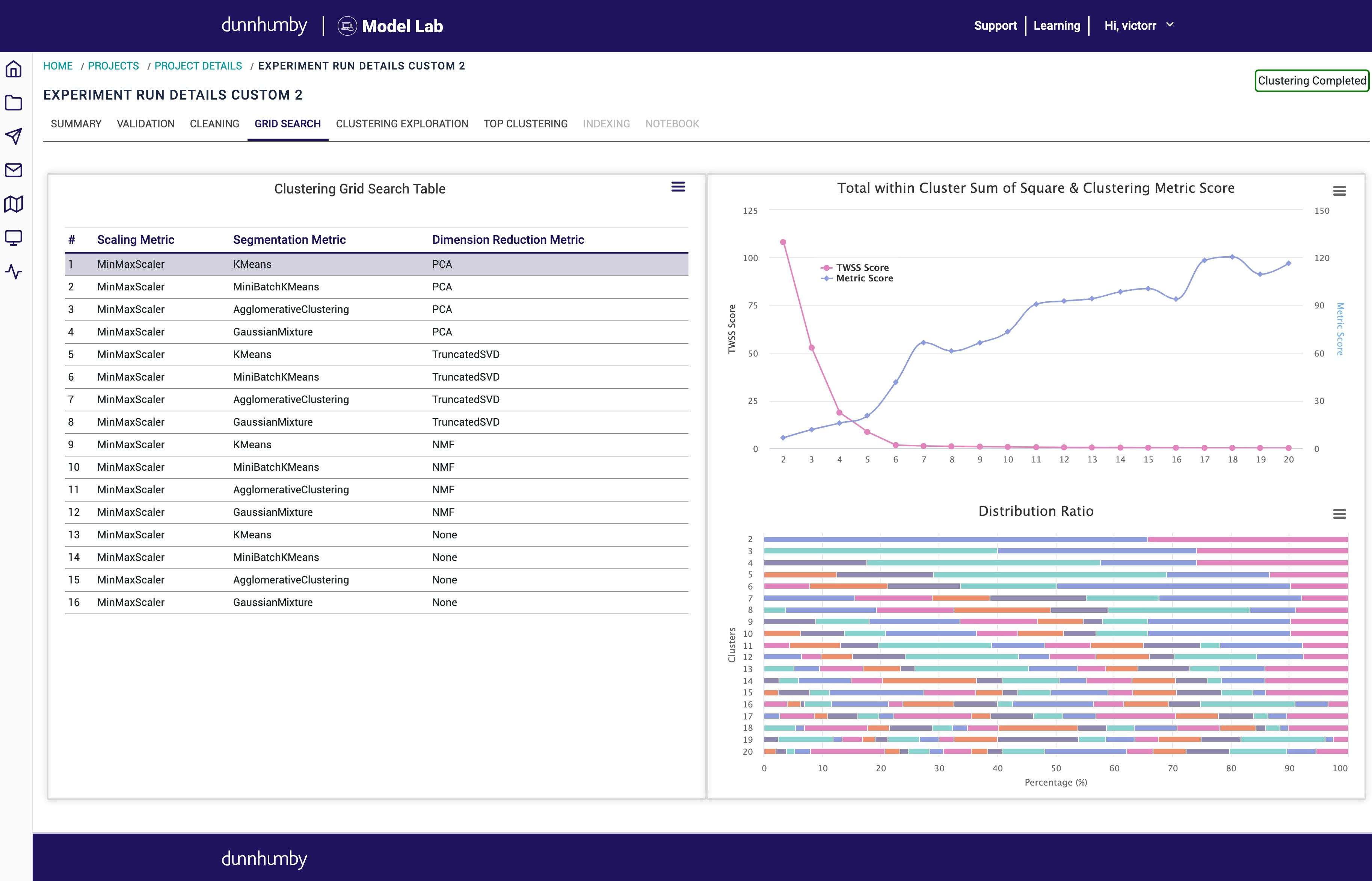
We are very excited to release the free tier of dunnhumby Model Lab this as part of our partnership with Microsoft. dunnhumby Model Lab is an application that provides automated pipelines for deploying machine learning algorithms and has been used to build millions of models on behalf of our clients. Sign up here: https://signup.model-lab.dunnhumby.com/ We make it easy to connect your data, clean your data, and run your machine learning pipeline within minutes. You can then take that output and copy right into a notebook for further refinement if needed. Features Run all your machine learning from a single platform. You can create new projects, reference datasets, and create multiple experiments in just a few clicks! You can also follow the progress of your machine learning experiments as they update in real-time. Automated Tuning of Machine Learning Algorithms Machine learning algorithms have many parameters that need to be calibrated based on the data being used. Some algorithms have over 15 parameters that need to be tuned in order to operate properly, all of them having an impact on each other. It's billions of combinations. If done by hand, this process can take days without any guarantee you will find the one that will give you the best results. To reduce the time-to-value and allow data scientists to focus on the good models, Model Lab provides a built-in module that automatically tunes your machine learning algorithms. Leveraging state-of-the-art Bayesian optimization, Model Lab can tune any machine learning algorithm in a fraction of the time usually required. Parallel Computing & Resource Optimization We leverage Kubernetes to run all the models in parallel. This results in a significant boost in performance and considerable reduction in runtime and, therefore, time-to-value. Each model runs as a container on our cluster, allowing multiple models to be trained simultaneously. Model Lab comes with a resource optimization module that optimizes the amount of RAM allocated to each container, allowing us to train as many models as possible in parallel. See our Medium article on this work ! here Our Experiments Build a classification predictive model in minutes Classification is one of the most common types of predictive models done at dunnhumby and across our clients. It has been used to predict things like retention insurance, customer churn for retailers and even loyalty. Building a classification model has become mainstream nowadays and clients expect results very quickly. However, many steps must be completed before delivering a predictive model, which gets in the way of delivering results quickly when performed manually. Classification is Model Lab's machine learning experiment that automates the end-to-end process of building a simple but strong classification predictive model. Originally designed to deliver preliminary results within minutes to validate the data, project scope and hypothesis, FastLog has also proven many times to be at par with more complex machine learning algorithms in term of performance for production purposes. Build a high-level view of your data Clustering is one of the most common type of analysis done at dunnhumby. It has been used to group stores, products, and customers based on loyalty and lifestyles, with unique behavior, which is different from the respective in other groups. Clustering has become mainstream at dunnhumby hence, clients expect quick results with interpretations. A lot of steps and methods needs to be tried before getting the best result in clustering analysis. Clustering is Model Lab's experiment for clustering. It automates the end-to-end process of building the best clustering model using given data and very few parameters. FastCluster can perform multiple clustering iteration and identify the best results very quickly. Data cleaner - Get your data ready to get to work Cleaner is a utility solution from Model Lab that aims at quickly getting your data ready for the work by cleaning and making it ready. It is a requisite for all our experiments. Most of the time, the raw data is not in a state that can run machine learning algorithms. Things like missing values, characters, duplicated rows, etc... can take up to 60% of data scientists time and is the least engaging*. * https://www.forbes.com/sites/gilpress/2016/03/23/data-preparation-most-time-consuming-least-enjoyable-data-science-task-survey-says/#5fecaa7c6f63 Coming Soon Classification - Multiclass This is an extension of the current Classification experiment to support multi-class problems. Regression This experiment will be able to predict a continuous target. Driver Analysis / Non-linear We will be releasing a new version of our Driver Analysis experiment that leverages non-linear algorithms. Those machine learning algorithms have an advantage over traditional methodologies like univariate analysis, in the sense that they explore both non-linear relationships and interactions in the data. 3D Data Exploration Data visualization techniques have proven to be sometimes very useful to identify pattern in the data, as our brain is very good a finding patterns. This module will leverage PCA and t-SNE techniques, and provide a 3D visualization of the projected data. Time Series Modelling Many problems look at the evolution of certain metrics or target over time. This experiment will allow users to run such analysis and make forecasting over time. This product is the brainchild of and is part of dunnhumby Labs, dunnhumby's new product accelerator. Dr. Victor Robin