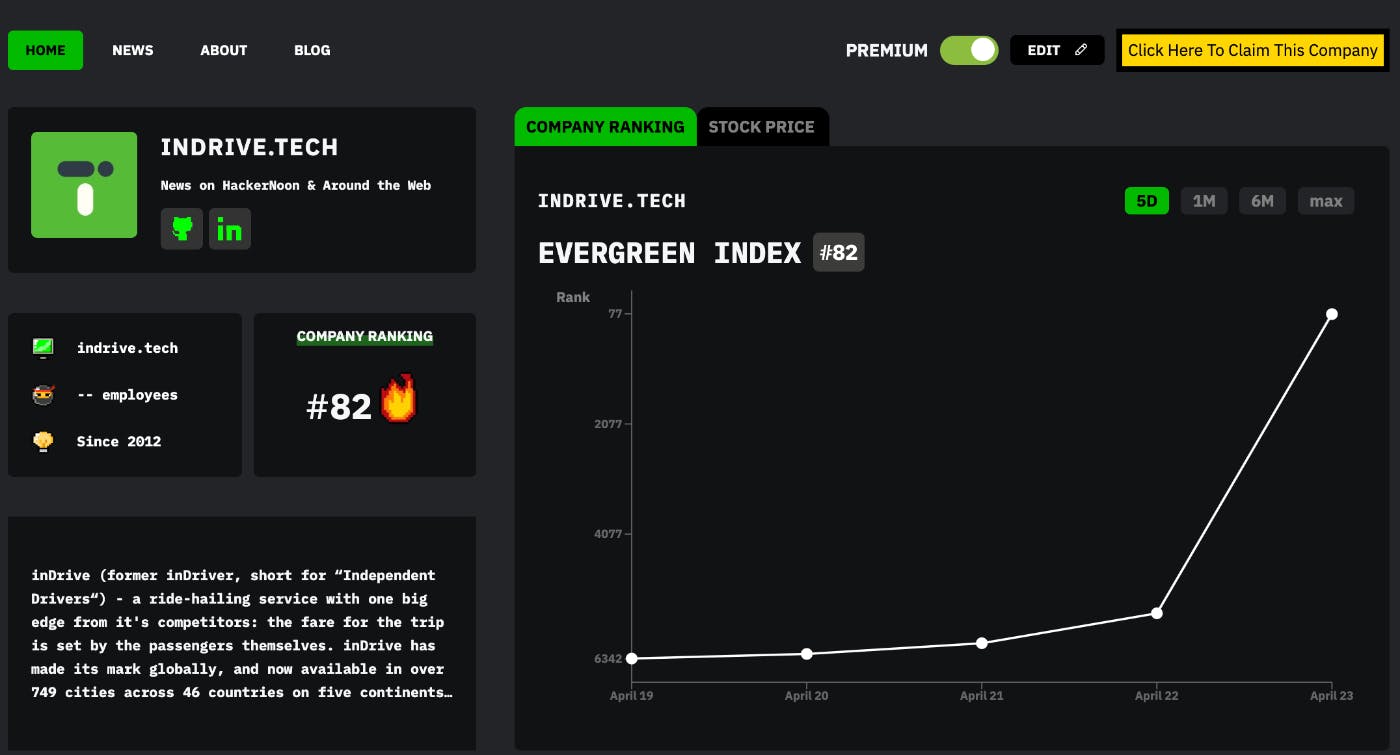
```html Forfattere: Neereja Sundaresan Theodore J. Yoder Youngseok Kim Muyuan Li Edward H. Chen Grace Harper Ted Thorbeck Andrew W. Cross Antonio D. Córcoles Maika Takita Abstrakt Kvantefejlkorrektion tilbyder en lovende vej til at udføre kvanteberegninger med høj troværdighed. Selvom fuldt fejltolerante udførelser af algoritmer endnu ikke er realiseret, muliggør nylige forbedringer i kontrol elektronik og kvantehardware stadig mere avancerede demonstrationer af de nødvendige operationer for fejlkodning. Her udfører vi kvantefejlkodning på superledende qubits forbundet i et tungt-hexagon gitter. Vi koder en logisk qubit med distance tre og udfører adskillige runder af fejltolerante syndrommålinger, der muliggør korrektion af enhver enkelt fejl i kredsløbet. Ved hjælp af feedback i realtid nulstiller vi syndrom- og flag-qubits betinget efter hver syndromudvindingscyklus. Vi rapporterer afhængig logisk fejl af afkodning, med gennemsnitlig logisk fejl pr. syndrommåling i Z(X)-basis på ~0,040 (~0,088) og ~0,037 (~0,087) for matchende og maksimum likelihood afkodere, henholdsvis, på leakage post-selected data. Introduktion Resultaterne af kvanteberegninger kan i praksis være fejlbehæftede på grund af støj i hardwaren. For at eliminere de resulterende fejl kan kvantefejlkodnings (QEC) koder bruges til at kode kvanteinformation ind i beskyttede, logiske frihedsgrader, og derefter muliggøre fejltolerante (FT) beregninger ved at korrigere fejlene hurtigere, end de akkumuleres. En komplet udførelse af QEC vil sandsynligvis kræve: forberedelse af logiske tilstande; realisering af et universelt sæt af logiske gates, som kan kræve forberedelse af magiske tilstande; gentagne målinger af syndromer; og afkodning af syndromerne til korrigering af fejl. Hvis det lykkes, bør de resulterende logiske fejlrater være lavere end de underliggende fysiske fejlrater og falde med stigende kodestørrelser ned til ubetydelige værdier. Valget af en QEC-kode kræver overvejelse af den underliggende hardware og dens støjegenskaber. For et tungt-hexagon gitter [1, 2] af qubits er subsystem QEC-koder [3] attraktive, da de er velegnede til qubits med reducerede forbindelser. Andre koder har vist sig lovende på grund af deres relativt høje tærskel for FT [4] eller store antal transversale logiske gates [5]. Selvom deres plads- og tidsomkostninger kan udgøre en betydelig hindring for skalerbarhed, findes der opmuntrende tilgange til at reducere de dyreste ressourcer ved at udnytte en form for fejlavskærmning [6]. I afkodningsprocessen afhænger succesfuld korrektion ikke kun af kvantehardwarens ydeevne, men også af implementeringen af kontrol elektronikken, der bruges til at indsamle og behandle de klassiske oplysninger opnået fra syndrommålinger. I vores tilfælde kan initialisering af både syndrom- og flag-qubits via feedback i realtid mellem målingscyklusser hjælpe med at afskærme fejl. På afkodningsniveauet, mens der eksisterer protokoller til at udføre QEC asynkront inden for en FT-formalisme [7, 8], bør raten, hvormed fejl-syndromerne modtages, være passende til deres klassiske behandlingstid for at undgå en stigende backlog af syndromdata. Desuden kræver nogle protokoller, som f.eks. brugen af en magisk tilstand for en logisk T-gate [9], anvendelsen af realtids feedback. Således er den langsigtede vision for QEC ikke centreret omkring et enkelt ultimativt mål, men bør ses som et kontinuum af dybt indbyrdes forbundne opgaver. Den eksperimentelle vej i udviklingen af denne teknologi vil omfatte demonstrationen af disse opgaver isoleret først og deres gradvise kombination senere, altid mens de tilhørende metrikker løbende forbedres. Nogle af disse fremskridt afspejles i adskillige nylige fremskridt inden for kvantesystemer på tværs af forskellige fysiske platforme, som har demonstreret eller approksimeret flere aspekter af de ønskede FT kvantecomputing. Især er FT logisk tilstandsforberedelse blevet demonstreret på ioner [10], nukleare spins i diamant [11] og superledende qubits [12]. Gentagne cyklusser af syndromudvinding er blevet vist i superledende qubits i små fejldetekterende koder [13, 14], herunder delvis fejlkodning [15] samt et universelt (omend ikke FT) sæt af enkelt-qubit gates [16]. En FT demonstration af et universelt gatesæt på to logiske qubits er for nylig blevet rapporteret i ioner [17]. Inden for fejlkodning har der været nylige realiseringer af distance-3 overfladekoden på superledende qubits med afkodning [18] og post-selection [19], samt en FT implementering af et dynamisk beskyttet kvantehukommelses ved hjælp af farvekoden [20] og FT tilstandsforberedelse, operation og måling, inklusive dens stabilisatorer, af en logisk tilstand i Bacon-Shor koden i ioner [20, 21]. Her kombinerer vi evnen til feedback i realtid på et superledende qubitsystem med en maksimum likelihood afkodningsprotokol, der hidtil ikke er blevet undersøgt eksperimentelt, for at forbedre overlevelsen af logiske tilstande. Vi demonstrerer disse værktøjer som en del af FT-operationen af en subsystemkode [22], den tunge-hexagon kode [1], på en superledende kvante processor. Afgørende for at gøre vores implementering af denne kode fejltolerant er flag-qubits, som, når de findes at være ikke-nul, advarer afkodningen om kredsløbsfejl. Ved betinget at nulstille flag- og syndrom-qubits efter hver syndrommålingscyklus beskytter vi vores system mod fejl, der opstår fra støj-asymmetrien, der er iboende i energirelaksering. Vi udnytter yderligere nyligt beskrevne afkodningsstrategier [15] og udvider afkodningsidéerne til at inkludere maksimum likelihood-koncepter [4, 23, 24]. Resultater Den tunge-hexagon kode og multi-runde kredsløb Den tunge-hexagon kode, vi betragter, er en n = 9 qubit kode, der koder k = 1 logisk qubit med distance d = 3 [1]. Z- og X-gauge (se Fig. 1a) og stabilisatorgrupperne genereres af Stabilisatorgrupperne er centrene af de respektive gauge-grupper. Dette betyder, at stabilisatorerne, som produkter af gauge-operatorer, kan udledes af målinger af kun gauge-operatorerne. Logiske operatorer kan vælges som XL = X1X2X3 og ZL = Z1Z3Z7. Z (blå) og X (rød) gauge-operatorer (ligninger (1) og (2)) afbildet på de 23 qubits, der kræves med distance-3 tunge-hexagon koden. Kode-qubits (Q1–Q9) vises i gult, syndrom-qubits (Q17, Q19, Q20, Q22) brugt til Z-stabilisatorer i blåt, og flag-qubits og syndromer brugt i X-stabilisatorer i hvidt. Rækkefølgen og retningen af CX gates anvendt inden for hver undersektion (0 til 4) angives af de nummererede pile. Kredsløbsdiagram for en enkelt syndrommålingsrunde, inklusive både X- og Z-stabilisatorer. Kredsløbsdiagrammet illustrerer tilladt parallelisering af gate-operationer: dem inden for grænserne sat af tidsplanlægningsbarrierer (lodrette stiplede grå linjer). Da varigheden af hver to-qubit gate er forskellig, bestemmes den endelige gate-tidsplanlægning med en standard "så-sen-som-muligt" kredsløbstranspileringspassage; hvorefter dynamisk afkobling tilføjes til data-qubits, hvor tiden tillader det. Målings- og nulstillingsoperationer er isoleret fra andre gate-operationer af barrierer for at tillade ensartet dynamisk afkobling at blive tilføjet til idlende data-qubits. Afkodningsgrafer for tre runder af ( ) Z- og ( ) X-stabilisatormålinger med kredsløbsniveau-støj muliggør korrektion af henholdsvis X- og Z-fejl. De blå og røde knudepunkter i graferne svarer til forskels-syndromer, mens de sorte knudepunkter er grænsen. Kanter repræsenterer forskellige måder, fejl kan opstå i kredsløbet som beskrevet i teksten. Knudepunkter er mærket med typen af stabilisatormåling (Z eller X), sammen med et subscript, der indekserer stabilisatoren, og superscripts, der angiver runden. Sorte kanter, der opstår fra Pauli Y-fejl på kode-qubits (og er derfor kun størrelse-2), forbinder de to grafer i og , men bruges ikke i matchende afkodning. Hyperkanter af størrelse-4, som ikke bruges af matching, men bruges i maksimum likelihood afkodningen. Farver er kun for klarhed. Tidsmæssig oversættelse af hver af disse giver også en gyldig hyperkant (med en vis variation ved tidsgrænserne). Heller ikke vist er nogen af hyperkanterne af størrelse-3. a b c d e c d f Her fokuserer vi på et specifikt FT-kredsløb; mange af vores teknikker kan bruges mere generelt med forskellige koder og kredsløb. To underkredsløb, vist i Fig. 1b, er konstrueret til at måle X- og Z-gauge-operatorerne. Z-gauge-målingskredsløbet opnår også nyttig information ved at måle flag-qubits. Vi forbereder kodetilstande i den logiske |0⟩ (|1⟩) tilstand ved først at forberede ni qubits i |+⟩ (|-⟩) tilstanden og måle X-gauge (Z-gauge). Vi udfører derefter r runder af syndrommåling, hvor en runde består af en Z-gauge måling efterfulgt af en X-gauge måling (henholdsvis X-gauge efterfulgt af Z-gauge). Til sidst aflæser vi alle ni kode-qubits i Z (X) basis. Vi udfører de samme eksperimenter for de indledende logiske tilstande |+⟩ og |-⟩ også, ved simpelthen at initialisere de ni qubits i |+⟩ og |-⟩ i stedet. Afkodningsalgoritmer I rammen for FT kvantecomputing er en afkoder en algoritme, der tager syndrommålinger fra en fejlkodningskode som input og udskriver en korrektion til qubits eller måledata. I dette afsnit beskriver vi to afkodningsalgoritmer: perfekt matchende afkodning og maksimum likelihood afkodning. Afkodningshypergrafen [15] er en kortfattet beskrivelse af den information, der er indsamlet af et FT-kredsløb og gjort tilgængelig for en afkodningsalgoritme. Den består af et sæt af knudepunkter, eller fejl-følsomme begivenheder, V, og et sæt af hyperkanter E, som koder korrelationerne mellem begivenheder forårsaget af fejl i kredsløbet. Fig. 1c–f afbilder dele af afkodningshypergrafen for vores eksperiment. Konstruktion af en afkodningshypergraf for stabilisatorkredsløb med Pauli-støj kan gøres ved hjælp af standard Gottesman-Knill simuleringer [25] eller lignende Pauli-sporingsmetoder [26]. Først oprettes en fejl-følsom begivenhed for hver måling, der er deterministisk i det fejlfri kredsløb. En deterministisk måling M er enhver måling, hvis resultat m ∈ {0, 1} kan forudsiges ved at addere modulo to måleresultaterne fra et sæt {Mi} af tidligere målinger. Det vil sige, for et fejlfri kredsløb, m = ΣMi (mod 2), hvor sættet {Mi} kan findes ved simulering af kredsløbet. Sæt værdien af den fejl-følsomme begivenhed til m − FM(mod 2), som er nul (også kaldet triviel) i fravær af fejl. Derfor indebærer observationen af en ikke-nul (også kaldet ikke-triviel) fejl-følsom begivenhed, at kredsløbet har lidt mindst én fejl. I vores kredsløb er fejl-følsomme begivenheder enten flag-qubit målinger eller forskellen af efterfølgende målinger af den samme stabilisator (også undertiden kaldet forskels-syndromer). Dernæst tilføjes hyperkanter ved at overveje kredsløbsfejl. Vores model indeholder en fejl-sandsynlighed pC for hver af flere kredsløbskomponenter Her skelner vi identitetsoperationen id på qubits under en tid, hvor andre qubits gennemgår unitære gates, fra identitetsoperationen idm på qubits, når andre gennemgår måling og nulstilling. Vi nulstiller qubits efter de er målt, mens vi initialiserer qubits, der endnu ikke er brugt i eksperimentet. Endelig er cx controlled-not gate, h Hadamard gate, og x, y, z Pauli gates. (se Metode "IBM_Peekskill og eksperimentelle detaljer" for flere detaljer). Numeriske værdier for pC er angivet i Metode "IBM_Peekskill og eksperimentelle detaljer". Vores fejlmodel er kredsløbs-depolariserende støj. For initialiserings- og nulstillingsfejl påføres en Pauli X med de respektive sandsynligheder pinit og presæt efter den ideelle tilstandsforberedelse. For målingsfejl påføres en Pauli X med sandsynlighed px før den ideelle måling. En en-qubit unitær gate (to-qubit gate) C lider med sandsynlighed pC en af de tre (femten) ikke-identitets en-qubit (to-qubit) Pauli-fejl efter den ideelle gate. Der er lige stor sandsynlighed for, at enhver af de tre (femten) Pauli-fejl forekommer. Når en enkelt fejl forekommer i kredsløbet, forårsager det, at en delmængde af fejl-følsomme begivenheder bliver ikke-triviel. Dette sæt af fejl-følsomme begivenheder bliver en hyperkant. Sættet af alle hyperkanter er E. To forskellige fejl kan føre til den samme hyperkant, så hver hyperkant kan betragtes som repræsenterende et sæt af fejl, hvoraf hver enkelt individuelt får begivenhederne i hyperkanten til at være ikke-triviel. Tilknyttet hver hyperkant er en sandsynlighed, som i første omgang er summen af sandsynlighederne for fejl i sættet. En fejl kan også føre til en fejl, der, når den forplantes til slutningen af kredsløbet, antikommuterer med en eller flere af kodens logiske operatorer, hvilket nødvendiggør en logisk korrektion. Vi antager generelt, at koden har k logiske qubits og en basis af 2k logiske operatorer, men bemærk k = 1 for den tunge-hexagon kode, der bruges i eksperimentet. Vi kan holde styr på, hvilke logiske operatorer der antikommuterer med fejlen ved hjælp af en vektor fra {−1, 1}^k. Derfor er hver hyperkant h også mærket med en af disse vektorer, kaldet en logisk etiket. Bemærk, at hvis koden har afstand mindst tre, har hver hyperkant en unik logisk etiket. Endelig bemærker vi, at en afkodningsalgoritme kan vælge at forenkle afkodningshypergrafen på forskellige måder. En måde, vi altid anvender her, er processen med deflagging. Flag-målinger fra qubits 16, 18, 21, 23 ignoreres simpelthen uden korrektioner anvendes. Hvis flag 11 er ikke-triviel og 12 triviel, anvendes Z på 2. Hvis 12 er ikke-triviel og 11 triviel, anvendes Z på qubit 6. Hvis flag 13 er ikke-triviel og 14 triviel, anvendes Z på qubit 4. Hvis 14 er ikke-triviel og 13 triviel, anvendes Z på qubit 8. Se ref. [15] for detaljer om, hvorfor dette er tilstrækkeligt for fejltolerance. Dette betyder, at i stedet for at inkludere fejl-følsomme begivenheder fra flag-qubit målingerne direkte, forbehandler vi dataene ved at bruge flag-informationen til at anvende virtuelle Pauli Z-korrektioner og justere efterfølgende fejl-følsomme begivenheder i overensstemmelse hermed. Hyperkanter for den deflaggede hypergraf kan findes gennem stabilisator-simulering, der inkorporerer Z-korrektionerne. Lad r angive antallet af runder. Efter deflagging er størrelsen af sættet V for Z (hhv. X-basis) eksperimenter |V| = 6r + 2 (hhv. 6r + 4), på grund af måling af seks stabilisatorer pr. runde og at have to (hhv. fire) indledende fejl-følsomme stabilisatorer efter tilstandsforberedelse. Størrelsen af E er ligeledes |E| = 60r − 13 (hhv. 60r − 1) for r > 0. Med hensyn til X- og Z-fejl separat kan problemet med at finde en minimum vægt fejlkodning for overfladekoden reduceres til at finde en minimum vægt perfekt matching i en graf [4]. Matchende afkodere fortsætter med at blive undersøgt på grund af deres praktiske anvendelighed [27] og brede anvendelighed [28, 29]. I dette afsnit beskriver vi den matchende afkoder for vores distance-3 tunge-hexagon kode. Afkodningsgraferne, én for X-fejl (Fig. 1c) og én for Z-fejl (Fig. 1d), for minimum vægt perfekt matching er faktisk undergrafer af afkodningshypergrafen i det foregående afsnit. Lad os her fokusere på grafen for korrektion af X-fejl, da Z-fejl grafen er analog. I dette tilfælde, fra afkodningshypergrafen, beholder vi knudepunkter VZ, der svarer til (forskellen af efterfølgende) Z-stabilisatormålinger og kanter (dvs. hyperkanter med størrelse to) imellem dem. Derudover oprettes et grænse-knudepunkt b, og kanter af størrelse 1 af formen {v} med v ∈ VZ, repræsenteres ved at inkludere kanter {v, b}. Alle kanter i X-fejl grafen arver sandsynligheder og logiske etiketter fra deres tilsvarende hyperkanter (se Tabel 1 for X- og Z-fejl kantdata for 2-runde eksperiment). En perfekt matching-algoritme tager en graf med vægtede kanter og et lige antal fremhævede knudepunkter og returnerer et sæt af kanter i grafen, der forbinder alle fremhævede knudepunkter parvis og har en minimum totalvægt blandt alle sådanne kant-sæt. I vores tilfælde er fremhævede knudepunkter de ikke-trivielle fejl-følsomme begivenheder (hvis der er et ulige antal, er grænse-knudepunktet også fremhævet), og kantvægte er enten valgt til alle at være én (uniform metode) eller sat som log(P(e)) = Σ log(pe), hvor pe er kant-sandsynligheden (analytisk metode). Sidstnævnte valg betyder, at den totale vægt af et kant-sæt er lig med log-likelihood af det sæt, og minimum vægt perfekt matching forsøger at maksimere denne likelihood over kanterne i grafen. Givet en minimum vægt perfekt matching, kan man bruge de logiske etiketter af kanterne i matchet til at bestemme en korrektion af den logiske tilstand. Alternativt er X-fejl (Z-fejl) grafen for matchende afkodning sådan, at hver kant kan associeres med en kode-qubit (eller en målingsfejl), således at inkludering af en kant i matchet indebærer en X (Z) korrektion, der skal anvendes på den tilsvarende qubit. Maksimum likelihood afkodning (MLD) er en optimal, omend ikke-skalerbar, metode til afkodning af kvante-fejlkodningskoder. I sin oprindelige opfattelse blev MLD anvendt på fænomenologiske støjmodeller, hvor fejl kun opstår lige før syndromer måles [24, 30]. Dette ignorerer naturligvis det mere realistiske tilfælde, hvor fejl kan forplante sig gennem syndrommålingskredsløbet. Mere for nylig er MLD blevet udvidet til at inkludere kredsløbsstøj [23, 31]. Her beskriver vi, hvordan MLD korrigerer kredsløbsstøj ved hjælp af afkodningshypergrafen. MLD udleder den mest sandsynlige logiske korrektion givet en observation af de fejl-følsomme begivenheder. Dette gøres ved at beregne sandsynlighedsfordelingen Pr[β, γ], hvor β repræsenterer fejl-følsomme begivenheder, og γ repræsenterer en logisk korrektion. Vi kan beregne Pr[β, γ] ved at inkludere hver hyperkant fra afkodningshypergrafen, Fig. 1c–f, startende fra nul-fejlfordelingen, dvs. Pr[0^{|V|}, 0^{2^k}] = 1. Hvis hyperkanten h har sandsynligheden ph for at forekomme, uafhængigt af enhver anden hyperkant, inkluderer vi h ved at udføre opdateringen hvor βh blot er en binær vektorrepræsentation af hyperkanten. Denne opdatering bør foretages én gang for hver hyperkant i E. Når Pr[β, γ] er beregnet, kan vi bruge den til at udlede den bedste logiske korrektion. Hvis β* observeres i et kørselsforsøg, angiver den marginale sandsynlighed ∑γ Pr[β*, γ] hvordan målinger af de logiske operatorer bør korrigeres. For flere detaljer om specifikke implementeringer af MLD, se Metode "Maximum likelihood implementations". Eksperimentel realisering Til denne demonstration bruger vi ibm_peekskill v2.0.0, en 27-qubit IBM Quantum Falcon processor [32], hvis koblingskort muliggør en distance-3 tung-hexagon kode, se Fig. 1. Den samlede tid for qubit-måling og efterfølgende betinget nulstilling i realtid, for hver runde, tager 768ns og er den samme for alle qubits. Alle syndrommålinger og nulstillinger sker samtidigt for forbedret ydeevne. En simpel Xπ-Xπ dynamisk afkoblingssekvens tilføjes til alle kode-qubits under deres respektive idlende perioder. Qubit-lækage er en væsentlig årsag til, at den Pauli depolariserende fejlmodel, som afkodningsdesignet antager, muligvis er unøjagtig. I nogle tilfælde kan vi detektere, om en qubit er lækket ud af beregningsunderlaget på det tidspunkt, den måles (se Metode "Post-selection method" for mere information om post-selection metoden og begrænsninger). Ved at bruge dette kan vi post-selecte på kørsler af eksperimentet, når lækage ikke er blevet detekteret, ligesom i ref. [18]. I Fig. 2a initialiserer vi den logiske tilstand |0⟩, og anvender r syndrommålingsrunder, hvor én runde inkluderer både X- og Z-stabilisatorer (total tid på ca. 5,3 μs pr. runde, Fig. 1b). Ved at bruge analytisk perfekt matchende afkodning på det fulde datasæt (500.000 skud pr. runde), udtrækker vi de logiske fejl i Fig. 2a, røde (blå) trekanter. Detaljer om optimerede parametre brugt i analytisk perfekt matchende afkodning kan findes i Metode "IBM_Peekskill og eksperimentelle detaljer". Ved at tilpasse de fulde henfaldskurver (ligning (14)) op til 10 runder, udtrækker vi logisk fejl pr. runde uden post-selection i Fig. 2b på 0,059(2) (0,058(3)) for |0⟩ (|1⟩) og 0,113(5) (0,107(4)) for |+⟩ (|−⟩). Logisk fejl versus antal syndrommålingsrunder r, hvor én runde inkluderer både en Z- og en X-stabilisatormåling. Blå højrepegende trekanter (røde trekanter) markerer logiske fejl opnået fra brug af matchende analytisk afkodning på rå eksperimentelle data for |0⟩ (|1⟩) tilstande. Lyseblå firkanter (lyserøde cirkler) markerer dem for |+⟩ (|−⟩) med samme afkodningsmetode, men ved brug af leakage-post-selected eksperimentelle data. Fejlmargener angiver samplingfejl for hver kørsel (500.000 skud for rå data, variabelt antal skud for post-selected). Stiplede linjer passer fejl giver fejl pr. runde plottet i . Anvendelse af den samme afkodningsmetode på leakage-post-selected data viser en betydelig reduktion i den samlede fejl for alle fire logiske tilstande. Se Metode "Post-selection method" for detaljer om post-selection. Tilpasset afvisningsrate pr. runde for |0⟩, |1⟩, |+⟩, |−⟩ er henholdsvis 4,91%, 4,64%, 4,37% og 4,89%. Fejlmargener angiver én standardafvigelse på den tilpassede rate. , Ved brug af post-selected data sammenligner vi den logiske fejl opnået med de fire afkodere: matchende uniform (pink cirkler), matchende analytisk (grønne cirkler), matchende analytisk med soft information (grå cirkler) og maksimum likelihood (blå cirkler). (Se Fig. 6 for |+⟩ og |−⟩). Stiplede tilpassede rater præsenteret i , . Fejlmargener angiver samplingfejl. , Sammenligning af tilpasset fejl pr. runde for alle fire logiske tilstande ved brug af matchende uniform (pink), matchende analytisk (grøn), matchende analytisk med soft information (grå) og maksimum likelihood (blå) afkodere på leakage-post-selected data. Fejlmargener repræsenterer én standardafvigelse på den tilpassede rate. a b b c d e f e f Anvendelse af den samme afkodningsmetode på leakage-post-selected data reducerer logiske fejl i Fig. 2a og giver tilpassede fejl-rater på 0,041(1) (0,044(4)) for |0⟩ (|1⟩) og 0,088(3) (0,085(3)) for |+⟩ (|−⟩), som vist i Fig. 2b. Afvisningsrater pr. runde fra post-selection for |0⟩, |1⟩, |+⟩, og |−⟩ er henholdsvis 4,91%, 4,64%, 4,37% og 4,89%. Se Metode "Post-selection method" for detaljer. I Fig. 2c–f sammenligner vi den logiske fejl for hver runde og den udtrådte logiske fejl pr. runde opnået fra de post-selected datasæt ved brug af de tre afkodere beskrevet tidligere i Afsnittet "Afkodningsalgoritmer". Vi inkluderer også en version af den analytiske afkoder, der udnytter soft-information [33], som er beskrevet i Metode "Soft-information decoding". Vi observerer (se Fig. 2e, f) en konsekvent forbedring i afkodning ved at bevæge sig fra matchende uniform (pink) til matchende analytisk (grøn) til matchende analytisk med soft information til maksimum likelihood (grå), selvom dette er meget mindre signifikant for X-basis logiske tilstande. En kvantitativ sammenligning mellem de tre afkodere for alle fire logiske tilstande ved r = 2 runder er givet i Metode "Logical error at r = 2 rounds". Der er mindst tre grunde til, at X-basis tilstande klarer sig dårligere end Z-basis. Den første er den naturlige asymmetri i kredsløbene. Den større dybde, der kræves til at måle Z-stabilisatorer, fører til mere tid, hvor Z-fejl på data-qubits kan akkumuleres uopdaget. Dette understøttes af simuleringer, som dem i [1], der bruger en anden afkoder, og her i Metode "Simulation details", som ser dårligere ydeevne af X-basis for denne d = 3 kode. For det andet kan valg truffet under afkodningen, især deflagging-trinnet, forværre asymmetrien ved effektivt at konvertere målings- og nulstillingsfejl til Z-fejl på data-qubits. Dette fører til en høj effektiv Z-fejlrate, der ikke kan forbedres meget, selv med maksimum likelihood afkodning. I modsætning hertil, hvis vi kun defl