית: אינטגרציה באמצעות כלי מסמך AI מנוהל או צינור מבוסס Unstructured, מסד נתונים וקטור ממוקם, שכבה אורכיסטריזציה כגון LlamaIndex או LangChain, ו- reranker (פתוח או מנוהל). אחרים מעדיפים יישומים קוד פתוחים באמצעות Qdrant/Weaviate/OpenSearch, Haystack או אורכיסטריזציה דומה, ומודלים מאורגנים באופן עצמאי עבור שליטה וחיזוי עלויות. כל גישה יכולה לעבוד אם היא תומכת בסיסיים: אינטגרציה מודעת למסמכים, אינטגרציה היברידית, אימו בצד האדריכלות, מערכות נוטות להיות קלות יותר לפעול כאשר הן מחולקות בצורה נקיה: עובדי אכילה המופעלים באופן אסינכרוני וניתן להחזיר אותם בבטחה; שירות חיפוש ללא מדינה שמחייב מדיניות ומחזיר ראיות; ושירות ייצור הפועל עם הקשר המוגבל ומקורות ברורים.ההפצה טיפוסית של הפניה כוללת שער API, זווית עבודה (Kafka/RabbitMQ), אחסון אובייקטים עבור מסמכים גלויים ואובייקטים מעובדים, שכבת האינדקס ( +dense sparse), בתוספת יומן מרכזי / מדיטריקה ושיטת ביקורת.