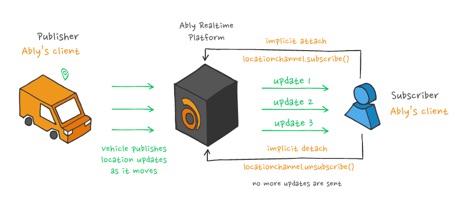
A diff algorithm outputs the set of differences between two inputs. These algorithms are the basis of a number of commonly used developer tools. Yet understanding the inner workings of diff algorithms is rarely necessary to use said tools. Git is one example where a developer can read, commit, pull, and merge diffs without ever understanding the . Having said that there is very limited knowledge on the subject across the developer community. underlying diff algorithm The purpose of this article is not to detail how programmatically implemented a diff algorithm across its distributed , but rather to share our research and provide systematic knowledge on the subject of diff algorithms that could be useful to implementers of diff/delta/patch functionality. Ably pub/sub messaging platform A quick bit of context For Ably customers like Tennis Australia or HubSpot, reduces the bandwidth required to transmit realtime messages by sending only the diff of a message. Message Delta Compression This means subscribers receive only the changes since the last update instead of the entire stream. Sending fewer bits is more bandwidth-efficient and reduces overall costs and latencies for our customers. To develop this feature we needed to implement a diff algorithm that supported binary encoding and didn’t sacrifice latency when generating deltas. Diff algorithms Purpose and usage The output of a diff algorithm is called or . The delta format might be human readable (text) or only machine readable (binary). Human readable format is usually employed for tracking and reconciling changes to human readable text like source code. Binary format is usually space optimized and used in order to save bandwidth. It transfers only the set of changes to an old version of the data already available to a recipient as opposed to transferring all the new data. The formal term for this is . patch delta delta encoding Binary VS Text? There seems to be a common misconception that diff algorithms are specialized based on the type of input. The truth is, , as long as the input can simply be treated as a . That string might consist of the English alphabet or opaque binary data. Any diff algorithm will generate a correct delta given two input strings in the same alphabet. The misconception that a different algorithm is required to handle binary data arises from commonly used diff/merge tools treating text and binary as if they were actually different. These tools generally aim to provide a human-readable delta, and as such focus on human-readable input to the exclusion of binary data. diff algorithms are omnivorous and can handle any input string of bytes The assumption is that binary data is not human-readable so the delta between two binary data inputs will also not be human readable, and thus rendering it human-readable is deemed to be too much effort. Equality is the only relevant output in the case of binary diffs, and as such, a simple bit-by-bit comparison is considered to be the fastest and most appropriate solution. This categorization of algorithms by the efficiency of solution causes a partitioning of inputs into different types. Another aspect that adds to the confusion is the line-based, word-based, and character-based classification of textual diff outputs produced by diff/merge tools. A diff algorithm that is described as “line-based” gives the impression that it produces “text-only” output, and that this means that it accepts only text input and never binary data inputs. However, line/word/character-based is not a characteristic of a diff algorithm itself; rather, it is an optimization applied to the input before feeding it to the actual diff algorithm. Because new lines and spaces have meaning as separators in human-readable text, the diff tool can segment the string based on the hashes of the lines or words in the text. This hash string is much shorter than the original text thus saving time at the cost of reduced granularity of the diff. Additionally, line-based granularity might actually even increase human readability of the diff in some cases. However, if the input is known to be opaque binary data, there are no meaningful separators nor human-readable diff to display, so this optimization cannot be applied. Algorithms of optimizing human-readable data before it becomes an input are thus prone to getting miscast as wholly of processing binary data. capable incapable The truth remains, however: apart from pre-processing optimization, both binary and human-readable data can be treated as strings-of-bytes inputs and easily processed. Three generations of diff algorithms The notion of how a diff should be generated has evolved over time. String-to-string Correction or Insert/Delete The first generation of diff algorithms solved the and emerged in the 60s and 70s. Each of the two inputs is interpreted as a string composed of characters in some alphabet. The output is a sequence of character edits, most commonly insert/delete operations, that could be applied to one of the inputs to transform it to the other input. string-to-string correction problem That makes this class of algorithms particularly suitable for generating human readable diffs on human readable inputs, e.g. different versions of the same text/source code resulting from actual edits being made over time. What helps even further is that in theory, and more often than not in practice, there is more than one minimal length sequence of edit operations that gets the job done. Various heuristics can be used to pick the edit sequences that most closely resembles actual human made edits. The set the foundation for this generation of diff algorithms. The is the latest improvement and the de facto standard for the generation and is currently used in multiple diff tools including the GNU diff utility.This generation of algorithms usually finds either the or the minimal (usually that would be the ) and uses these to generate the sequence of edits needed to transform one input into the other. Wagner-Fischer algorithm Myers Algorithm longest common subsequence edit distance Levenshtein distance Block move or copy/insert Pure block move The next generation of diff algorithms was based on seemingly small optimizations over the previous generation. The character edits were upgraded to block-of-characters edits. That is, instead of expressing the diff as operations on single characters, the diff would be expressed as operations on blocks of characters. The operations are usually copy and insert where blocks of data that appear in both inputs are recorded in the delta as copied from one input to the other. The blocks unique to one of the inputs are recorded as insertions. This approach was first proposed by . Walter Tichy Compression based block move How Ably generates deltas in its pub/sub messaging platform using the block move approach At first glance, the block move approach seems like a minor optimization. However, it has significant impact once you take into account the possibility that some block(s) of characters can repeat in some or both of the inputs. Thinking about diff generation in terms of copying blocks of data and keeping an eye out for the same block repeating more than once opens the door to using compression algorithms to generate a diff and delta file. Compression algorithms do just that: find the biggest possible repeating blocks of data and replace each consecutive occurrence with a reference to the first occurrence. Blocks of data that never repeat are copied straight to the output. Compression algorithms are in essence block move algorithms. If the block move analysis done by a compression algorithm is performed on both inputs of a diff algorithm, it will easily identify the common parts of both inputs. It will also point out which blocks of data are unique, that is different in both of the inputs. Once you have this data, it is straightforward to come up with a sequence of block copy/delete operations that will convert one of the inputs to the other one. The major benefit of using compression algorithms is the greatly reduced size of the delta. A block of data will never appear more than once in the delta. It might be referred to multiple times but the actual data of the block will be contained in the delta only once. That is a major difference from the preceding approaches. It should also be mentioned that the delta size is reduced at the cost of reduced human readability. , , are widely used de-facto standard implementations of diff algorithms of this generation. xDelta zDelta Bentley/McIlroy Latest Upgrades This would be the latest generation of diff algorithms. Most of its members exist only in research papers and don’t have any commercial implementations yet. They are largely based on the block move approach but offer substantial implementation optimizations, which result in claims of double-digit factor improvements in speed over the previous generation. These optimizations are mostly focused on efficiently finding matching blocks of data in the two inputs. Various incremental hashing or compression-like techniques (such as suffix-trees) are used to achieve this purpose. , , could be assigned to this generation of diff algorithms. edelta ddelta bsdiff Delta generation algorithms currently in use This is a short overview of the tools and libraries focused on efficient delta/patch file generation and available at the time of writing (June 2019). Various other existing implementations of general purpose diff algorithms in different languages are omitted here for brevity’s sake. Myers Algorithm - human readable diffs The belongs to the string correction family and is widely used by tools fine tuned to generate human readable delta/patch files out of human readable inputs. This is used by tools such as Git Diff and GNU Diff. Myers Algorithm Original Myers time and space complexity is O(ND) where N is the sum of the lengths of both inputs and D is the size of the minimum edit script that converts one input to the other. When there number of differences is small, as is the case with edits of the same code/text file, the algorithm is fast. Various optimizations can and have been applied to the original Myers algorithm resulting in improvements of up to O(NlgN + D^2) time and O(N) space. Bentley-McIlroy The algorithm belongs to the block move family and is focused on producing delta/patch files of optimal size. It has various implementations on different platforms and languages so it can be considered a somewhat de facto standard for scenarios where delta size matters. Google's is one of the most prominent usages of Bentley-McIlroy that is able to generate a VCDiff format delta/patch. Bentley-McIlroy Open VCDiff The Bentley-McIlroy algorithm has time complexity of O(sqrt(N)*N) although the authors claim linear complexity in the average case. The memory complexity is linear. XDelta belongs to the block move family and is focused on speed of delta generation. The algorithm sacrifices delta size for improved speed. The delta generation tool is the most prominent usage of XDelta and is also able to generate a VCDiff format delta/patch. The XDelta algorithm xdelta The XDelta algorithm has linear time and space complexity. BSDiff The algorithm belongs to the block move family and is focused on achieving minimal delta/patch size. It is also specifically optimized for executable files. The tool is the most prominent usage of the BSDiff algorithm. The bsdiff tool uses its own custom delta/patch file format. BSDiff bsdiff BSDiff time complexity is O((n+m)log(n)) where n and m are the sizes of both inputs. Its memory complexity is max (17n,9n+m)+O(1). Delta file formats Standards are a . And the really good thing about standards is that there are usually many to choose from. As far as delta/patch files are concerned, however, the problem is more the lack of standards rather than abundance. The many diff tools and libraries produce delta/patch files in their own custom formats and consequently only the producer of the patch is able to apply it. good thing That being the case, historically, two major attempts of standardization of the delta/patch format have emerged. Unix .patch This is a family of delta/patch formats produced by the GNU diff tool that is aimed at human readability. The GNU diff tool has been around for a long time, and these patch formats are widely accepted/used with or without modifications by various text processing tools and source control systems. VCDiff is the most prominent attempt at creating a data-agnostic and algorithm-agnostic delta/patch format aimed at compactness and speed of application. VCDiff gained quite the adoption related to Google’s effort. Nowadays several diff algorithm implementations are able to generate delta/patch files in VCDiff format. VCDiff delta application libraries in various states of maturity exist for most of the popular languages and platforms. VCDiff SDCH (Shared Dictionary Compression for HTTP) VCDiff term disambiguation - patch format vs algorithm In the term VCDiff is used to name both a delta/patch file format and a diff algorithm. Moreover, the diff algorithm going by the name VCDiff is proprietary. Numerous research papers also test or refer to the VCDiff algorithm. While a proprietary diff algorithm by that name does actually exist, VCDiff is also the name of an algorithm-agnostic delta/patch file format. Any of the algorithms here could generate delta files in the VCDiff format. RFC3284 Testing open-vcdiff and xdelta We chose the Google open-vcdiff and xDelta algorithms for testing since they are mature, use the more advanced block move approach, produce small size delta/patch files, and are not line-based but are straightforwardly applied to opaque binaries. Even more importantly both of them are able to produce delta/patch files in the relatively universal and open VCDiff format. Adopting an open format means we can fix any bugs and/or implement when necessary. Ably as a company also advocates for so it’s important for us to adopt them in our own stack wherever possible. decoders open standards Last but not least, both of them are open source and can be built as libraries and incorporated in various applications. Indeed there were multiple choices of implementation of the compression algorithms available in a good set of languages for building . decoders Our tests are far from complete or statistically significant. They are simply aimed at giving you a feel for how these algorithms behave in the field. Test setup The tests were done using the latest official implementations of the algorithms found on GitHub at the time of writing this post (June 2019). Both algorithms expose a great number of tweaks and settings like memory window size that greatly affect their performance. A deliberate effort has been made to run both under the same settings but mistakes are possible. Tests used the . xDelta CLI Test results: Average time over 3 minutes execution in a loop The above is where: Delta size comparison Ably’s choice: xDelta In the end we chose xDelta at Ably primarily because there was a good quality implementation of the algorithm in native code with O(n) complexity. That is, in the worst case scenario Ably discards a delta that is bigger than the original message but we don't waste much time generating this delta. This helps us easily handle the trade-off between bandwidth saved by generating deltas and the CPU costs required to generate said deltas. xDelta and VCDIFF in action at Ably This is an American transit source. If you happen to be reading this post at a time when there are no busses running - such as early in the morning in Europe - you won't see any data. Ably JS Bin We sincerely hope this article saves you time and effort researching all this information, and that it provides the required knowledge in a single place for anyone looking to implement diff/delta/patch functionality. About Ably Ably is a realtime messaging platform. We deliver billions of realtime messages everyday to more than 50 million end-users across web, mobile, and IoT platforms. Developers use Ably to build realtime capabilities in their apps with our multi-protocol pub/sub messaging (including message delta compression ), presence , and push notifications , free streaming data sources from across industries like transport and finance, and integrations that extend Ably into third party clouds and systems like AWS Kinesis and RabbitMQ. Both businesses and developers choose to build on Ably because we provide the only realtime platform architected around Four Pillars of Dependability: performance, high availability, reliability, and integrity of data. This allows our customers to focus on their code and data streams while we provide unrivaled quality of service, fault-tolerance, and scalability. We’re hiring for roles across our commercial and engineering teams :). Previously published at https://www.ably.io/blog/practical-guide-to-diff-algorithms/







![featured image - Delta Compression: Diff Algorithms And Delta File Formats [Practical Guide]](https://firebasestorage.googleapis.com/v0/b/hackernoon-app.appspot.com/o/images%2FYPYeQGgK3uVuaAoY97gRJBaXbLU2-cjb3evi.jpeg?alt=media&token=283b0cbd-f48d-4fc1-8566-be435375499b&auto=format&fit=max&w=3840)