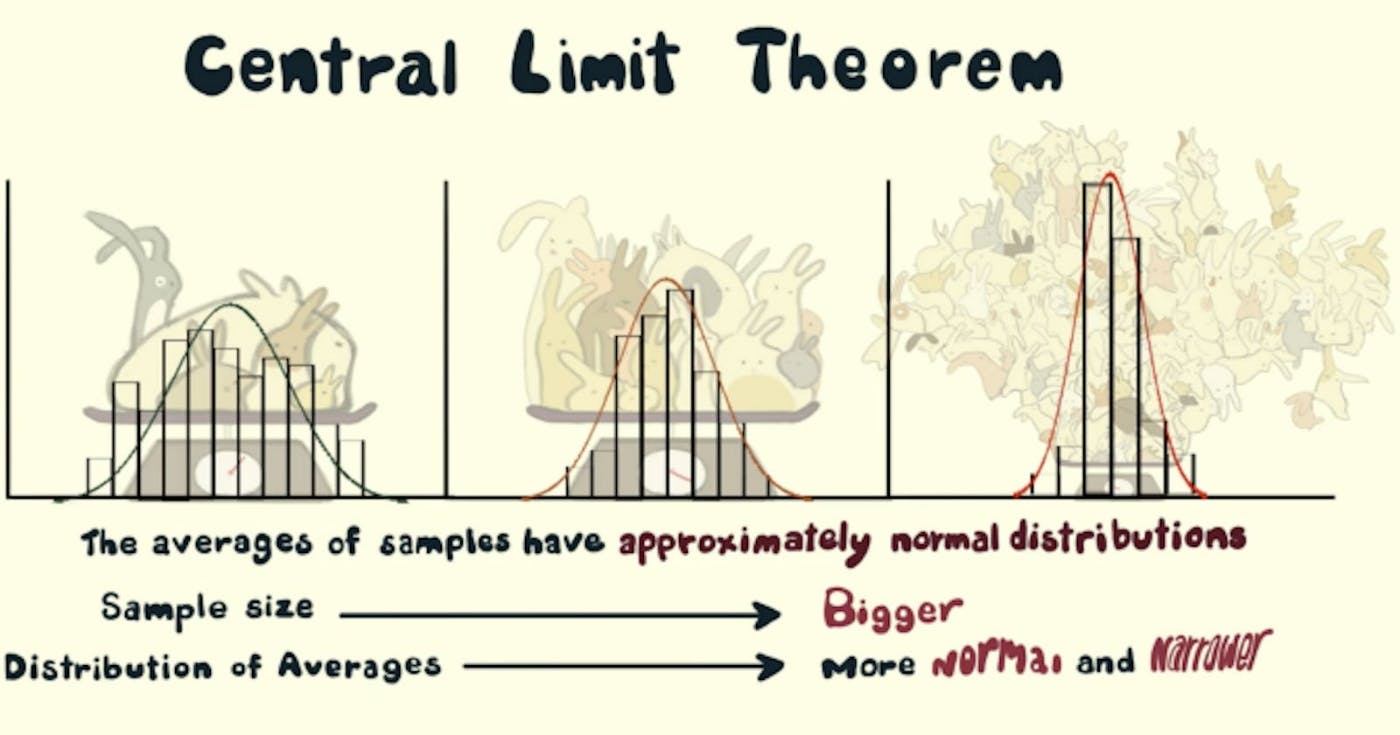
Definition, Bedeutung und Anwendungen TLDR: Den gesamten Code finden Sie . hier auf GitHub Der zentrale Grenzwertsatz erfasst das folgende Phänomen: Nehmen Sie jede Verteilung! (z. B. eine Verteilung der Anzahl der Pässe in einem Fußballspiel) Beginnen Sie mit der Entnahme von n Stichproben aus dieser Verteilung (z. B. n = 5) mehrmals [z. B. m = 1000] Mal. Nehmen Sie den Mittelwert jedes Stichprobensatzes (also hätten wir m = 1000 Mittelwerte) Die Verteilung der Mittel wäre (mehr oder weniger) . (Sie erhalten die berühmte Glockenkurve, wenn Sie die Mittelwerte auf der x-Achse und ihre Häufigkeit auf der y-Achse auftragen.) normalverteilt Erhöhen Sie n, um eine kleinere Standardabweichung zu erhalten, und erhöhen Sie m, um eine bessere Annäherung an die Normalverteilung zu erhalten. Aber warum sollte es mich interessieren? Können Sie nicht die gesamten Daten zur Verarbeitung laden? Kein Problem, entnehmen Sie mehrere Stichproben aus den Daten und nutzen Sie den zentralen Grenzwertsatz, um die Datenparameter wie Mittelwert, Standardabweichung, Summe usw. zu schätzen. Dadurch können Sie Ressourcen in Bezug auf Zeit und Geld sparen. Denn jetzt können wir an Stichproben arbeiten, die deutlich kleiner sind als die Grundgesamtheit, und Schlussfolgerungen für die gesamte Grundgesamtheit ziehen! Gehört eine bestimmte Stichprobe zu einer bestimmten Grundgesamtheit (oder einem Datensatz)? Überprüfen wir das anhand des Stichprobenmittelwerts, des Grundgesamtheitsmittelwerts, der Stichprobenstandardabweichung und der Grundgesamtheitsstandardabweichung. Definition Bei einem Datensatz mit unbekannter Verteilung (dieser kann gleichmäßig, binomial oder völlig zufällig sein) nähern sich die Stichprobenmittelwerte der Normalverteilung an. Erläuterung Wenn wir einen Datensatz oder eine Grundgesamtheit nehmen und damit beginnen, Stichproben aus der Grundgesamtheit zu entnehmen, sagen wir, wir nehmen 10 Stichproben und bilden den Mittelwert dieser Stichproben, und wir machen so weiter, ein paar Mal, sagen wir 1000 Mal, danach machen wir so weiter, Wir erhalten 1000 Mittelwerte und wenn wir sie grafisch darstellen, erhalten wir eine Verteilung, die als Stichprobenverteilung der Stichprobenmittelwerte bezeichnet wird. Diese Stichprobenverteilung folgt (mehr oder weniger) einer Normalverteilung! Dies ist der zentrale Grenzwertsatz. Eine Normalverteilung weist eine Reihe von Eigenschaften auf, die für die Analyse nützlich sind. Abb.1 Stichprobenverteilung der Stichprobenmittelwerte (nach einer Normalverteilung) Eigenschaften einer Normalverteilung: Mittelwert, Modus und Median sind alle gleich. 68 % der Daten liegen innerhalb einer Standardabweichung vom Mittelwert. 95 % der Daten liegen innerhalb von zwei Standardabweichungen vom Mittelwert. Die Kurve ist in der Mitte symmetrisch (dh um den Mittelwert μ). Darüber hinaus ist der Mittelwert der Stichprobenverteilung der Stichprobenmittelwerte gleich dem Grundgesamtheitsmittelwert. Wenn μ der Mittelwert der Grundgesamtheit und μX̅ der Mittelwert der Stichprobe ist, bedeutet Folgendes: Abb.2 Populationsmittelwert = Stichprobenmittelwert Und die Standardabweichung der Grundgesamtheit (σ) hat die folgende Beziehung zur Standardabweichungs-Stichprobenverteilung (σX̅): Wenn σ die Standardabweichung der Grundgesamtheit und σX̅ die Standardabweichung der Stichprobenmittelwerte ist und n die Stichprobengröße ist, dann gilt: Abb.3 Beziehung zwischen Populationsstandardabweichung und Stichprobenverteilungsstandardabweichung Intuition Da wir mehrere Stichproben aus der Grundgesamtheit entnehmen, sind die Mittelwerte in den meisten Fällen gleich (oder nahe) dem tatsächlichen Mittelwert der Grundgesamtheit. Daher können wir einen Peak (Modus) in der Stichprobenverteilung der Stichprobenmittelwerte erwarten, der dem tatsächlichen Bevölkerungsmittelwert entspricht. Mehrere Zufallsstichproben und ihre Mittelwerte würden in der Nähe des tatsächlichen Bevölkerungsmittelwerts liegen. Daher können wir davon ausgehen, dass 50 % der Mittelwerte über dem Bevölkerungsmittelwert liegen und 50 % darunter (Median) liegen. Wenn wir die Stichprobengröße erhöhen (von 10 auf 20 auf 30), würden immer mehr Stichprobenmittelwerte näher an den Grundgesamtheitsmittelwert heranrücken. Daher sollte der Durchschnitt (Mittelwert) dieser Mittelwerte mehr oder weniger dem Bevölkerungsmittelwert entsprechen. Betrachten Sie den Extremfall, bei dem die Stichprobengröße gleich der Populationsgröße ist. Für jede Stichprobe wäre der Mittelwert also derselbe wie der Grundgesamtheitsmittelwert. Dies ist die engste Verteilung (Standardabweichung der Stichprobenmittelwerte, hier 0). Wenn wir also die Stichprobengröße erhöhen (von 10 auf 20 auf 30), nimmt die Standardabweichung tendenziell ab (da die Streuung in der Stichprobenverteilung begrenzt wäre und ein größerer Teil der Stichprobenmittelwerte auf den Grundgesamtheitsmittelwert ausgerichtet wäre). Dieses Phänomen wird in der Formel in „Abb. 3“ erfasst, wo die Standardabweichung der Stichprobenverteilung umgekehrt proportional zur Quadratwurzel der Stichprobengröße ist. Wenn wir immer mehr Stichproben nehmen (von 1.000 über 5.000 bis 10.000), wäre die Stichprobenverteilung eine glattere Kurve, da sich mehr Stichproben gemäß dem zentralen Grenzwertsatz verhalten würden und das Muster sauberer wäre. "Reden ist billig. Zeig mir den Code!" - Linus Torvalds Lassen Sie uns also den zentralen Grenzwertsatz per Code simulieren: Einige Importe: import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math Erstellen Sie eine Population mit . Sie können verschiedene Verteilungen ausprobieren, um Daten zu generieren. Der folgende Code generiert eine (sozusagen) monoton fallende Verteilung: random.randint() def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population Erstellen Sie Stichproben und ermitteln Sie deren mittlere Anzahl: sample_count def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list Funktion zum Plotten der Datenverteilung zusammen mit einigen Beschriftungen. def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show() Die Hauptfunktion zum Ausführen des Codes: def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True) Den gesamten Code finden Sie . hier auf GitHub Verweise: Zentraler Grenzwertsatz in Aktion Zentraler Grenzwertsatz: eine praktische Anwendung Einführung in den zentralen Grenzwertsatz Eine sanfte Einführung in den zentralen Grenzwertsatz für maschinelles Lernen Zentraler Grenzwertsatz Bildnachweis des Titelbilds: Casey Dunn & Creature Cast auf Vimeo Empfohlene Lektüre (empfohlene Videos): Khanacademy/zentraler Grenzwertsatz Statistiken zu Machine Learning Data Science Auch veröffentlicht hier