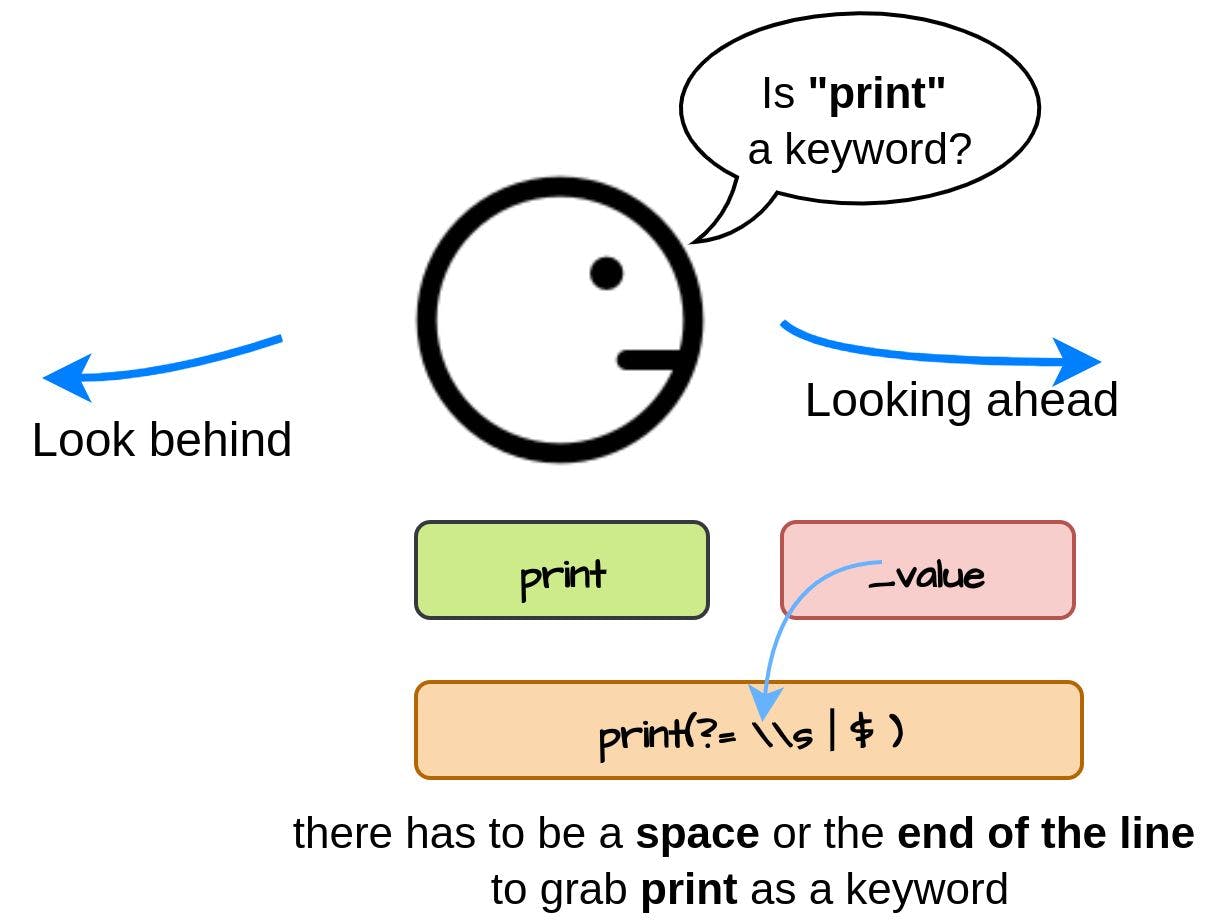
In this part of creating your own programming language, we will improve our lexical analysis with Regex lookaheads and lookbehinds (please check out and ). Part I Part II Basically, lookaheads and lookbehinds allow you to create your own and sub-expressions (anchors). With their help, you can set up a condition that will be met at the beginning and at the end of the line or won’t, and this condition will not be a part of the “matched” expression. ^ $ Lookbehind can “look” back and should be placed at the beginning of the regular expression. Lookahead “looks” forward and accordingly should be placed at the end. There are four types of lookaheads and lookbehinds with corresponding regex syntax: Positive lookahead: (?=pattern) Negative lookahead (?!pattern) Positive lookbehind (?<=pattern) Negative lookbehind (?<!pattern) Let’s dive into code and see how we can improve lexical analysis for our programming language. We will go through the declared with the corresponding regex value to define an appropriate lexeme: Token types Keyword lexeme if|then|end|print|input|struct|arg Let’s suppose we defined a variable starting with a Keyword: print_value = 5 print print_value During the lexical analysis we will capture this variable by the lexeme instead of being parsed as a variable. To read it properly, we need to be sure that after the keyword is placed either a space or the end of the line. It could be done with the help of a positive lookahead in the end of the expression: print_value Keyword Keyword (if|then|end|print|input|struct|arg)(?=\\s|$) Logical lexeme true|false The same rule is applied to the lexeme: Logical true_value = true To read the lexeme properly, it should be separated either by space or by the end of the line: Logical (true|false)(?=\\s|$) Numeric lexeme [0-9]+ For the values, we will introduce the ability to read floating-point numbers with a decimal point and numbers with a negative/positive sign in front of the number: Numeric negative_value = -123 float_value = 123.456 leading_dot_float_value = .123 ending_dot_float_value = 123. First, to match optional or we add a character class: + - [+-]?[0-9]+ Then to read a float number, we introduce a dot character with arbitrary numbers set after it: [+-]?[0-9]+[.]?[0-9]* There could be a special case when our number starts with a leading dot, so we add an extra alternation: [+-]?([0-9]+[.]?[0-9]*|[.][0-9]+) We can also replace an alternation by applying a positive lookahead with a requirement to contain maximum 1 dot and at least 1 number after an arbitrary sign declaration. In this case, our main expression for the float number will have a greedy quantifier: * [+-]?((?=[.]?[0-9])[0-9]*[.]?[0-9]*) Lastly, to map floating-point numbers, we modify to accept type as a generic type: NumericValue Double Value public class NumericValue extends Value<Double> { public NumericValue(Double value) { super(value); } @Override public String toString() { if ((getValue() % 1) == 0) //print integer without fractions return String.valueOf(getValue().intValue()); return super.toString(); } } Operator ([+]|[-]|[*]|[/]|[>]|[<]|[=]{1,2}|[!]|[:]{2}|[(]|[)]|new) struct Object arg number end new_value = new Object [ 5 ] For the operator, we as well need to introduce a positive lookahead separating value with a space or with the end of the line: new ([+]|[-]|[*]|[/]|[>]|[<]|[=]{1,2}|[!]|[:]{2}|[(]|[)]|new(?=\s|$)) In this part we slightly improved our lexical analyzer with positive lookaheads. Now our toy language is a little bit smarter and able to parse more complex variable expressions.