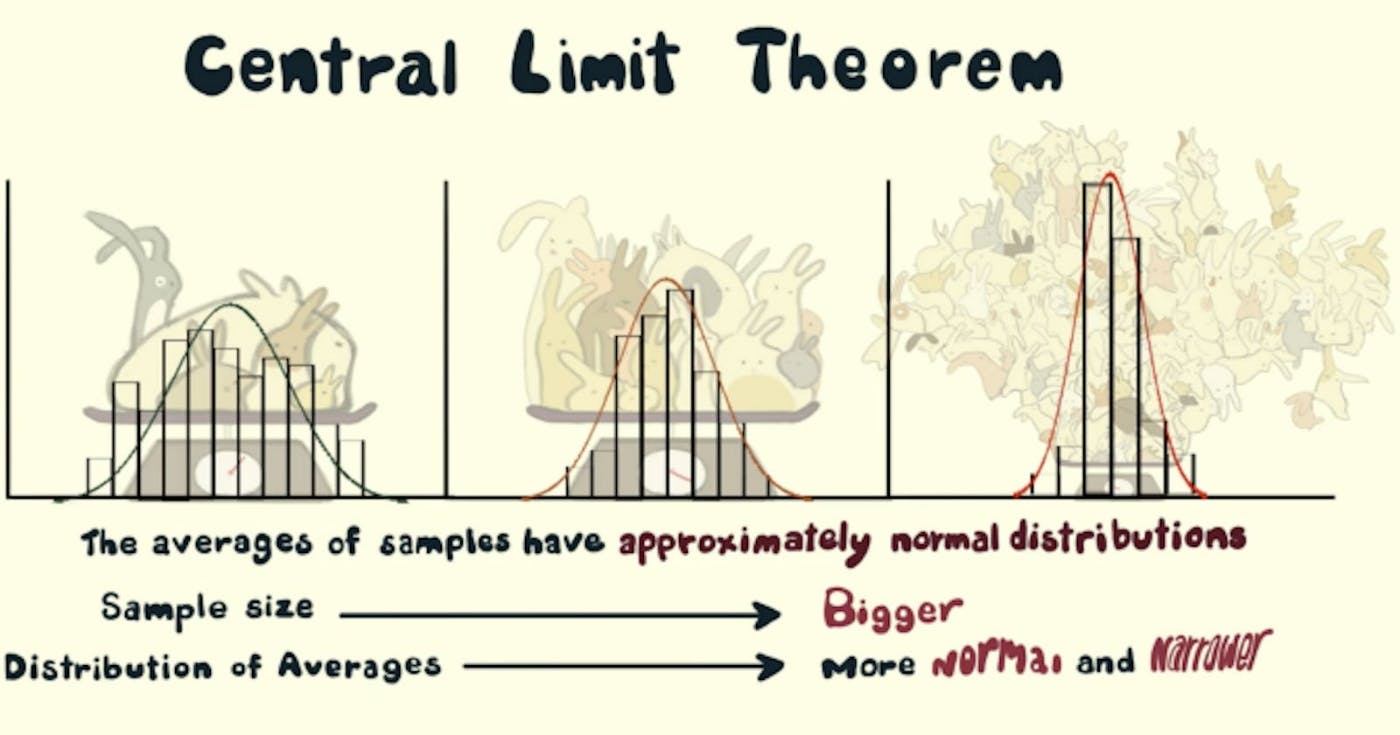
Définition, signification et applications TLDR : Vous pouvez trouver le code complet . ici sur GitHub Le théorème central limite capture le phénomène suivant : Prenez n'importe quelle distribution ! (disons une répartition du nombre de passes dans un match de football) Commencez à prélever n échantillons de cette distribution (disons n = 5) plusieurs fois [disons m = 1 000] fois. Prenez la moyenne de chaque ensemble d'échantillons (nous aurions donc m = 1000 moyennes) La répartition des moyens serait (plus ou moins) . (Vous obtiendrez cette fameuse courbe en cloche si vous tracez les moyennes sur l'axe des x et leur fréquence sur l'axe des y.) normalement répartie Augmentez n pour obtenir un écart type plus petit et augmentez m pour obtenir une meilleure approximation de la distribution normale. Mais pourquoi devrais-je m’en soucier ? Vous ne parvenez pas à charger toutes les données à traiter ? Pas de problème, retirez plusieurs échantillons des données et utilisez le théorème central limite pour estimer les paramètres des données comme la moyenne, l'écart type, la somme, etc. Cela peut vous faire économiser des ressources en termes de temps et d’argent. Car désormais, nous pouvons travailler sur des échantillons nettement plus petits que la population et tirer des conclusions pour l’ensemble de la population ! Un certain échantillon appartient-il à une certaine population (ou à un ensemble de données) ? Vérifions cela en utilisant la moyenne de l'échantillon, la moyenne de la population, l'écart type de l'échantillon et l'écart type de la population. Définition Étant donné un ensemble de données avec une distribution inconnue (elle peut être uniforme, binomiale ou complètement aléatoire), les moyennes de l'échantillon se rapprocheront de la distribution normale. Explication Si nous prenons un ensemble de données ou une population et commençons à prélever des échantillons de la population, disons que nous prenons 10 échantillons et prenons la moyenne de ces échantillons, et nous continuons à faire cela, plusieurs fois, disons 1000 fois, après avoir fait cela, nous obtenons 1 000 moyennes et lorsque nous les traçons, nous obtenons une distribution appelée distribution d'échantillonnage des moyennes d'échantillon. Cette distribution d'échantillonnage suit (plus ou moins) une distribution normale ! C'est le théorème central limite. Une distribution normale possède un certain nombre de propriétés utiles pour l’analyse. Fig.1 Distribution d'échantillonnage des moyennes d'échantillon (suivant une distribution normale) Propriétés d'une distribution normale : La moyenne, le mode et la médiane sont tous égaux. 68 % des données se situent à moins d’un écart type de la moyenne. 95 % des données se situent à moins de deux écarts types de la moyenne. La courbe est symétrique au centre (c'est-à-dire autour de la moyenne, μ). De plus, la moyenne de la distribution d’échantillonnage des moyennes de l’échantillon est égale à la moyenne de la population. Si μ est la moyenne de la population et μX̅ est la moyenne de l’échantillon, cela signifie alors : Fig.2 moyenne de la population = moyenne de l'échantillon Et l'écart type de la population (σ) a la relation suivante avec la distribution d'échantillonnage de l'écart type (σX̅) : Si σ est l'écart type de la population et σX̅ est l'écart type des moyennes de l'échantillon, et n est la taille de l'échantillon, alors nous avons Fig.3 Relation entre l'écart type de la population et l'écart type de la distribution d'échantillonnage Intuition Puisque nous prélevons plusieurs échantillons de la population, les moyennes seraient le plus souvent égales (ou proches) de la moyenne réelle de la population. Par conséquent, nous pouvons nous attendre à un pic (mode) dans la distribution d’échantillonnage des moyennes de l’échantillon égal à la moyenne réelle de la population. Plusieurs échantillons aléatoires et leurs moyennes se situeraient autour de la moyenne réelle de la population. Par conséquent, nous pouvons supposer que 50 % des moyennes seraient supérieures à la moyenne de la population et 50 % seraient inférieures à celle-ci (médiane). Si nous augmentons la taille de l’échantillon (de 10 à 20 puis à 30), de plus en plus de moyennes d’échantillon se rapprocheraient de la moyenne de la population. Par conséquent, la moyenne de ces moyennes devrait être plus ou moins similaire à la moyenne de la population. Prenons le cas extrême où la taille de l’échantillon est égale à la taille de la population. Ainsi, pour chaque échantillon, la moyenne serait la même que la moyenne de la population. Il s'agit de la distribution la plus étroite (écart type des moyennes de l'échantillon, ici 0). Par conséquent, à mesure que nous augmentons la taille de l’échantillon (de 10 à 20 puis à 30), l’écart type aurait tendance à diminuer (car l’écart dans la distribution d’échantillonnage serait limité et une plus grande partie des moyennes de l’échantillon serait concentrée sur la moyenne de la population). Ce phénomène est capturé dans la formule de la « Fig. 3 » où l'écart type de la distribution de l'échantillon est inversement proportionnel à la racine carrée de la taille de l'échantillon. Si nous prenons de plus en plus d’échantillons (de 1 000 à 5 000 à 10 000), alors la distribution d’échantillonnage serait une courbe plus lisse, car un plus grand nombre d’échantillons se comporteraient selon le théorème central limite et le modèle serait plus net. "Parler, c'est pas cher, montre-moi le code !" - Linus Torvalds Alors, simulons le théorème central limite via du code : Quelques importations : import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math Créez une population en utilisant . Vous pouvez essayer différentes distributions pour générer des données. Le code suivant génère une (en quelque sorte) distribution décroissante de façon monotone : random.randint() def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population Créez des échantillons et prenez leur nombre moyen : sample_count def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list Fonction pour tracer la distribution des données avec quelques étiquettes. def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show() La fonction principale pour exécuter le code : def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True) Vous pouvez trouver le code complet . ici sur GitHub Les références: Théorème central limite en action Théorème central limite : une application réelle Introduction au théorème central limite Une introduction douce au théorème central limite pour l'apprentissage automatique Théorème central limite Crédits image de couverture : Casey Dunn et Creature Cast sur Vimeo Lecture suggérée (Vidéos suggérées) : khanacademy/théorème de la limite centrale Statistiques de la science des données d'apprentissage automatique Également publié ici