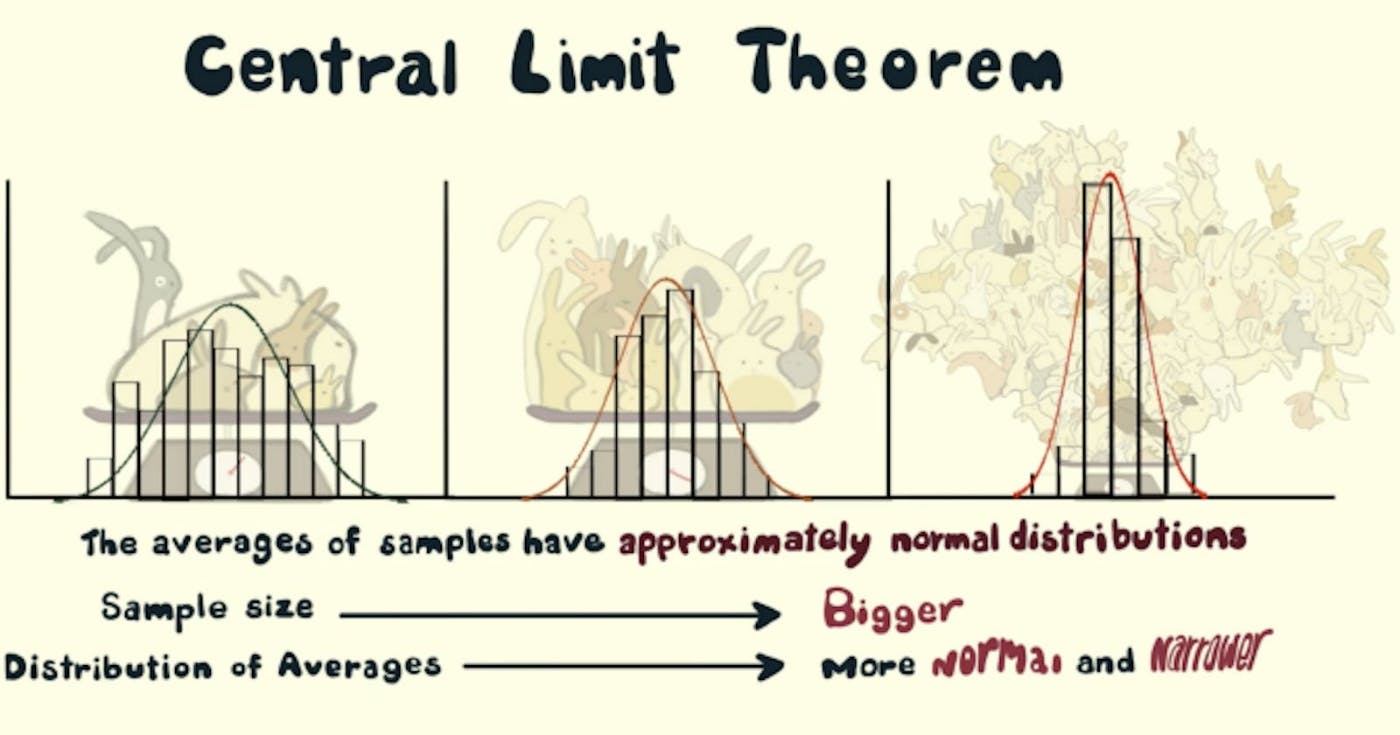
সংজ্ঞা, তাৎপর্য, এবং অ্যাপ্লিকেশন TLDR: আপনি পুরো কোডটি খুঁজে পেতে পারেন। এখানে GitHub-এ কেন্দ্রীয় সীমা উপপাদ্য নিম্নলিখিত ঘটনাটি ক্যাপচার করে: কোন বন্টন নিন! (ফুটবল ম্যাচে পাসের সংখ্যার বন্টন বলুন) সেই বিতরণ থেকে n নমুনা নেওয়া শুরু করুন (বলুন n = 5) একাধিক বার [m = 1000] বার। প্রতিটি নমুনা সেটের গড় নিন (তাই আমাদের হবে m = 1000 মানে) উপায়ের বন্টন (কম বা কম) হবে। (যদি আপনি x-অক্ষের উপর মাধ্যম এবং y-অক্ষের উপর তাদের ফ্রিকোয়েন্সি প্লট করেন তবে আপনি সেই বিখ্যাত ঘণ্টা বক্ররেখা পাবেন।) সাধারণত বিতরণ করা একটি ছোট প্রমিত বিচ্যুতি পেতে n বাড়ান এবং স্বাভাবিক বণ্টনের আরও ভাল অনুমান পেতে m বাড়ান। কিন্তু কেন আমার যত্ন নেওয়া উচিত? আপনি প্রক্রিয়াকরণের জন্য পুরো ডেটা লোড করতে অক্ষম? কোন সমস্যা নেই, ডেটা থেকে একাধিক নমুনা নিন এবং গড়, মানক বিচ্যুতি, যোগফল ইত্যাদির মতো ডেটা প্যারামিটারগুলি অনুমান করতে কেন্দ্রীয় সীমা উপপাদ্য ব্যবহার করুন। এটি সময় এবং অর্থের পরিপ্রেক্ষিতে আপনার সম্পদ সংরক্ষণ করতে পারে। কারণ এখন, আমরা জনসংখ্যার তুলনায় উল্লেখযোগ্যভাবে ছোট নমুনাগুলিতে কাজ করতে পারি এবং সমগ্র জনসংখ্যার জন্য অনুমান আঁকতে পারি! একটি নির্দিষ্ট নমুনা কি একটি নির্দিষ্ট জনসংখ্যার (বা একটি ডেটা সেট) অন্তর্গত? আসুন পরীক্ষা করে দেখি যে নমুনা ব্যবহার করে, জনসংখ্যার মানে, নমুনা মানক বিচ্যুতি এবং জনসংখ্যার মান বিচ্যুতি। সংজ্ঞা একটি অজানা বন্টন সহ একটি ডেটাসেট দেওয়া (এটি অভিন্ন, দ্বিপদ বা সম্পূর্ণ র্যান্ডম হতে পারে), নমুনা মানে স্বাভাবিক বন্টনের আনুমানিক হবে। ব্যাখ্যা যদি আমরা কোনো ডেটাসেট বা জনসংখ্যা নিই এবং আমরা জনসংখ্যা থেকে নমুনা নেওয়া শুরু করি, ধরা যাক আমরা 10টি নমুনা নিই এবং সেই নমুনার গড় নিই, এবং আমরা এটি করতে থাকি, কয়েকবার, 1000 বার বলুন, এটি করার পরে, আমরা 1000 উপায় পাই এবং যখন আমরা এটি প্লট করি, তখন আমরা একটি বিতরণ পাই যার নাম নমুনা অর্থের নমুনা বিতরণ। এই নমুনা বিতরণ (কম বা কম) একটি স্বাভাবিক বিতরণ অনুসরণ করে! এটি কেন্দ্রীয় সীমা উপপাদ্য। একটি সাধারণ বন্টনের বেশ কয়েকটি বৈশিষ্ট্য রয়েছে যা বিশ্লেষণের জন্য দরকারী। চিত্র.1 নমুনার নমুনা বিতরণ মানে (একটি স্বাভাবিক বিতরণ অনুসরণ করে) একটি স্বাভাবিক বিতরণের বৈশিষ্ট্য: গড়, মোড এবং মধ্যমা সবই সমান। 68% ডেটা গড়ের একটি আদর্শ বিচ্যুতির মধ্যে পড়ে। 95% ডেটা গড় দুটি আদর্শ বিচ্যুতির মধ্যে পড়ে। বক্ররেখা কেন্দ্রে প্রতিসম (অর্থাৎ, গড় চারপাশে, μ)। অধিকন্তু, নমুনা অর্থের নমুনা বিতরণের গড় জনসংখ্যা গড়ের সমান। যদি μ জনসংখ্যার গড় হয় এবং μX̅ হয় নমুনার গড়, তাহলে মানে: চিত্র.2 জনসংখ্যা গড় = নমুনা গড় এবং জনসংখ্যার আদর্শ বিচ্যুতি(σ) মানক বিচ্যুতি নমুনা বিতরণের (σX̅) সাথে নিম্নলিখিত সম্পর্ক রয়েছে: যদি σ জনসংখ্যার মানক বিচ্যুতি হয় এবং σX̅ হয় নমুনা অর্থের আদর্শ বিচ্যুতি, এবং n হয় নমুনার আকার, তাহলে আমাদের আছে Fig.3 জনসংখ্যার মান বিচ্যুতি এবং নমুনা বিতরণ মান বিচ্যুতির মধ্যে সম্পর্ক অন্তর্দৃষ্টি যেহেতু আমরা জনসংখ্যা থেকে একাধিক নমুনা নিচ্ছি, তাই অর্থ প্রকৃত জনসংখ্যার সমান (বা কাছাকাছি) হবে প্রায়শই নয়। তাই, আমরা প্রকৃত জনসংখ্যা গড়ের সমান নমুনার অর্থের নমুনা বিতরণে একটি শীর্ষ (মোড) আশা করতে পারি। একাধিক এলোমেলো নমুনা এবং তাদের উপায়গুলি প্রকৃত জনসংখ্যার অর্থের চারপাশে থাকবে। সুতরাং, আমরা অনুমান করতে পারি 50% অর্থ জনসংখ্যার গড় থেকে বেশি হবে এবং 50% তার থেকে কম হবে (মাঝারি)। যদি আমরা নমুনার আকার বাড়াই (10 থেকে 20 থেকে 30 পর্যন্ত), তাহলে আরও বেশি করে নমুনা মানে জনসংখ্যার গড়ের কাছাকাছি আসবে। সুতরাং, সেই উপায়গুলির গড় (গড়) জনসংখ্যার গড়ের সাথে কমবেশি একই হওয়া উচিত। চরম ক্ষেত্রে বিবেচনা করুন যেখানে নমুনার আকার জনসংখ্যার আকারের সমান। সুতরাং, প্রতিটি নমুনার জন্য, গড় জনসংখ্যার গড় হিসাবে একই হবে। এটি হল সংকীর্ণ বন্টন (নমুনার মান বিচ্যুতি মানে, এখানে 0)। তাই, আমরা নমুনার আকার বাড়ার সাথে সাথে (10 থেকে 20 থেকে 30 পর্যন্ত) প্রমিত বিচ্যুতি কমতে থাকে (কারণ নমুনা বিতরণে বিস্তার সীমিত হবে এবং বেশির ভাগ নমুনার উপায় জনসংখ্যার গড়ের দিকে ফোকাস করা হবে)। এই ঘটনাটি "চিত্র 3" এর সূত্রে ধরা হয়েছে যেখানে নমুনা বন্টনের মানক বিচ্যুতি নমুনা আকারের বর্গমূলের বিপরীতভাবে সমানুপাতিক। যদি আমরা আরও বেশি নমুনা নিই (1,000 থেকে 5,000 থেকে 10,000 পর্যন্ত), তাহলে নমুনা বিতরণ আরও মসৃণ বক্ররেখা হবে, কারণ বেশির ভাগ নমুনা কেন্দ্রীয় সীমা উপপাদ্য অনুযায়ী আচরণ করবে এবং প্যাটার্নটি পরিষ্কার হবে। "টক ইজ সস্তা, আমাকে কোড দেখান!" - লিনাস টরভাল্ডস সুতরাং, কোডের মাধ্যমে কেন্দ্রীয় সীমা উপপাদ্য অনুকরণ করা যাক: কিছু আমদানি: import random from typing import List import matplotlib.pyplot as plt import matplotlib import statistics import pandas as pd import math ব্যবহার করে একটি জনসংখ্যা তৈরি করুন। আপনি ডেটা জেনারেট করতে বিভিন্ন ডিস্ট্রিবিউশন চেষ্টা করতে পারেন। নিম্নলিখিত কোড একটি (বাছাই) একঘেয়ে হ্রাস বন্টন তৈরি করে: random.randint() def create_population(sample_size: int) -> List[int]: """Generate a population of sample_size Args: sample_size (int): The size of the population Returns: List[int]: a list of randomly generated integers """ population = [] for _ in range(sample_size): random_number = (random.randint(0, random.randint(1, 1000))) population.append(random_number) return population নমুনা তৈরি করুন, এবং তাদের গড় সংখ্যা নিন: sample_count def generate_sample_mean_list(population: List[int], sample_size: int, sample_count: int) -> List[int]: """From the population generate samples of sample_size, sample_count times Args: population (List[int]): List of random numbers sample_size (int): Number of elements in each sample sample_count (int): Number of sample means in sample_mean_list Returns: List[int]: a list of sample means """ sample_mean_list = [] for _ in range(sample_count): sample = random.sample(population, sample_size) sample_mean = statistics.mean(sample) sample_mean_list.append(sample_mean) return sample_mean_list কিছু লেবেল সহ ডেটা বিতরণ প্লট করার ফাংশন। def plot_hist(data: List[int], ax: matplotlib.axes.Axes, xlabel: str, ylabel: str, title: str, texts: List[str]) -> None: """Plot a histogram with labels and additional texts Args: data (List[int]): the list of data points to be plotted ax (matplotlib.axes.Axes): Axes object for text plotting xlabel (str): label on x axis ylabel (str): label on y axis title (str): title of the plot texts (List[str]): Additional texts to be plotted """ plt.hist(data, 100) plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) i = 0.0 for text in texts: plt.text(0.8, 0.8 - i, text, horizontalalignment="center", verticalalignment="center", transform=ax.transAxes) i += 0.05 plt.grid(True) plt.show() কোড চালানোর জন্য প্রধান ফাংশন: def main(plot=True): """Driver Function Args: plot (bool, optional): Decide whether to plot or not. Defaults to True. """ fig, ax = plt.subplots() population_size = int(1E5) population = create_population(population_size) if plot: plot_hist(population, ax, "Value", "Frequency", "Histogram of Population of Random Numbers", [f"population_size={population_size}"]) population_mean = statistics.mean(population) population_stdev = statistics.stdev(population) sample_size_list = [50, 500] sample_count_list = [500, 5000] records = [] for sample_size in sample_size_list: for sample_count in sample_count_list: sample_mean_list = generate_sample_mean_list( population, sample_size, sample_count) # also called as mean of sample distribution of sample means mean_of_sample_means = round(statistics.mean(sample_mean_list), 2) # also called standard dev of sample distribution of sample means std_error = round(statistics.stdev(sample_mean_list), 2) if plot: plot_hist(sample_mean_list, ax, "Mean Value", "Frequency", "Sampling Distribution of Sample Means", [ f"sample_count={sample_count}", f"sample_size={sample_size}", f"mean_of_sample_means={mean_of_sample_means}", f"std_error={std_error}"]) record = { "sample_size": sample_size, "sample_count": sample_count, "population_mean": population_mean, "sample_mean": mean_of_sample_means, "population_stdev": population_stdev, "population_stdev_using_formula": std_error*math.sqrt(sample_size), "sample_stdev": std_error, } records.append(record) df = pd.DataFrame(records) print(df) if __name__ == "__main__": main(plot=True) আপনি পুরো কোডটি খুঁজে পেতে পারেন। এখানে GitHub-এ তথ্যসূত্র: সেন্ট্রাল লিমিট থিওরেম ইন অ্যাকশন কেন্দ্রীয় সীমা উপপাদ্য: একটি বাস্তব-জীবনের প্রয়োগ কেন্দ্রীয় সীমা উপপাদ্যের ভূমিকা মেশিন লার্নিংয়ের জন্য কেন্দ্রীয় সীমা উপপাদ্যের একটি মৃদু ভূমিকা কেন্দ্রীয় সীমা উপপাদ্য কভার ইমেজ ক্রেডিট: কেসি ডান এবং ভিমিওতে ক্রিয়েচার কাস্ট সাজেস্টেড রিডিং (প্রস্তাবিত ভিডিও): khanacademy/কেন্দ্রীয়-সীমা-তত্ত্ব মেশিন লার্নিং ডেটা সায়েন্স পরিসংখ্যান এছাড়াও প্রকাশিত এখানে