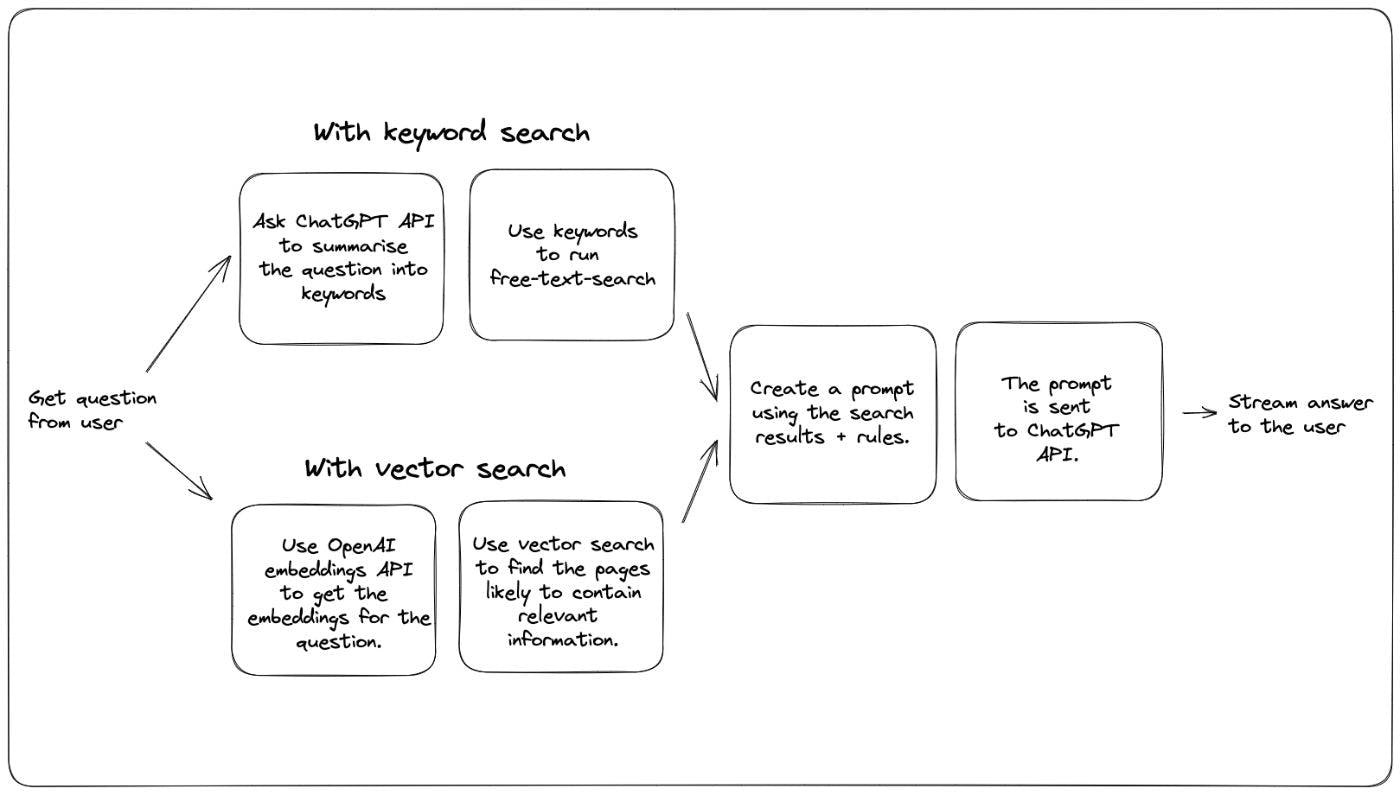
গত সপ্তাহে আমরা একটি প্রশ্নোত্তর বট যোগ করেছি যা থেকে প্রশ্নের উত্তর দেয়। এটি Xata ডকুমেন্টেশন থেকে প্রশ্নের উত্তর দেওয়ার জন্য ChatGPT প্রযুক্তির সাহায্য করে, যদিও OpenAI GPT মডেলটি Xata ডক্সে প্রশিক্ষিত ছিল না। আমাদের ডকুমেন্টেশন এই সাইমন উইলিসন দ্বারা প্রস্তাবিত একটি পদ্ধতি ব্যবহার করে আমরা এটি করতে পারি। একই পদ্ধতি একটি পাওয়া যাবে। ধারণা নিম্নোক্ত: ব্লগ পোস্টে OpenAI কুকবুকেও ব্যবহারকারীর জিজ্ঞাসা করা প্রশ্নের সাথে সবচেয়ে প্রাসঙ্গিক বিষয়বস্তু খুঁজে পেতে ডকুমেন্টেশনের বিরুদ্ধে একটি পাঠ্য অনুসন্ধান চালান। এই সাধারণ ফর্মের সাথে একটি প্রম্পট তৈরি করুন: With these rules: {rules} And this text: {context} Given the above text, answer the question: {question} Answer: ChatGPT API এ প্রম্পট পাঠান এবং মডেলটিকে উত্তরটি সম্পূর্ণ করতে দিন। আমরা খুঁজে পেয়েছি যে এটি বেশ ভাল কাজ করে এবং তুলনামূলকভাবে কম মডেলের তাপমাত্রার সাথে মিলিত হয় (তাপমাত্রার ধারণাটি এই ব্যাখ্যা করা হয়েছে), এটি সঠিক ফলাফল এবং কোড স্নিপেট তৈরি করে, যতক্ষণ না উত্তর পাওয়া যায় ডকুমেন্টেশন ব্লগ পোস্টে এই পদ্ধতির একটি মূল সীমাবদ্ধতা হল যে আপনি উপরের দ্বিতীয় ধাপে যে প্রম্পট তৈরি করবেন তাতে সর্বাধিক 4000 টোকেন (~3000 শব্দ) থাকতে হবে। এর মানে হল যে প্রথম ধাপ, সবচেয়ে প্রাসঙ্গিক নথি নির্বাচন করার জন্য পাঠ্য অনুসন্ধান, সত্যিই গুরুত্বপূর্ণ হয়ে ওঠে। যদি অনুসন্ধানের ধাপটি একটি ভাল কাজ করে এবং সঠিক প্রেক্ষাপট প্রদান করে, ChatGPT একটি সঠিক এবং টু-দ্য-পয়েন্ট ফলাফল তৈরিতেও একটি ভাল কাজ করতে থাকে। তাই ডকুমেন্টেশনে বিষয়বস্তুর সবচেয়ে প্রাসঙ্গিক টুকরা খুঁজে বের করার সেরা উপায় কি? ওপেনএআই কুকবুক, সেইসাথে সাইমনের ব্লগ, যাকে শব্দার্থিক অনুসন্ধান বলা হয় তা ব্যবহার করে। শব্দার্থিক অনুসন্ধান প্রশ্ন এবং বিষয়বস্তু উভয়ের জন্য এম্বেডিং তৈরি করতে ভাষা মডেলের সাহায্য করে। এমবেডিং হল সংখ্যার বিন্যাস যা বিভিন্ন মাত্রার পাঠ্যকে উপস্থাপন করে। অনুরূপ এমবেডিং আছে এমন টেক্সট টুকরা একই অর্থ আছে. এর মানে হল একটি ভাল কৌশল হল বিষয়বস্তুর টুকরোগুলি খুঁজে বের করা যা প্রশ্নের এমবেডিংয়ের সাথে সবচেয়ে অনুরূপ এমবেডিং। আরও ক্লাসিক্যাল কীওয়ার্ড অনুসন্ধানের উপর ভিত্তি করে আরেকটি সম্ভাব্য কৌশল দেখতে এইরকম: ChatGPT কে প্রশ্ন থেকে কীওয়ার্ড বের করতে বলুন, এইরকম একটি প্রম্পট সহ: Extract keywords for a search query from the text provided. Add synonyms for words where a more common one exists. বিনামূল্যে-পাঠ্য-অনুসন্ধান চালানোর জন্য প্রদত্ত কীওয়ার্ড ব্যবহার করুন এবং সেরা ফলাফল বাছাই করুন এটিকে একটি একক চিত্রে রাখলে, দুটি পদ্ধতি এইরকম দেখায়: আমরা আমাদের ডকুমেন্টেশন উভয়ই চেষ্টা করেছি এবং কিছু সুবিধা এবং অসুবিধা লক্ষ্য করেছি। আসুন কয়েকটি ফলাফল তুলনা করে শুরু করা যাক। উভয়ই একই ডাটাবেসের বিরুদ্ধে চালানো হয় এবং তারা উভয়েই ChatGPT মডেল ব্যবহার করে। যেহেতু এলোমেলোতা জড়িত, আমি প্রতিটি প্রশ্ন 2-3 বার দৌড়েছি এবং বাছাই করেছি যা আমার কাছে সেরা ফলাফলের মত লাগছিল। gpt-3.5-turbo প্রশ্ন: আমি কিভাবে Xata CLI ইনস্টল করব? ভেক্টর অনুসন্ধান সহ উত্তর: কীওয়ার্ড অনুসন্ধানের সাথে উত্তর দিন: : উভয় সংস্করণই সঠিক উত্তর দিয়েছে, তবে ভেক্টর অনুসন্ধানটি একটু বেশি সম্পূর্ণ। তারা উভয়ই এটির জন্য সঠিক ডক্স পৃষ্ঠা খুঁজে পেয়েছে, কিন্তু আমি মনে করি আমাদের হাইলাইট-ভিত্তিক হিউরিস্টিক কীওয়ার্ড কৌশলের ক্ষেত্রে পাঠ্যের একটি ছোট অংশ বেছে নিয়েছে। রায় বিজয়ী: ভেক্টর অনুসন্ধান। স্কোর: 1-0 প্রশ্ন: আপনি Deno এর সাথে Xata কিভাবে ব্যবহার করবেন? ভেক্টর অনুসন্ধান সহ উত্তর: কীওয়ার্ড অনুসন্ধানের সাথে উত্তর দিন: ভেক্টর অনুসন্ধানের জন্য হতাশাজনক ফলাফল, যারা কোনোভাবে আমাদের ডক্সে ডেনো পৃষ্ঠাটি মিস করেছে। এটি কিছু অন্যান্য Deno প্রাসঙ্গিক বিষয়বস্তু খুঁজে পেয়েছে, কিন্তু খুব দরকারী উদাহরণ ধারণকারী পৃষ্ঠা নয়. রায়: বিজয়ী: কীওয়ার্ড অনুসন্ধান। স্কোর: 1-1 প্রশ্ন: আমি কীভাবে কাস্টম কলামের ধরন সহ একটি CSV ফাইল আমদানি করতে পারি? ভেক্টর অনুসন্ধান সহ: কীওয়ার্ড অনুসন্ধানের সাথে: উভয়ই সঠিক পৃষ্ঠা খুঁজে পেয়েছে ("একটি CSV ফাইল আমদানি করুন"), কিন্তু কীওয়ার্ড অনুসন্ধান সংস্করণটি আরও সম্পূর্ণ উত্তর পেতে পরিচালিত হয়েছে৷ এটি একটি ফ্লুক নয় তা নিশ্চিত করতে আমি এটি একাধিকবার চালিয়েছি। আমি মনে করি যে টেক্সট খণ্ডটি কীভাবে নির্বাচন করা হয় তার থেকে পার্থক্য আসে (কীওয়ার্ড অনুসন্ধানের ক্ষেত্রে কীওয়ার্ডগুলির প্রতিবেশী, ভেক্টর অনুসন্ধানের ক্ষেত্রে পৃষ্ঠার শুরু থেকে)। রায়: বিজয়ী: কীওয়ার্ড অনুসন্ধান। স্কোর: 1-2 প্রশ্ন: কিভাবে আমি ইমেল কলাম দ্বারা ব্যবহারকারী নামের একটি টেবিল ফিল্টার করতে পারি? ভেক্টর অনুসন্ধান সহ: কীওয়ার্ড অনুসন্ধানের সাথে: ভেক্টর অনুসন্ধান এটিতে আরও ভাল করেছে, কারণ এটি "ফিল্টারিং" পৃষ্ঠা খুঁজে পেয়েছে যেখানে আরও উদাহরণ রয়েছে যা ChatGPT উত্তর রচনা করতে ব্যবহার করতে পারে। কীওয়ার্ড অনুসন্ধান উত্তরটি সূক্ষ্মভাবে ভেঙে গেছে, কারণ এটি পদ্ধতির নামের জন্য "ফিল্টার" এর পরিবর্তে "ক্যোয়ারী" ব্যবহার করে। রায়: বিজয়ী: ভেক্টর অনুসন্ধান। স্কোর: 2-2 প্রশ্নঃ Xata কি? ভেক্টর অনুসন্ধান সহ: কীওয়ার্ড অনুসন্ধানের সাথে: এটি একটি ড্র, কারণ উভয় উত্তরই বেশ ভাল। দুটি উত্তরে সংক্ষিপ্ত করার জন্য আলাদা আলাদা পৃষ্ঠা বেছে নিয়েছিল, কিন্তু উভয়ই একটি ভাল কাজ করেছে এবং আমি একজন বিজয়ী বাছাই করতে পারছি না। রায়: স্কোর: 3-3 কনফিগারেশন এবং টিউনিং এটি কীওয়ার্ড অনুসন্ধানের জন্য ব্যবহৃত একটি নমুনা Xata অনুরোধ: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "What is Xata?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "If you answer with Markdown snippets, prefer the GitHub flavour.", "Your name is DanGPT" ], "searchType": "keyword", "search": { "fuzziness": 1, "target": [ "slug", { "column": "title", "weight": 4 }, "content", "section", { "column": "keywords", "weight": 4 } ], "boosters": [ { "valueBooster": { "column": "section", "value": "guide", "factor": 18 } } ] } } এবং আমরা ভেক্টর অনুসন্ধানের জন্য এটি ব্যবহার করি: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "How do I get a record by id?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "Your name is DanGPT" ], "searchType": "vector", "vectorSearch": { "column": "embeddings", "contentColumn": "content", "filter": { "section": "guide" } } } আপনি দেখতে পাচ্ছেন, কীওয়ার্ড অনুসন্ধান সংস্করণে আরও সেটিংস রয়েছে, অস্পষ্টতা এবং বুস্টার এবং কলাম ওজন কনফিগার করা। ভেক্টর অনুসন্ধান শুধুমাত্র একটি ফিল্টার ব্যবহার করে। আমি এটিকে কীওয়ার্ড অনুসন্ধানের জন্য একটি প্লাস বলব: অনুসন্ধানটি টিউন করার জন্য আপনার কাছে আরও ডায়াল রয়েছে এবং তাই আরও ভাল উত্তর পান৷ কিন্তু এটি আরও কাজ, এবং ভেক্টর অনুসন্ধানের ফলাফল এই টিউনিং ছাড়াই বেশ ভাল। আমাদের ক্ষেত্রে, আমরা ইতিমধ্যেই আমাদের ডক্স সার্চ কার্যকারিতার জন্য কীওয়ার্ড অনুসন্ধান টিউন করেছি। তাই এটি অগত্যা অতিরিক্ত কাজ ছিল না, এবং ChatGPT এর সাথে খেলার সময় আমরা আমাদের ডক্স এবং অনুসন্ধানের উন্নতিও আবিষ্কার করেছি। এছাড়াও, Xata-তে আপনার কীওয়ার্ড সার্চ টিউন করার জন্য একটি খুব সুন্দর UI আছে, তাই কাজটি শুরু করা কঠিন ছিল না (এটি সম্পর্কে একটি পৃথক ব্লগ পোস্টের পরিকল্পনা করা)। এমন কোন কারণ নেই যার জন্য ভেক্টর অনুসন্ধানে বুস্টার এবং কলাম ওজন এবং এর মতো থাকতে পারে না, তবে আমাদের কাছে এটি এখনও Xata-এ নেই এবং আমি অন্য কোনও সমাধান জানি না যা আমরা কীওয়ার্ড তৈরির মতো সহজ করে তোলে অনুসন্ধান টিউনিং এবং, সাধারণভাবে, কীওয়ার্ড অনুসন্ধানের জন্য আরও পূর্বের শিল্প রয়েছে, তবে এটি বেশ সম্ভব যে ভেক্টর অনুসন্ধানটি ধরবে। আপাতত, আমি কীওয়ার্ড সার্চকে বিজয়ী বলতে যাচ্ছি স্কোর: 3-4 সুবিধা আমাদের ডকুমেন্টেশনে ইতিমধ্যেই একটি অনুসন্ধান ফাংশন ছিল, কুকুর-খাবার Xata, যাতে এটি একটি চ্যাট বটে প্রসারিত করা বেশ সহজ ছিল। Xata এখন নেটিভভাবে ভেক্টর অনুসন্ধানকেও সমর্থন করে, তবে এটি ব্যবহার করার জন্য সমস্ত ডকুমেন্টেশন পৃষ্ঠাগুলির জন্য এম্বেডিং যোগ করা এবং একটি ভাল খণ্ডন কৌশল বের করা প্রয়োজন। আমরা টেক্সট এম্বেডিং তৈরির জন্য OpenAI এম্বেডিং এপিআই ব্যবহার করেছি, যার একটি ন্যূনতম খরচ ছিল। বিজয়ী: কীওয়ার্ড অনুসন্ধান স্কোর 3-5 লেটেন্সি কীওয়ার্ড অনুসন্ধান পদ্ধতির জন্য ChatGPT API-এ অতিরিক্ত রাউন্ড-ট্রিপ প্রয়োজন। এটি UI-তে স্ট্রিম করা শুরু হওয়া ফলাফলের বিলম্বের পরিপ্রেক্ষিতে যোগ করে। আমার পরিমাপ দ্বারা, এটি প্রায় 1.8s অতিরিক্ত সময় যোগ করে। ভেক্টর অনুসন্ধান সহ: কীওয়ার্ড অনুসন্ধানের সাথে: এখানে মোট এবং কন্টেন্ট ডাউনলোডের সময় প্রাসঙ্গিক নয়, কারণ সেগুলি বেশিরভাগই নির্ভর করে কতক্ষণ তৈরি করা প্রতিক্রিয়া। তুলনা করতে "সার্ভার প্রতিক্রিয়ার জন্য অপেক্ষা করা হচ্ছে" বারটি দেখুন (সবুজটি)। দ্রষ্টব্য: বিজয়ী: ভেক্টর অনুসন্ধান স্কোর: 4-5 খরচ কীওয়ার্ড অনুসন্ধান সংস্করণটিকে ChatGPT API-তে একটি অতিরিক্ত API কল করতে হবে, অন্যদিকে, ভেক্টর অনুসন্ধান সংস্করণটিকে ডাটাবেসের সমস্ত নথি এবং প্রশ্নের জন্য এমবেডিং তৈরি করতে হবে। যতক্ষণ না আমরা অনেক নথি সম্পর্কে কথা বলছি, আমি এটিকে টাই বলব। স্কোর: 5-6 উপসংহার স্কোর টাইট! আমাদের ক্ষেত্রে আমরা আপাতত কীওয়ার্ড অনুসন্ধান ব্যবহার করে চলেছি, বেশিরভাগ কারণ আমাদের কাছে এটিকে টিউন করার আরও উপায় রয়েছে এবং এর ফলস্বরূপ এটি আমাদের পরীক্ষার প্রশ্নগুলির জন্য কিছুটা ভাল উত্তর তৈরি করে। এছাড়াও, সার্চ করার জন্য আমরা যেকোন উন্নতি করি তা সার্চ এবং চ্যাট ব্যবহার উভয় ক্ষেত্রেই স্বয়ংক্রিয়ভাবে উপকৃত হয়। যেহেতু আমরা আরও টিউনিং বিকল্পগুলির সাথে আমাদের ভেক্টর অনুসন্ধান ক্ষমতাগুলিকে উন্নত করছি, আমরা ভবিষ্যতে ভেক্টর অনুসন্ধান বা হাইব্রিড পদ্ধতিতে স্যুইচ করতে পারি। আপনি যদি আপনার নিজস্ব ডকুমেন্টেশন বা যেকোনো ধরনের জ্ঞানের ভিত্তির জন্য একই ধরনের চ্যাট বট সেট আপ করতে চান, তাহলে আপনি Xata আস্ক এন্ডপয়েন্ট ব্যবহার করে সহজেই উপরেরটি বাস্তবায়ন করতে পারেন। বিনামূল্যে এবং এ আমাদের সাথে যোগ দিন। আমি ব্যক্তিগতভাবে আপনাকে এটি চালু এবং চলমান সাহায্য করতে খুশি হব! একটি অ্যাকাউন্ট তৈরি করুন Discord-