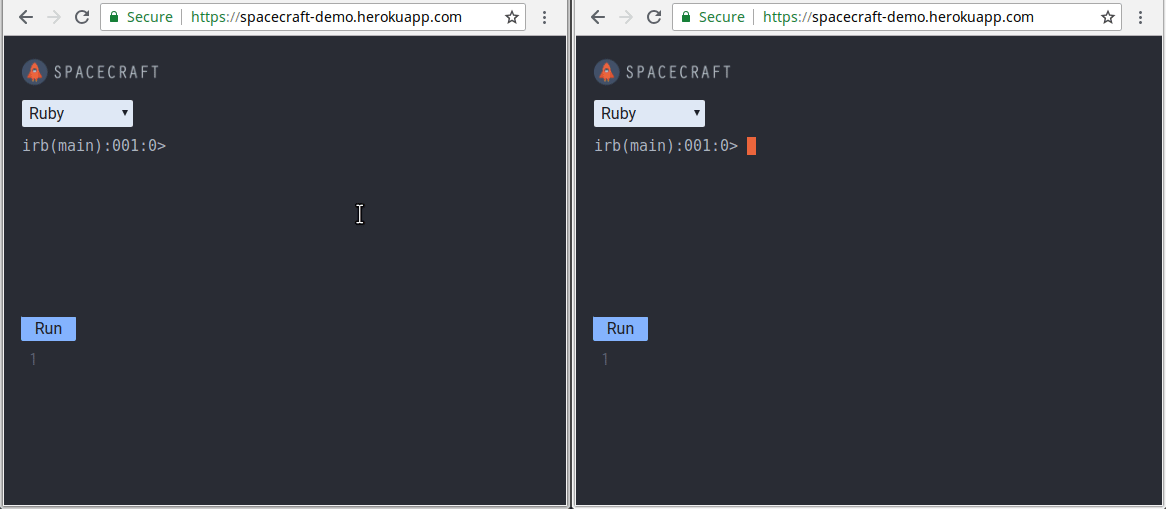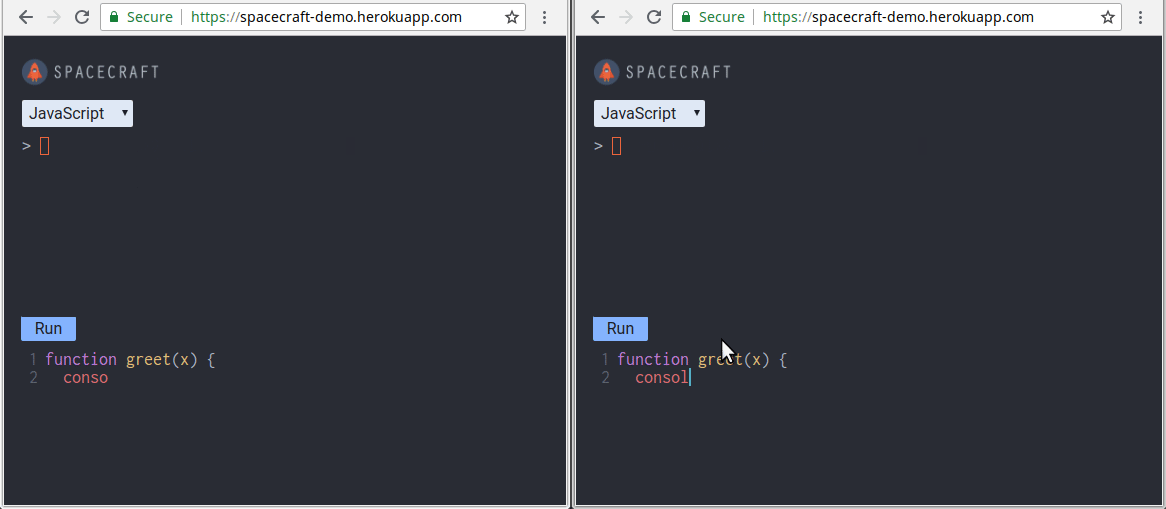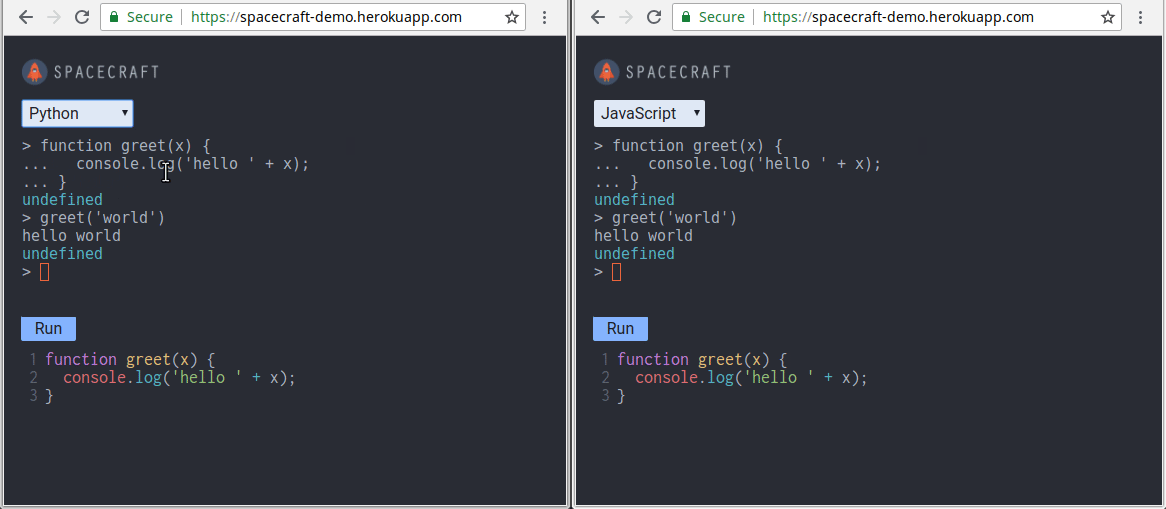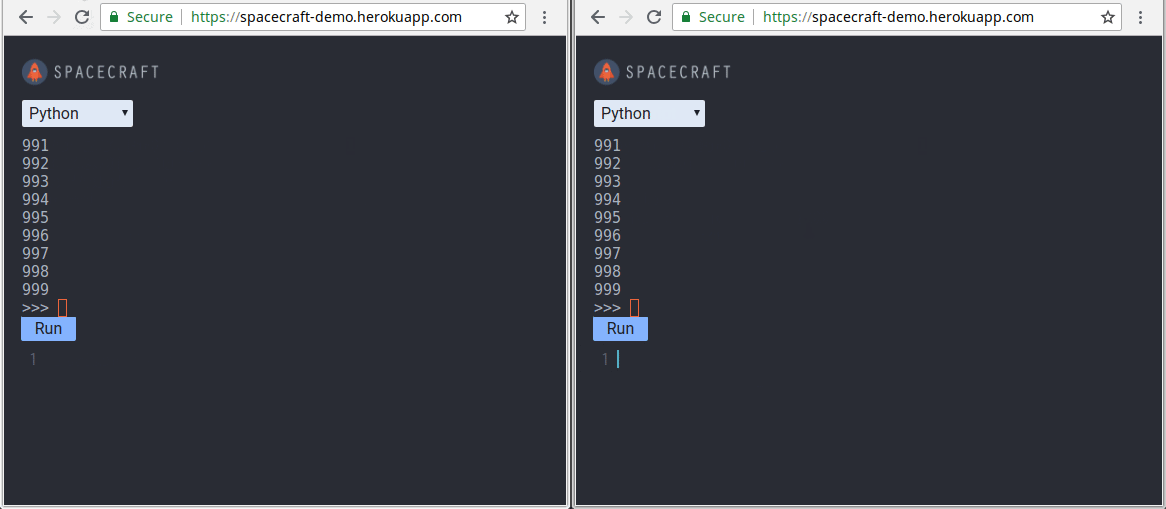
Using Nodejs, Docker, and WebSockets Try out SpaceCraft here Read our in-depth case study here Introduction Today, collaborative programming environments that run in the browser have become more popular than ever. A huge reason for their popularity is that they are effective for remote technical interviews. With these platforms, a candidate’s programming ability can be gauged more accurately than with just a phone interview alone and before planning an onsite interview. Moreover, having such an environment removes any set-up necessary for pair-programming. It caters to the need for remote developers to be able to start pair-programming right away. Currently, the two largest platforms are and . If you haven’t noticed, recently announced the launch of . It enables multiple users to collaborate in the same IDE or terminal interface. Repl.it Coderpad.io Repl.it Multiplayer We built during the same period. SpaceCraft SpaceCraft is an in-browser REPL (Read-Evaluate-Print-Loop) that enables collaboration between users. A is an interactive programming environment. It takes user inputs, evaluates them, and returns the result to the user. Our solution is an open-source alternative built from scratch using Node.js, Docker, and WebSockets. REPL This article details our journey in building SpaceCraft. It highlights the challenges we faced and presents the trade-offs and benefits of each solution we chose. We hope that by the end, you’ll know how to build your own collaborative REPL. You’ll also understand the engineering concepts involved in constructing such a system. You can also read our more . in-depth case study here Meet The Team Before we get started, we’d like you to meet the three software engineers behind SpaceCraft: We built remotely by working together across the United States. Please don’t hesitate to get in touch if you have questions, or are interested in talking about software engineering: SpaceCraft Ying Chyi Gooi — / Website LinkedIn Julius Zerwick — / Website LinkedIn Nick Johnson — LinkedIn Building SpaceCraft as an Open-Source Alternative We have used a collaborative pair-programming platform such as Yet we were curious to see if there are any open-source alternative. We are also hoping to find one that didn’t require sign-up so that users could start coding right away. To our surprise, we found none. By building an open-sourced version, we encourage others to develop and . Coderpad.io. deploy a collaborative REPL of their own Goals Our goal was to provide users with a choice of languages to code in. We present them both a terminal-like REPL and text editor to write and evaluate their code. We also wanted users to invite others to join their session to collaborate. As you might imagine, building such a system brings several interesting engineering challenges: Building a REPL that evaluates code in multiple languages. Synchronizing the displays among all collaborating users in real-time. Preventing any user-entered malicious code from affecting our system. Scaling our application to enable multiple users sessions. Let’s dive into each challenge and explore the ways we tackled them. Building a REPL Building a functioning REPL is the core component of our project. We can separate the REPL component into two parts: The front-end terminal interface The back-end mechanism that interacts with the REPL program Creating the User Interface For the REPL terminal, we leveraged , an in-browser terminal emulator for users to write their code. For the text editor, we utilized to enable syntax highlighting. Xterm.js CodeMirror The user interface of SpaceCraft. Left: REPL terminal. Right: text editor When a user hits in the terminal interface or the button on the text editor, their code is sent to our server for evaluation. Evaluation output will then be sent back and displayed in the terminal. Enter Run By leveraging Xterm.js and CodeMirror, we were able to focus our efforts on developing a rich REPL experience. Our goal is to enable multiple-language evaluation for Ruby, JavaScript, and Python. With the user interface in place, we need to figure out how to handle a user’s input and evaluate it on our back end. Interacting with the REPL program Before we jump straight into how we evaluate user’s code on the back end, we need to understand how user interaction with an interactive REPL console works. For example, the diagram below shows what happens when a user runs an Interactive Ruby Shell (IRB) or a Node shell session. Regular interaction between a user and a REPL program via a terminal The above diagram shows that user inputs and outputs are handled by the terminal. The terminal then writes inputs to the REPL program and reads any evaluation output from it. For SpaceCraft, however, since we decided to perform code evaluation entirely on a remote back end, our application server must be able to perform the above operations without a terminal. A missing component between our application server and the REPL program Additionally, we have to consider the complexity that comes with interacting with REPLs of different languages. We’ll explore a few approaches that could help set up our application to interact with the REPL program. Approach #1: Use the Language’s REPL API Library Node.js, for example, provides the module that enables REPL code evaluation from within the application code. repl However, there is a problem with using such language-specific APIs. For every language supported, we would need to rewrite the logic in that language. Therefore, we need to use something that works while being language-agnostic to handle the various runtimes. Approach #2: Perform Read/Write Directly on the REPL Child Process At their core, REPL programs are simply processes. By spawning REPL processes, it solves the issue of having to deal with language-specific APIs. To do this, we utilized . This enabled us to access the standard input (a writable stream) and the standard output (a readable stream) of a REPL child process. Node.js Streams We can naively expect that writing into the REPL process’ standard input would allow code evaluation to be performed. However, the output may hang due to the blocking of input and output streams. Streams may be blocked when trying to perform read/write operations on the REPL process One possible reason for this blocking is that a lower-level implementation of the function would hang until new data is being written to the corresponding input stream: read() If some process has the pipe open for writing and O_NONBLOCK is clear, shall block the calling thread until some data is written or the pipe is closed by all processes that had the pipe open for writing. — _read()_ read(3) Linux man page Although there are to unblock the processes for reading and writing, they are not universal for all languages. Thus, this approach does not provide good extensibility in code evaluation for multiple languages. techniques Approach #3: Pseudoterminals To address these limitations, we decided to use a a terminal device that connects to a child process. pseudoterminal — REPL programs are inherently terminal-oriented programs, which means that they expect to connect and work with a terminal. The question now becomes: How can we enable a user to interact with a terminal-oriented program on a remote host? In order to handle a remote user’s input and output, we need to address the connection to a terminal-oriented program. A terminal-oriented program expects a terminal to process its inputs and outputs. Such an operation bypasses the default block buffering performed by the standard input/output functions. Furthermore, this allows the generation of terminal-related signals (such as SIGINT) for the program. A pseudoterminal provides the missing link for creating a connection to our REPL program. A pseudoterminal provides this essential communication channel so that our application and the underlying REPL program are able to speak to each other. Additionally, we gain the benefits of: Enabling input of control sequences (such as Ctrl-C) to the REPL, effectively sending an interrupt signal to the runtime Capturing full outputs (including colors) from the REPL program Standardizing the way our application interacts with REPLs of different languages, thereby increasing extensibility for adding more languages in the future The trade-off of using a pseudoterminal is that it adds a layer of processing between our application and the underlying REPL program. Nonetheless, we chose this approach as it solves our issue and gives us several important benefits. Before we move on, let’s take a moment to realize how far we have gotten. In this part of the journey, the SpaceCraft team has constructed a REPL that works in single-user mode! It also supports code evaluation for languages such as Ruby, JavaScript, and Python. Synchronizing Collaborating Users in Real-time Supporting real-time collaboration between users is another core of our project. Before we go into state synchronization, we’ll need to consider our network architecture and network protocol. Let’s touch upon these next. Network Architecture We chose a client-server architecture in which users connect to a central server, as opposed to a peer-to-peer architecture where clients communicate directly with one another. Our reasoning for this is that: A centralized server provides a single source of authority — conflicts that arise from simultaneous updates can be easily resolved More readily scalable as all language runtimes can be managed and run in a single location Easier to isolate and contain our application to prevent malicious code from affecting the host system WebSockets for Network Protocol We initially started with using HTTP to have clients communicate with our server, but quickly discovered some issues: There is a significant overhead ( of header payload) for each request/response ~200 bytes This overhead adds up as a client sends a request for each keypress There is no easy way to automatically detect a client disconnection. As a solution, we used to address these problems mentioned above. The major feature of WebSockets is that it provides bidirectional communication between the client and server over a single TCP connection. After an initial HTTP handshake to establish the TCP connection, our clients and server will gain the benefits of: WebSockets A lower additional overhead of ~10 bytes per message The ability for our server to stream data at any time to the clients Easily detecting when a user disconnects from our application — we can teardown an application instance when no users are connected to it Allowing us to maintain 1024 or more connections per server as opposed to ~6 connections with HTTP A full duplex persistent connection is possible with WebSockets. The connection stays open until either the client or server disconnects. Reference: WebSockets — A Conceptual Deep-Dive As for actually incorporating WebSockets in SpaceCraft, we used the popular library . Socket.io Syncing Input So now that we have our network architecture assembled, we need to figure out how to sync the current line of command between collaborating users in the same session. We chose to track the current line of input on the client-side so that local edits can be updated and displayed immediately. Our syncing mechanism consists of the following steps: The state of the command line before any changes. The user presses a key that gets displayed in the front-end REPL terminal. The state is updated in the user’s client. The user’s client sends a message with the current input line and terminal prompt to inform the application server that the current line has been changed. Our application server broadcasts a message that includes the current line to other clients. When other clients receive the message, their local states are updated to include the current line of input. The client updates its UI by first clearing the last line of the terminal. Since the prompt is also erased, it has to rewrite the prompt before writing the current input line. In the case of conflicts that arise from concurrent updates between clients, we need to handle them so that all clients will arrive at the same state. As with any collaborative environment, conflicts may arise from concurrent updates. We need to handle those conflicts so that each user arrives at the same state. SpaceCraft relies on to resolve conflicts. For our text editor, we utilized . is a shared editing framework that uses Conflict-Free Replicated Data Type (CRDT) to resolve conflicts. eventual consistency Yjs Yjs Syncing Output States Next, we need to handle syncing the outputs for collaborating users in the same session. To synchronize outputs, our application server broadcasts the evaluation outputs to currently connected clients. The flow of output synchronization is as follows: Client requests a line of code to be evaluated. Our application server receives the current line of code. Our application server sends the line of code to the pseudoterminal that is connected to the REPL program. The REPL program evaluates the line of code and sends the appropriate output data to the pseudoterminal. Application server reads the evaluation outputs from the pseudoterminal. Application server broadcasts and streams the outputs to all connected clients. Clients receive the outputs and display them on the front-end terminal. At this point, we have a REPL that not only is able to evaluate code, but also provides multiple users the ability to collaborate in real-time! Preventing Malicious Code Entered by Users Now, we need to consider the challenge of preventing any potentially malicious code entered by a user from affecting our system and other users. This challenge exists because we are connecting users with a pseudoterminal that facilitates the execution of user input on our server. This leaves ourselves and our users open to the risk of any malicious code submitted directly into our backend. We will need to think of a way to protect both ourselves and our users. One way of overcoming this risk is to run a check on all user inputs against a list of possibly malicious commands, such as . However, this is too exhaustive to make sure that we don’t miss every possibility and is compounded by any language-specific inputs for our supported languages. rm -rf / Isolation via Containers We chose to use to isolate each user’s session and thereby isolate their code. This helps us contain any malicious code away from our host system and other users. containers Through containers, we are able to provide an isolated and complete copy of our application for each user. We can effectively separate users from each other, easily add layers of security to contain malicious code, and ensure that one container only uses a set amount of resources. Let’s start with how we segmented users by containers. We used Docker to create our containers which hold an entire copy of our application code. With this, our session initialization workflow is as follows: A new user makes a request to our application. When our server receives the request, a new container is created based on an image that contains our application, required dependencies, and operating system. The server then redirects the user’s request to the container. The user then establishes an active connection with the container which serves as their session and they can begin coding away with our REPL. With this design, each user is given their own isolated environment to write and evaluate their code. If any user attempts to submit malicious code to destroy our application, they will only be affecting their copy of our application code within the container and our host system is unaffected. However, this is only a start. A container is not a complete solution as there ways to break out of them. We needed to add more security measures to address these vulnerabilities. Securing Containers The main issue of with Docker containers is that users are given root access by default. This allows users to have complete access to the files within the container and the ability to do some truly malicious activity. The first step to securing our container is to remove the default root-level access and prevent users from being able to execute harmful commands such as in our application. To achieve this, we created a user with restricted permissions that will run as the default profile for any user in our container. rm -rf / There’s another security issue. Containers have access to system resources in the same way as non-containerized applications. This allows them to make privileged system calls directly to the host kernel. What this means is that container escape is still possible with a successful privilege escalation attack. An example would be the (copy-on-write) vulnerability that gives attackers write access to a read-only file, giving them access to root. Dirty Cow Containerization alone provides weak isolation. Source: gVisor Github To address this issue, we used a container runtime sandbox to provide a stronger level of isolation. A runtime sandbox achieves this by intercepting application system calls. On top of that, it also employs rule-based execution to limit the application’s access to resources. With this, any attempted privilege system calls will be intercepted, before it has a chance to reach our host system. We chose to leverage , an open-sourced container runtime sandbox developed by Google because it provides the security benefits mentioned above and integrates well with Docker. gVisor The trade-off of using a container runtime sandbox is that it significantly increases our memory consumption. This reduces the maximum number of application instances that can be run per host. Nevertheless, we are willing to sacrifice resource availability in favor of a stronger security model. Scaling Our Application To Enable Multiple User Sessions At this point, we had successfully built our collaborative REPL and isolated complete instances of our application into containers. Now, we needed to evaluate how we could connect clients to their associated container on a remote host, as well as allowing a user to invite others to collaborate in their session. Naive Approach: Port Forwarding Each container has a unique IP address and port number associated with it, and the question becomes how we can route a user’s request for a session to a container and form a connection. We first considered using port forwarding, which takes the initial HTTP request from the client and forwards it to the IP address and port number of a ready-to-use container. Mapping multiple open ports to container destinations This technique is simple since it’s a direct mapping of a client to a container destination. However, this poses some security risk. By running a port scanner to probe for open ports, a user could potentially access any session. This would lead to a complete lack of privacy for our users who wish to collaborate only with the people they invite to join their session. We needed a better approach that could protect our users’ privacy and mask the connections to our containers. Thankfully, this was achieved with a reverse proxy. Using A Reverse Proxy The idea behind a reverse proxy is that there is some middleware that sits between our clients and our server which acts as an intermediary between the two. When a client sends an HTTP request to our server, the reverse proxy receives that request and communicates with our server for the necessary information. The server will respond to the reverse proxy with the container’s IP address and port number, which will then take that information and forward the client’s request to that container for connection. Thus, our reverse proxy will handle all the traffic between our clients and server. While this may sound like a roundabout way of handling a request and response, the benefit is that we can abstract away the connection of addresses and ports to ensure the privacy of our sessions. From the client’s perspective, they are connected to the appropriate container without knowing the association of their URL to a particular container. Furthermore, our proxy server can assign random URLs to created sessions, thereby preventing other unwanted users from gaining access to a current session through port sniffing or guessing pre-determined URLs. Mapping multiple randomly generated URLs to container destinations ensures the privacy of sessions. Along with solving our privacy concerns, a reverse proxy provides our application with greater scalability as our user base grows. It can serve as a load balancer as we add more servers and it can provide content caching to reduce latency for particular content outside of establishing the client-container connection. Session Management Now, in order to connect different groups of users to different sessions, our reverse proxy server must also be responsible to: initialize a session and start a new container forward requests to the appropriate container destroy a session and its associated container Since implementing the above features requires flexibility and customization, we chose to build our reverse proxy from scratch using Node.js, with only the following essential libraries to help us get started: to forward both HTTP and WebSocket requests node-http-proxy , a Node.js Docker API to work with containers Dockerode To find out more about how we implement session management features, read . this section in our case study See It in Action Having all of the features above implemented, here’s the final result of our project: We run two instances of our application by making requests to our reverse proxy server. The top section displays container metrics. You can . try out SpaceCraft here Conclusion We hope you enjoyed reading about our journey as much as we enjoyed the journey itself! SpaceCraft has been an incredible experience for us and we are continually working on it. If you’re interested in any of the topics we discussed here and would like to learn more, check out our where we go into a lot more depth and breadth on how SpaceCraft was built. There is also a list of references that we used that you can check out. case study Finally, if you are interested in contributing to SpaceCraft or want to read our code, you can check out the . GitHub Repo Currently, we are all open for full-time opportunities. If you think one of us would be a good fit for your team, please reach out! Ying Chyi Gooi (NYC) — / Website LinkedIn Julius Zerwick (NYC) — / Website LinkedIn Nick Johnson (SF) — LinkedIn