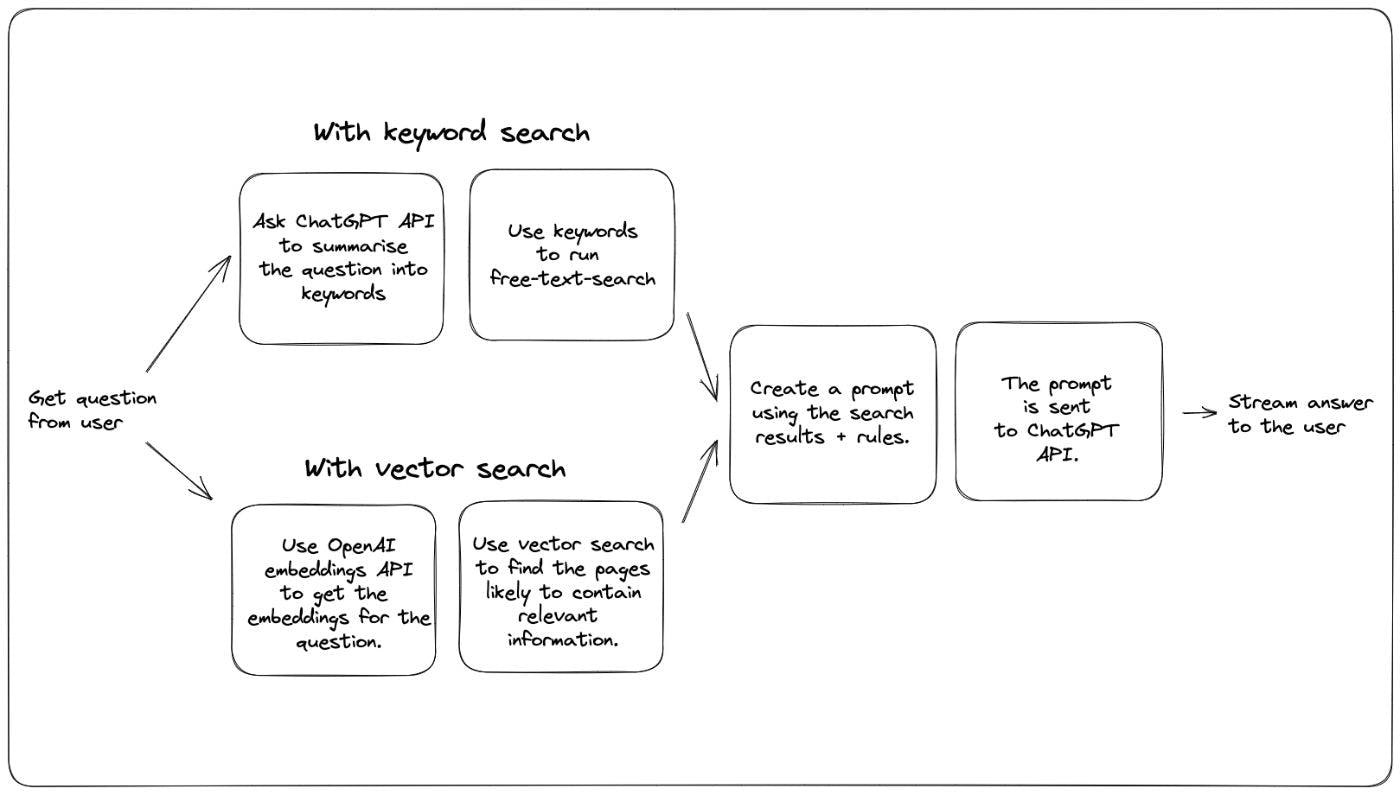
Letzte Woche haben wir einen Q&A-Bot hinzugefügt, der Fragen aus beantwortet. Dabei wird die ChatGPT-Technologie genutzt, um Fragen aus der Xata-Dokumentation zu beantworten, auch wenn das OpenAI-GPT-Modell nie anhand der Xata-Dokumentation trainiert wurde. unserer Dokumentation Wir tun dies mithilfe eines Ansatzes, den Simon Willison in diesem vorgeschlagen hat. Der gleiche Ansatz findet sich auch in einem . Die Idee ist folgende: Blogbeitrag OpenAI-Kochbuch Führen Sie eine Textsuche in der Dokumentation durch, um den Inhalt zu finden, der für die vom Benutzer gestellte Frage am relevantesten ist. Erstellen Sie eine Eingabeaufforderung mit dieser allgemeinen Form: With these rules: {rules} And this text: {context} Given the above text, answer the question: {question} Answer: Senden Sie die Eingabeaufforderung an die ChatGPT-API und lassen Sie das Modell die Antwort vervollständigen. Wir haben herausgefunden, dass dies recht gut funktioniert und in Kombination mit einer relativ niedrigen Modelltemperatur (das Konzept der Temperatur wird in diesem erklärt) tendenziell zu korrekten Ergebnissen und Codeausschnitten führt, sofern die Antwort darin gefunden werden kann Dokumentation. Blogbeitrag Eine wesentliche Einschränkung dieses Ansatzes besteht darin, dass die Eingabeaufforderung, die Sie im zweiten Schritt oben erstellen, maximal 4.000 Token (~3.000 Wörter) haben muss. Das bedeutet, dass der erste Schritt, die Textsuche zur Auswahl der relevantesten Dokumente, wirklich wichtig wird. Wenn der Suchschritt gute Arbeit leistet und den richtigen Kontext bereitstellt, leistet ChatGPT tendenziell auch gute Arbeit und liefert ein korrektes und auf den Punkt gebrachtes Ergebnis. Was ist also der beste Weg, um die relevantesten Inhalte in der Dokumentation zu finden? Das OpenAI-Kochbuch sowie Simons Blog verwenden die sogenannte semantische Suche. Die semantische Suche nutzt das Sprachmodell, um Einbettungen sowohl für die Frage als auch für den Inhalt zu generieren. Einbettungen sind Zahlenarrays, die den Text in mehreren Dimensionen darstellen. Textteile mit ähnlichen Einbettungen haben eine ähnliche Bedeutung. Dies bedeutet, dass eine gute Strategie darin besteht, die Inhalte zu finden, deren Einbettungen den Frageneinbettungen am ähnlichsten sind. Eine weitere mögliche Strategie, basierend auf der eher klassischen Keyword-Suche, sieht so aus: Bitten Sie ChatGPT, die Schlüsselwörter aus der Frage zu extrahieren, mit einer Eingabeaufforderung wie dieser: Extract keywords for a search query from the text provided. Add synonyms for words where a more common one exists. Verwenden Sie die bereitgestellten Schlüsselwörter, um eine Freitextsuche durchzuführen und die besten Ergebnisse auszuwählen In einem einzigen Diagramm dargestellt sehen die beiden Methoden folgendermaßen aus: Wir haben beides in unserer Dokumentation ausprobiert und dabei einige Vor- und Nachteile festgestellt. Beginnen wir mit dem Vergleich einiger Ergebnisse. Beide werden mit derselben Datenbank ausgeführt und verwenden beide das ChatGPT- Modell. Da es sich dabei um Zufälligkeiten handelt, habe ich jede Frage zwei- bis dreimal beantwortet und das Ergebnis ausgewählt, das meiner Meinung nach das beste war. gpt-3.5-turbo Frage: Wie installiere ich die Xata-CLI? Antwort mit Vektorsuche: Antwort mit Stichwortsuche: : Beide Versionen lieferten die richtige Antwort, die Vektorsuche ist jedoch etwas vollständiger. Beide haben die richtige Dokumentseite dafür gefunden, aber ich denke, dass unsere auf Hervorhebungen basierende Heuristik im Falle der Keyword-Strategie einen kürzeren Textabschnitt ausgewählt hat. Urteil Gewinner: Vektorsuche. Ergebnis: 1:0 Frage: Wie nutzt man Xata mit Deno? Antwort mit Vektorsuche: Antwort mit Stichwortsuche: Enttäuschendes Ergebnis für die Vektorsuche, wer hat irgendwie die spezielle Deno-Seite in unseren Dokumenten übersehen. Es wurden einige andere für Deno relevante Inhalte gefunden, jedoch nicht die Seite, die das sehr nützliche Beispiel enthielt. Urteil: Gewinner: Stichwortsuche. Ergebnis: 1-1 Frage: Wie kann ich eine CSV-Datei mit benutzerdefinierten Spaltentypen importieren? Mit Vektorsuche: Mit Stichwortsuche: Beide haben die richtige Seite gefunden („CSV-Datei importieren“), aber die Version mit der Stichwortsuche hat es geschafft, eine vollständigere Antwort zu erhalten. Ich habe dies mehrmals ausgeführt, um sicherzustellen, dass es kein Zufall ist. Ich denke, der Unterschied liegt darin, wie das Textfragment ausgewählt wird (bei der Stichwortsuche neben den Schlüsselwörtern, bei der Vektorsuche am Anfang der Seite). Urteil: Gewinner: Stichwortsuche. Ergebnis: 1-2 Frage: Wie kann ich eine Tabelle mit dem Namen „Benutzer“ nach der E-Mail-Spalte filtern? Mit Vektorsuche: Mit Stichwortsuche: Die Vektorsuche schnitt in diesem Fall besser ab, da sie die Seite „Filterung“ gefunden hat, auf der es weitere Beispiele gab, die ChatGPT zum Verfassen der Antwort verwenden konnte. Die Antwort auf die Schlüsselwortsuche ist leicht fehlerhaft, da sie „query“ anstelle von „filter“ als Methodennamen verwendet. Urteil: Gewinner: Vektorsuche. Ergebnis: 2-2 Frage: Was ist Xata? Mit Vektorsuche: Mit Stichwortsuche: Dies ist ein Unentschieden, da beide Antworten recht gut sind. Die beiden haben unterschiedliche Seiten ausgewählt, um sie in einer Antwort zusammenzufassen, aber beide haben gute Arbeit geleistet und ich kann keinen Gewinner auswählen. Urteil: Ergebnis: 3-3 Konfiguration und Tuning Dies ist eine Beispiel-Xata-Anfrage, die für die Stichwortsuche verwendet wird: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "What is Xata?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "If you answer with Markdown snippets, prefer the GitHub flavour.", "Your name is DanGPT" ], "searchType": "keyword", "search": { "fuzziness": 1, "target": [ "slug", { "column": "title", "weight": 4 }, "content", "section", { "column": "keywords", "weight": 4 } ], "boosters": [ { "valueBooster": { "column": "section", "value": "guide", "factor": 18 } } ] } } Und das verwenden wir für die Vektorsuche: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "How do I get a record by id?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "Your name is DanGPT" ], "searchType": "vector", "vectorSearch": { "column": "embeddings", "contentColumn": "content", "filter": { "section": "guide" } } } Wie Sie sehen können, verfügt die Keyword-Suchversion über mehr Einstellungen zum Konfigurieren von Unschärfe, Boostern und Spaltengewichtungen. Die Vektorsuche verwendet lediglich einen Filter. Das würde ich als Pluspunkt für die Stichwortsuche bezeichnen: Sie haben mehr Einstellmöglichkeiten, um die Suche zu optimieren und erhalten dadurch bessere Antworten. Aber es ist auch mehr Arbeit und die Ergebnisse der Vektorsuche sind ohne diese Optimierung recht gut. In unserem Fall haben wir die Stichwortsuche bereits für unsere Dokumentensuchfunktion optimiert. Es war also nicht unbedingt zusätzliche Arbeit, und während wir mit ChatGPT experimentierten, entdeckten wir auch Verbesserungen an unseren Dokumenten und der Suche. Außerdem verfügt Xata zufällig über eine sehr schöne Benutzeroberfläche zum Optimieren Ihrer Stichwortsuche, sodass die Arbeit zunächst nicht schwer war (ich habe einen separaten Blog-Beitrag darüber geplant). Es gibt keinen Grund, warum die Vektorsuche nicht auch Booster, Spaltengewichtungen und dergleichen haben könnte, aber wir haben sie noch nicht in Xata und ich kenne keine andere Lösung, die das so einfach macht wie wir Schlüsselwörter Suchabstimmung. Und im Allgemeinen gibt es bei der Stichwortsuche mehr Stand der Technik, aber es ist durchaus möglich, dass die Vektorsuche aufholt. Im Moment nenne ich die Stichwortsuche den Gewinner Ergebnis: 3-4 Bequemlichkeit Unsere Dokumentation verfügte bereits über eine Suchfunktion, Dog-Fooding Xata, so dass es ganz einfach war, sie auf einen Chatbot zu erweitern. Xata unterstützt jetzt auch die Vektorsuche nativ, aber um sie zu verwenden, mussten Einbettungen für alle Dokumentationsseiten hinzugefügt und eine gute Chunking-Strategie gefunden werden. Für die Erstellung der Texteinbettungen haben wir die OpenAI-Einbettungs-API verwendet, was nur minimale Kosten verursachte. Gewinner: Stichwortsuche Ergebnis 3-5 Latenz Der Schlüsselwortsuchansatz erfordert einen zusätzlichen Roundtrip zur ChatGPT-API. Dies erhöht die Latenz des Ergebnisses, das in der Benutzeroberfläche gestreamt wird. Nach meinen Messungen ergibt das etwa 1,8 Sekunden mehr Zeit. Mit Vektorsuche: Mit Stichwortsuche: Die Gesamt- und Inhaltsdownloadzeiten sind hier nicht relevant, da sie hauptsächlich davon abhängen, wie lang die generierte Antwort ist. Schauen Sie sich zum Vergleich die Leiste „Warten auf Serverantwort“ (die grüne) an. Hinweis: Gewinner: Vektorsuche Ergebnis: 4-5 Kosten Die Version mit der Schlüsselwortsuche muss einen zusätzlichen API-Aufruf an die ChatGPT-API durchführen, wohingegen die Version mit der Vektorsuche Einbettungen für alle Dokumente in der Datenbank sowie die Frage erzeugen muss. Sofern es sich nicht um viele Dokumente handelt, würde ich das als Unentschieden bezeichnen. Ergebnis: 5-6 Abschluss Der Punktestand ist knapp! In unserem Fall haben wir uns vorerst für die Stichwortsuche entschieden, vor allem, weil wir mehr Möglichkeiten zur Optimierung haben und dadurch etwas bessere Antworten auf unsere Testfragen erhalten. Darüber hinaus kommen alle Verbesserungen, die wir an der automatischen Suche vornehmen, sowohl der Suche als auch den Chat-Anwendungsfällen zugute. Da wir unsere Vektorsuchfunktionen durch weitere Optimierungsoptionen verbessern, werden wir in Zukunft möglicherweise auf die Vektorsuche oder einen Hybridansatz umsteigen. Wenn Sie einen ähnlichen Chatbot für Ihre eigene Dokumentation oder eine Wissensdatenbank jeglicher Art einrichten möchten, können Sie dies mithilfe des Xata-Ask-Endpunkts problemlos implementieren. und treten Sie uns auf bei. Gerne helfe ich Ihnen persönlich bei der Inbetriebnahme! Erstellen Sie kostenlos ein Konto Discord