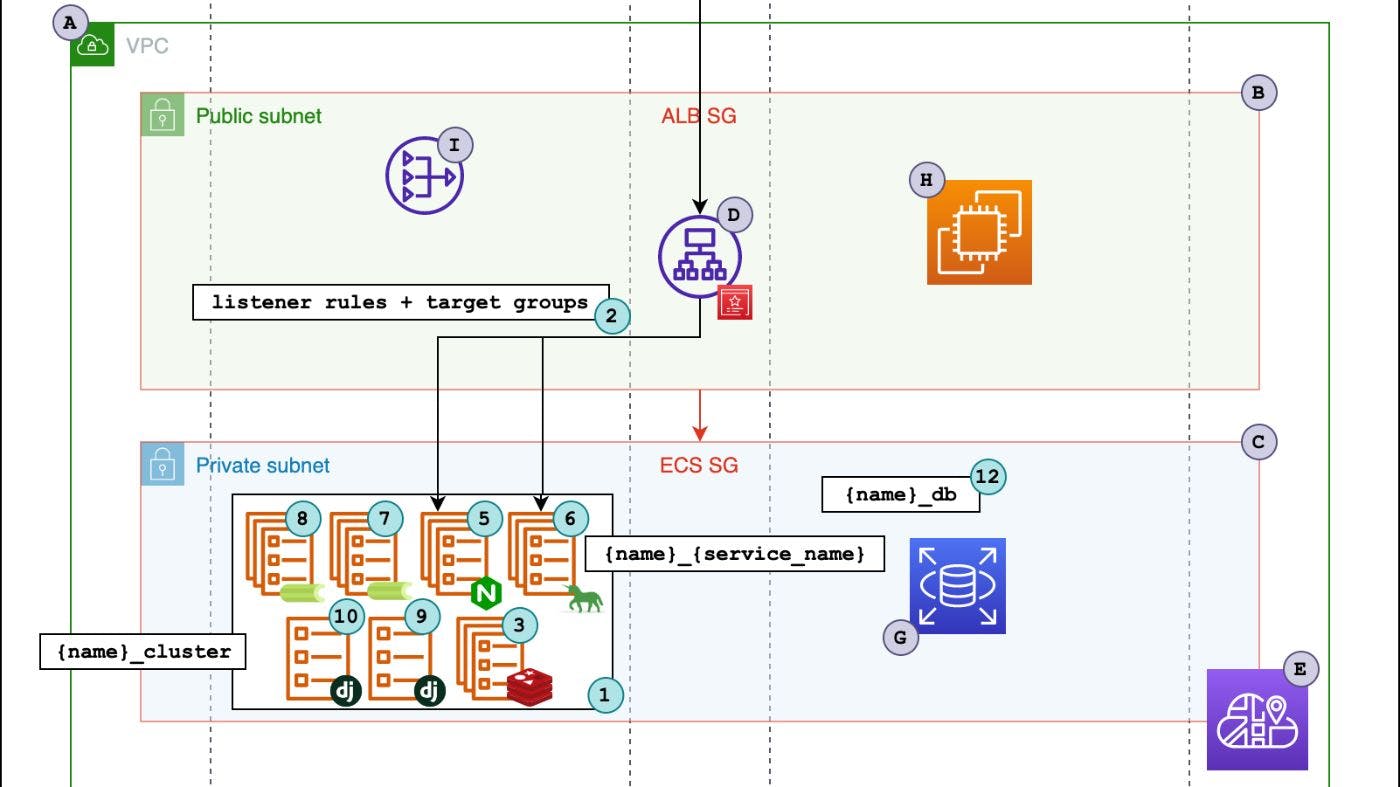
tl;dr This article will show how software development teams can build on-demand instances of a web application project for dog-food testing, quality review, internal and external demos and other use cases that require short-lived but feature-complete environments. It will focus on the technical implementation of building ad hoc environments using a specific set of tools (including AWS ECS, Terraform and GitHub Actions). I will also be giving context on high-level implementation decisions based on what I think are best practices guided by the . If any of this interests you, please have a read and let me know what you think in the comments on the outlets where I'll be sharing this article (links at the end). 12-Factor Application methodology GitHub Links This article references three open-source code repositories on GitHub. django-step-by-step this repo contains an example microblogging application called μblog built with Django the same application is implemented as a traditional Model Template View (MTV) site, a decoupled REST API and Javascript web application and a GraphQL API it is a monorepo that also includes a frontend Vue.js application, CI/CD pipelines, a VuePress documentation site as well as tooling and instructions for settings up a local development environments (both with and without docker) it includes a complete set of GitHub Action examples for automating the processes of creating, updating and destroying ad hoc environments that will be an important part of what is covered in this article terraform-aws-django a collection of modules for running Django applications on AWS using Terraform one of the submodules can be used for creating ad hoc environments which will be what we use to create ad hoc environments this module has been published to Terraform Registry and is used in the directory of the repo terraform/live/ad-hoc django-step-by-step terraform-aws-ad-hoc-environments a Terraform module that provides shared infrastructure used by ad hoc environments (including VPC, RDS instance, bastion host, security groups and IAM roles, etc.) this module has also been published to Terraform Registry and is also used in django-step-by-step this module is designed to be used with the Terraform module terraform-aws-django Assumptions There are all sorts of applications, and all sort of engineering teams. For some context on what I'm describing in this article, here are some basic assumptions that I'm making about the type of engineering team and software application product that would be a good fit for this type of development workflow. engineering team is composed of a backend team, a frontend team, a devops team and works closely with a product team backend team primarily develops a REST API frontend team develops a JavaScript SPA (frontend website) SPA consumes backend REST API product team frequently needs to demo applications to prospective clients development teams don't have deep expertise in infrastructure, containers, CI/CD or automation devops team has been tasked with building automation that will allow anyone on the team to quickly spin up a complete environment for testing and demoing purposes within minutes Here are assumptions about specific tools and technologies used at the company: backend is a REST API developed with Django and a Postgres database backend is packaged into a docker container frontend is also packaged into a docker container using multi-stage builds and NGINX frontend does not require any build-time configuration (all configuration needed by frontend is fetched from backend) backend application's configuration is driven by plain-text environment variables at run-time engineering team uses AWS automation pipeline exists for building, tagging and pushing backend and frontend container images to an ECR repository devops team uses AWS ECS for running containerized workloads devops team uses Terraform for provisioning infrastructure devops team uses GitHub Actions for building automation pipelines team is somewhat cost-conscious What are ad hoc environments? Ad hoc environments are short-lived environments that are designed to be used for testing a specific set of features or for demoing a specific application configuration in an isolated environment. It is intended to be a functional duplicate of the main production environment. An ad hoc environment is the first cloud environment that the application code will be deployed to after a developer has been working on it in a local development environment. Trade-offs to make when designing ad hoc environment infrastructure and automation Now that we have a sense of what we are building and the team we are working with, let's think about the high-level trade-offs that we will face as we build a solution for providing on-demand ad hoc environments. When building infrastructure and workflows for ad hoc environments, there are a few things to solve for: simplicity of the end-user interface and process for requesting an ad hoc environment startup speed total cost of ownership degree of similarity to production environments shared vs isolated resources automation complexity Let's look at these items by considering how we can set up the main infrastructure components that will be used to run our ad hoc application environments. Relational Databases Startup speed can be measured by the time between when an environment is requested and when that environment can be used by whoever requested it. In this period of time, an automation pipeline may do some of the following: run , and to build infrastructure terraform init terraform plan terraform apply run scripts to prepare the application such as database migrations seeding initial sample data with a script or database dump message the user with information about the environment (URLs, commands for accessing an interactive shell, etc.) RDS instances can take a long time to create relative to other AWS resources such as S3 buckets and IAM roles. RDS instances are also more costly than other resources. We could use a single, shared RDS instance placed in a private subnet of a shared VPC. Each ad hoc environment could use a different named database in the RDS instance in the form . Using one RDS instance per ad hoc environment would be slow to startup and tear down and also costly if there are many developers using ad hoc environments simultaneously. {ad-hoc-env-name}-db If we choose to isolate the application's relational database at the database level (and not the RDS instance level), then we will need our automation workflow to create a database per ad hoc environment. Let's spin up a simple example to illustrate how this would would work. A developer is working on that involves a significant refactor of the data model. feature-abc The developer decides to spin up an ad hoc environment called . feature-abc Our automation will need to create a database in the RDS instance called . feature-abc We can configure a bastion host with installed that has network and security group access to our RDS instance, and we can give our GitHub Actions an SSH key that can be used to run over SSH. psql createdb The automation also runs database migrations once the application has started, and we can view the logs of the database migration to check for any irregularities or other issues. This will give the developer and the rest of team confidence that the promoting to the next pre-production environments will not have any errors. feature-abc The developer may even choose to load a SQL dump of the next pre-production environment into their database get even more confidence that there will be no data integrity errors. feature-abc When the developer's PR is merged and approved, the ad hoc environment can be destroyed, including the database in the shared RDS instance. feature-abc feature-abc With this approach we won't incur the costs of multiple RDS instances. Ad hoc environments will start up faster because an RDS instance per environment is not required. We do have slightly less resource isolation, and we need to introduce a bastion host, but I consider this an acceptable trade-off. Redis (key-value database) Redis is another database used in the application and it plays a few different roles: primarily, it is a caching layer that can cache request responses to reduce load on the database and speed up our application it is a message broker for our async task workers (celery) it can be used as a backend for other 3rd party Django apps that our main application may need to use (such as django-constance, cache-ops, django-channels, etc.) AWS offers a managed Redis service called ElastiCache. Redis running on an ElastiCache instance can do database isolation similar to how Postgres running on RDS can do database isolation as we discussed previously, but there are some key differences: redis databases are numbered, not named the backend application uses isolated numbered databases for the different 3rd party apps that I just mentioned (for example: celery can use database , API caching layer can use database , etc.) 0 1 This makes it difficult to use a single ElastiCache instance for our ad hoc environments since we would need to figure out which numbered database to assign to a specific role for each ad hoc environment (e.g. how do we know which numbered database to use for the API caching for the ad hoc environment). feature-abc So how can we approach providing isolated redis instances for multiple ad hoc environments? Spoiler: my solution is to run redis as a stateful service in ECS. Before we dig into how to do this, we need to talk about another important part of our application: compute. Compute Our backend application is composed of a few different services that all share the same code base. In other words, our backend's services uses the same docker image but run different processes for each component: gunicorn for the core API celery for the task workers celerybeat for task scheduling If our application used websockets, we could have another service that runs an asgi server process (like daphne or uvicorn). Since our backend application is packaged into a container and we are using AWS as our cloud provider, ECS is a great choice for running our backend services. ECS is a container orchestration tool that I usually describe as a nice middle ground between docker swarm and Kubernetes. Simply put, it is a flexible option for running our containerized services that make up our backend application. With ECS you can choose to run containers directly on EC2 instances that you manage, or you can run containers using Fargate. Fargate is a serverless compute option that takes care of managing both the underlying "computer" and operating system that run our application's containers. All of our backend dependencies are defined in our Dockerfile, so we do not to maintain or update the underlying operating system that runs our containers -- AWS handles all of this for us. To use Fargate, we simply tell AWS which containers to run and how much CPU and memory to use in the ECS Task that runs the containers. To scale our app horizontally, the ECS service that managed ECS tasks simply increases the number of tasks that run. Since we are going to use the Fargate launch type for our ECS Tasks, let's talk about the ergonomics of these serverless compute instances compared to running our services directly on an EC2 instances. We can't SSH into Fargate compute instances. We can instead use AWS Systems Manager and EcsExec to open an interactive shell in a running backend container. This can be useful for developers who might need to run a management command or access an interactive Django shell to verify behavior in their ad hoc environment. We can't simply change code on the server and restart services. This can sometimes be a useful pattern for debugging something that can only be tested on a cloud environment (e.g. something that can't easily be reproduced on your local machine), so this requires that developers push new images to their backend services for every change they want to see reflected on their ad hoc environment. Later on I'll discuss how we can provide tooling for developers to quickly update the image used in their backend services. With AWS Fargate, you will pay more than you would for a comparable amount of CPU and memory on EC2 instances. Similar to EC2 spot instances, Fargate offers interruptable instances called Fargate Spot which costs significantly less than regular Fargate instances. Fargate spot is appropriate for our ad hoc environments since ad hoc environments are non-critical workloads. In the event that a Fargate spot instance is interrupted, the ECS service will automatically launch another Fargate task to replace the task that was stopped. In my opinion, ECS with Fargate is ideal for running the stateless services that make up our backend application. In terms of parity with our production environment, we can keep almost everything the same, except use regular Fargate instances instead of Fargate spot instances. Redis, revisited We can run redis as an ECS service instead of using ElastiCache. In order to do this, we will need our backend services (gunicorn, celery and celerybeat) to be able to communicate with a fourth ECS service that will be running redis (using an official redis image from Docker Hub, or a redis image that we define in ECR). By default, . If you have used docker-compose, you may know that you can use the service name in a backend service to easily communicate with a redis service called . This networking convenience is not available to use out of the box with ECS. To achieve this in AWS, we need some way to manage a unique ad hoc environment-specific Route 53 DNS record that points to the private IP of the Fargate task that is running redis in an ECS cluster for a given ad hoc environment. Such a service exists in AWS and it is called Cloud Map. Cloud Map offers service discovery so that our backend services can make network calls to a static DNS address that will reliably point to the correct private IP of the ECS task running the redis container. there is no way for our backend services to know how to communicate with any other service in our ECS cluster redis redis We can define a service discovery namespace (which will essentially be a top level domain, or TLD) that all of our ad hoc environments can share. Let's assume this namespace is called . Each ad hoc environment can then define a service discovery service in the shared namespace for redis that is called . This way, we can have a reliable address that we can configure as an environment for our backend that will look like this: . will be the hostname of the redis service, and Route 53 will create records that point to to the private IP of the redis Fargate task for each ad hoc environment. ad-hoc {ad-hoc-env-name}-redis redis://{ad-hoc-env-name}-redis.ad-hoc:6379/0 {ad-hoc-env-name-redis}.ad-hoc {ad-hoc-env-name}-redis.ad-hoc Load Balancing We now have our backend services (gunicorn, celery and celerybeat) running on Fargate spot instances, and these services can communicate with the redis service in our ad hoc environment's ECS cluster using service discovery that we configured with Cloud Map. We still need to think about a few things: how will we expose our API service to the public (or private) internet how will we expose our frontend application to the public (or private) internet how will we make sure that requests go the correct ECS services Application load balancers (ALBs) are a great way to expose web app traffic to the internet. We could either have one application load balancer per ad hoc environment, or one application load balancer shared between all ad hoc environments. ALBs are somewhat slow to create and they also incur a significant monthly cost. They are also highly scalable, so using a shared ALB for all ad hoc environments would work. Individual ad hoc environments can then create target groups and listener rules for a shared ALB for each service that needs to serve requests from the internet (the backend and the frontend). In our case this is the backend API server and the frontend server that serves our static frontend site using NGINX. ECS services that need to be exposed to the internet can specify the target group, port and container to use for load balancing. A target group is created that defines the health check and other settings, and a load balancer listener rule is created on the shared load balancer that will forward traffic matching certain conditions to the target group for our service. For a given ad hoc environment, we need to specify that only traffic with certain paths should be sent to the backend service, and all other traffic should be sent to the frontend service. For example, we may only want to send traffic that starts with the path or to the backend target group, and all other traffic should be sent to the frontend target group. We can do this by setting conditions on the listener rules that forward traffic do the frontend and backend target groups based on the hostname and path. /api /admin We want our listener rule logic to forward , and any other backend traffic to the backend target group, and forward all other traffic ( ) to the frontend target group. In order to do this, we need the backend listener rule to have a higher priority than the frontend listener rule for each ad hoc environment. Since we are using the same load balancer for all ad hoc environments, the priority values for each listener rule need to be unique. If we don't set the priority explicitly, then the priority will be set automatically to the next available value in ascending order. In order to make sure that the backend listener rule has a higher priority than the frontend listener rule for each ad hoc environment, we need to tell Terraform that the frontend module the backend module. This way the backend listener rule will have a higher priority (e.g. priority of 1) because it will be created first, and the frontend listener rule will have a lower priority (e.g. priority of 2). /api /admin /* depends_on More on shared resources vs per-environment resources Up until now we have discussed infrastructure design decisions at a high level, but we have not yet talked about how to organize our infrastructure as code. At a basic level, components of our ad hoc environment either fall into shared infrastructure or infrastructure that is specific to an individual ad hoc environment. Here's a list of the resources that are shared and the resources that are specific to each ad hoc environment. Shared resources include: VPC IAM policies Security groups RDS instance Service Discovery namespace Application Load Balancer Bastion host Ad hoc environment resources include: ECS Cluster ECS Tasks and Services (for backend and frontend applications) ECS Tasks for running management commands (such as migrate) CloudWatch logging groups for containers defined in ECS Tasks ALB Target groups ALB listener rules Route 53 record that points to the load balancer (e.g. ) ad-hoc-env-name.example.com S3 bucket for static and media assets Service Discovery Service for redis service in ECS cluster Shared resources can be defined in one terraform configuration and deployed once. These resources will be long-lived as long as the application is under active development and the team requires on-demand provisioning of ad hoc environments. Ad hoc environment resources can be defined in another terraform configuration that references outputs from the shared resource configuration using . Each ad hoc environment can be defined by a file that contains the name of the ad hoc environment (such as , , , etc.). This value will also be the name of the Terraform workspace and will be used to name and tag AWS resources associated with the corresponding ad hoc environment. terraform_remote_state <name>.tfvars brian brian2 demo-feature-abc <name> The file will allow developers to use a simple, standard file interface for defining application specific values, such as the version of the backend and frontend. This brings developers into the concepts and practices of "infrastructure as code" and "configuration as code" and also helps the entire team keep track of how different environments are configured. <name>.tfvars Ad hoc environment files are stored in a directory of a special git repository that also defines the ad hoc environment terraform configuration. Currently, the files are stored . <name>.tfvars tfvars here Now let's look at the two terraform configurations used for defining and . shared resources ad hoc environment resources Ad Hoc Environment Diagram Here's an overview of the resources used for the ad hoc environments. The and the . letters represent shared resources numbers represent per-environment resources Shared architecture A. VPC (created using the ) official AWS VPC Module B. Public subnets for bastion host, NAT Gateways and Load Balancer C. Private subnets for application workloads and RDS D. Application Load Balancer that is shared between all ad hoc environments. A pre-provisioned wildcard ACM certificate is attached to the load balancer that is used to secure traffic for load-balanced ECS services E. Service discovery namespace that provides a namespace for application workloads to access the redis service running in ECS F. IAM roles needed for ECS tasks to access AWS services G. RDS instance using postgres engine that is shared between all ad hoc environments H. Bastion host used to access RDS from GitHub Actions (needed for creating per-environment databases) I. NAT Gateway used to give traffic in private subnets a route to the public internet Environment-specific architecture ECS Cluster that groups all ECS tasks for a single ad hoc environment Listener rules and target groups that direct traffic from the load balancer to the ECS services for an ad hoc environment. Redis service running in ECS that provides caching and serves as a task broker for celery Route53 records that point to the load balancer Frontend service that serves the Vue.js application over NGINX API service that serves the backend with Gunicorn Celery worker that process jobs in the default queue Celery beat that schedules celery tasks task collectstatic task migrate CloudWatch log groups are created for each ECS task in an ad hoc environment Each ad hoc environment gets a database in the shared RDS instance Shared resources terraform configuration Let's have a detailed look at the terraform configuration for shared resources that will support ad hoc environments. VPC We can use the for creating the shared VPC with Terraform. This module provides a high level interface that will provision lots of the components that are needed for a VPC following best practices, and it is less code for the DevOps team to manage compared to defining each component of a VPC (route tables, subnets, internet gateways, etc.). AWS VPC module Cloud Map Service Discovery Namespace Cloud Map is used in order to allow services in our ECS cluster to communicate with each other. The only reason that Cloud Map is needed is so that the backend services (API, celery workers, beat) can communicate with Redis, which will be an important service for our application, providing caching and also serving as a broker for celery. If we were to use Django Channels for websockets, the Redis service would also function as the backend for Django Channels. We will only need to specify on the redis service in our ECS cluster. What this will do is provide an address that our other services can use to communicate with redis. This address is created in the form of a Route 53 record, and it points to the private IP address of the redis service. If the private IP of the redis service is updated, the Route 53 record record for our redis service will be updated as well. service_registries In order for service discovery to work in the VPC that we created, we need to add the following options to the terraform AWS VPC module: # DNS settings enable_dns_hostnames = true enable_dns_support = true Security Groups There are two important security groups that we will set up as part of the shared infrastructure layer to be used by each ad hoc environment: one security group for the load balancer, and one security group where all of our ECS services will run. The load balancer security group will allow all traffic on port and for and traffic. The ECS security group will only allow inbound traffic from the application load balancer security group. It will also allow for traffic from port 6379 for redis traffic. 80 443 HTTP HTTPS IAM Roles There are two important IAM roles that we will need for our ECS tasks. We need a task execution role that our ECS tasks will use to interact with other AWS services, such as S3, Secrets Manager, etc. RDS Instance We will create one RDS instance in one of the private subnets in our VPC. This RDS instance will have one Postgres database per ad hoc environment. This RDS instance has a security group that allows all traffic from our ECS security group. Load Balancer We will use one load balancer for all ad hoc environments. This load balancer will have a wildcard ACM certificate attached to it ( , for example). Each ad hoc environment will create a Route 53 record that will point to this load balancer's public DNS name. For example, will be the address of my ad hoc environment. Requests to this address will then be routed to either the frontend ECS service or the backend ECS service depending on request header values and request path values that will be set on the listener rules. *.dev.example.com brian.dev.example.com By default, a load balancer supports up to 50 listener rules, so we can create plenty of ad hoc environments before we need to increase the default quota. There will be a discussion at the end of this article about AWS service quotas. Bastion Host The bastion host will be created in one of the VPC's public subnets. This will primarily be used for connecting to RDS to create new databases for new ad hoc environments, or for manually manipulating data in an ad hoc environment for debugging. Ad hoc environment resources Now that we have defined a shared set of infrastructure that our ad hoc environments will use, let's have a look at the resources that will be specific to ad hoc environments that will be added on top of the shared resources. ECS Cluster The ECS Cluster is a simple grouping of ECS tasks and services. ECS Tasks and Services Each environment will have a set of ECS tasks and services that will be used to run the application. There are four important ECS services in our application that are used to run "long-running" ECS tasks. Long-running tasks are tasks that start processes that run indefinitely, rather than running until completion. The long-running tasks in our application include: backend web application (gunciron web server) backend celery worker backend celery beat frontend web site (nginx web server) redis The infrastructure code also defines some tasks that are not long-running but rather short lived tasks that run until completion and do not start again. These tasks include: collectstatic database migrations any other ad-hoc task that we want to run, usually wrapped in a Django management command How to setup an ad hoc environment Now that we have been over the resources that will be created to support our ad hoc environments, let's talk about how we can enable individuals on our team to create and update ad hoc environments. Design decisions The devops team will decide on the interface that will be used for creating an ad hoc environment. Since we are using Terraform, this interface will be a Terraform configuration. The minimum amount of information that our ad hoc environment configuration needs is image tags for the frontend and backend images to use. Other configurations will be provided by default values set in , and these defaults can easily be overridden by passing values to and . I'm choosing to use as the way to pass configuration values to our ad hoc environments where is the name of the ad hoc environment being created. This will give us the following benefits: variables.tf terraform plan terraform apply <name>.tfvars <name> all ad hoc environments will be visible to the entire team in git since each ad hoc environment will have a file associated with it <name>.tfvars adding additional customization to an ad hoc environment does not add additional complexity to our automation pipeline since all customization is added through a single file that will be referenced by $WORKSPACE.tfvars The downsides of this approach are: creating ad hoc environments requires knowledge of git, so non-technical product team members might need help from the engineering team when setting up an ad hoc environment there is an additional "manual" step of creating a file that must be done before running a pipeline to create an ad hoc environment <name>.tfvars Provided that a file has been created and pushed to the repo, creating or updating an ad hoc environment will be as simple as running a pipeline in GitHub Actions that specifies the of our ad hoc environment. If no such file exists, our pipeline will fail. <name>.tfvars <name> <name>.tfvars GitHub Action Creating ad hoc environments will involve manually triggering a GitHub Action that runs on : workflow_dispatch on: workflow_dispatch: inputs: workspace: description: 'Name of terraform workspace to use' required: true default: 'dev' type: string We only have to enter the name of the ad hoc environment we want to create or update. The ad hoc environment name is used as the Terraform workspace name. This name is also the name of the file that must be created per environment. <name>.tfvars This workflow will do , and using the file. When everything has been created, we will use the AWS CLI to prepare the environment so that it can be used. We will use the command to run database migrations needed so that the application code can make database queries. terraform init terraform plan terraform apply <name>.tfvars aws ecs run-task How to update code in an existing ad hoc environment Assuming that we have deployed an ad hoc environment called with version of the backend application and of the frontend application, let's think about the process of updating the application to of the backend and of the frontend. brian v1.0.0 v2.0.0 v1.1.0 v2.1.0 The simplest approach to updating the application would be edit the file with the new versions: brian.tfvars # brian.tfvars be_image_tag = "v1.1.0" fe_image_tag = "v2.1.0" If we run the same pipeline that we initially used to deploy ad hoc environment (with , and ) against the updated file, this will result in a rolling update of the frontend and backend services ( ). terraform init terraform plan terraform apply brian.tfvars more on rolling updates here If there are database migrations included in the new version of the code that is going out, we need to run database migrations after the completes. We use a top level output from the ad hov environment terraform configuration that is a command with all appropriate arguments that will run database migrations when called from GitHub Actions. terraform apply run-task Order of Operations For ad hoc environments, it is probably fine to update the services and then run the database migrations. Ad hoc environments may only have a single "user" -- the developer, so . we don't need to worry about any errors that may occur if requests are made against the new version of code before database migrations have been applied Let's consider a simple example to illustrate what can go wrong here. If we add a to our blog post model to track the total number of page views a post has, we would add a field to the model, generate migration file with , and then update our views and model serializers to make use of this new field. In the time between updating our service and running the database migrations, any requests to endpoints that access the new database field will fail since the table does not yet exist. total_views makemigrations If we first run database migrations update application code (ECS services), then we can avoid errors about fields not existing. In our production application, we want to aim for fewer errors, so we should be using this "order of operations": first run new database migrations and then update application code. and then GitHub Action for application updates We need a GitHub Action that can do the following: fetch the current container definition JSON files for each backend tasks ( ) aws ecs describe-task-definition write new container definitions JSON with the new backend image tag (using ) jq register new task definitions with the new container definition JSON files for each task ( ) aws ecs register-task-definition call run-task with the newly updated migration ECS task ( ) aws ecs run-task wait for the task to exit and display the logs ( ) aws ecs wait tasks-stopped update the backend services (gunicorn, celery, celery beat) ( ) aws ecs update-service wait for the new backend services to be stable ( ) aws ecs wait services-stable Here's a visual representation of the backend update process: In order have the correct arguments for all of the AWS CLI calls used in the above workflow, we can use the AWS CLI to fetch resource names by tag. Here is what I'm using for the script. There lots of comments, so please refer to those comments for an explanation of what the script is doing. #!/bin/bash # This script will be called to update an ad hoc environment backend # with a new image tag. It will first run pre-update tasks (such as migrations) # and then do a rolling update of the backend services. # It is called from the ad_hock_backend_update.yml GitHub Actions file # Required environment variables that need to be exported before running this script: # WORKSPACE - ad hoc environment workspace # SHARED_RESOURCES_WORKSPACE - shared resources workspace # BACKEND_IMAGE_TAG - backend image tag to update services to (e.g. v1.2.3) # AWS_ACCOUNT_ID - AWS account ID is used for the ECR repository URL echo "Updating backend services..." # first define a variable containing the new image URI NEW_BACKEND_IMAGE_URI="$AWS_ACCOUNT_ID.dkr.ecr.us-east-1.amazonaws.com/backend:$BACKEND_IMAGE_TAG" # register new task definitions # https://docs.aws.amazon.com/cli/latest/reference/ecs/describe-task-definition.html#description for TASK in "migrate" "gunicorn" "default" "beat" do echo "Updating $TASK task definition..." # in Terraform we name our tasks based on the ad hoc environment name # (also the Terraform workspace name) and the name of the task # (e.g. migrate, gunicorn, default, beat) TASK_FAMILY=$WORKSPACE-$TASK # save the task definition JSON to a variable TASK_DESCRIPTION=$(aws ecs describe-task-definition \ --task-definition $TASK_FAMILY \ ) # save container definitions to a file for each task echo $TASK_DESCRIPTION | jq -r \ .taskDefinition.containerDefinitions \ > /tmp/$TASK_FAMILY.json # write new container definition JSON with updated image echo "Writing new $TASK_FAMILY container definitions JSON..." # replace old image URI with new image URI in a new container definitions JSON cat /tmp/$TASK_FAMILY.json \ | jq \ --arg IMAGE "$NEW_BACKEND_IMAGE_URI" '.[0].image |= $IMAGE' \ > /tmp/$TASK_FAMILY-new.json # Get the existing configuration for the task definition (memory, cpu, etc.) # from the variable that we saved the task definition JSON to earlier echo "Getting existing configuration for $TASK_FAMILY..." MEMORY=$( echo $TASK_DESCRIPTION | jq -r \ .taskDefinition.memory \ ) CPU=$( echo $TASK_DESCRIPTION | jq -r \ .taskDefinition.cpu \ ) ECS_EXECUTION_ROLE_ARN=$( echo $TASK_DESCRIPTION | jq -r \ .taskDefinition.executionRoleArn \ ) ECS_TASK_ROLE_ARN=$( echo $TASK_DESCRIPTION | jq -r \ .taskDefinition.taskRoleArn \ ) # check the content of the new container definition JSON cat /tmp/$TASK_FAMILY-new.json # register new task definition using the new container definitions # and the values that we read off of the existing task definitions echo "Registering new $TASK_FAMILY task definition..." aws ecs register-task-definition \ --family $TASK_FAMILY \ --container-definitions file:///tmp/$TASK_FAMILY-new.json \ --memory $MEMORY \ --cpu $CPU \ --network-mode awsvpc \ --execution-role-arn $ECS_EXECUTION_ROLE_ARN \ --task-role-arn $ECS_TASK_ROLE_ARN \ --requires-compatibilities "FARGATE" done # Now we need to run migrate, collectstatic and any other commands that need to be run # before doing a rolling update of the backend services # We will use the new task definitions we just created to run these commands # get the ARN of the most recent revision of the migrate task definition TASK_DEFINITION=$( \ aws ecs describe-task-definition \ --task-definition $WORKSPACE-migrate \ | jq -r \ .taskDefinition.taskDefinitionArn \ ) # get private subnets as space separated string from shared resources VPC SUBNETS=$( \ aws ec2 describe-subnets \ --filters "Name=tag:env,Values=$SHARED_RESOURCES_WORKSPACE" "Name=tag:Name,Values=*private*" \ --query 'Subnets[*].SubnetId' \ --output text \ ) # replace spaces with commas using tr SUBNET_IDS=$(echo $SUBNETS | tr ' ' ',') # https://github.com/aws/aws-cli/issues/5348 # get ecs_sg_id - just a single value ECS_SG_ID=$( \ aws ec2 describe-security-groups \ --filters "Name=tag:Name,Values=$SHARED_RESOURCES_WORKSPACE-ecs-sg" \ --query 'SecurityGroups[*].GroupId' \ --output text \ ) echo "Running database migrations..." # timestamp used for log retrieval (milliseconds after Jan 1, 1970 00:00:00 UTC) START_TIME=$(date +%s000) # run the migration task and capture the taskArn into a variable called TASK_ID TASK_ID=$( \ aws ecs run-task \ --cluster $WORKSPACE-cluster \ --task-definition $TASK_DEFINITION \ --network-configuration "awsvpcConfiguration={subnets=[$SUBNET_IDS],securityGroups=[$ECS_SG_ID],assignPublicIp=ENABLED}" \ | jq -r '.tasks[0].taskArn' \ ) echo "Task ID is $TASK_ID" # wait for the migrate task to exit # https://docs.aws.amazon.com/cli/latest/reference/ecs/wait/tasks-stopped.html#description # > It will poll every 6 seconds until a successful state has been reached. # > This will exit with a return code of 255 after 100 failed checks. aws ecs wait tasks-stopped \ --tasks $TASK_ID \ --cluster $WORKSPACE-cluster # timestamp used for log retrieval (milliseconds after Jan 1, 1970 00:00:00 UTC) END_TIME=$(date +%s000) # print the CloudWatch log events to STDOUT aws logs get-log-events \ --log-group-name "/ecs/$WORKSPACE/migrate" \ --log-stream-name "migrate/migrate/${TASK_ID##*/}" \ --start-time $START_TIME \ --end-time $END_TIME \ | jq -r '.events[].message' echo "Migrations complete. Starting rolling update for backend services..." # update backend services for TASK in "gunicorn" "default" "beat" do # get taskDefinitionArn for each service to be used in update-service command # this will get the most recent revision of each task (the one that was just created) # https://docs.aws.amazon.com/cli/latest/reference/ecs/describe-task-definition.html#description TASK_DEFINITION=$( \ aws ecs describe-task-definition \ --task-definition $WORKSPACE-$TASK \ | jq -r \ .taskDefinition.taskDefinitionArn \ ) # update each service with new task definintion aws ecs update-service \ --cluster $WORKSPACE-cluster \ --service $WORKSPACE-$TASK \ --task-definition $TASK_DEFINITION \ --no-cli-pager done echo "Services updated. Waiting for services to become stable..." # wait for all service to be stable (runningCount == desiredCount for each service) aws ecs wait services-stable \ --cluster $WORKSPACE-cluster \ --services $WORKSPACE-gunicorn $WORKSPACE-default $WORKSPACE-beat echo "Services are now stable. Backend services are now up to date with $BACKEND_IMAGE_TAG." echo "Backend update is now complete!" With this GitHub Actions workflow, a developer can now easily change the version of backend code that is running in their ad hoc environments without needing to involve Terraform. Using the GitHub Actions workflow, a developer only needs to enter the name of the workspace and the version of the backend code they want to use. The workflow will then run the task and update the backend services. ad_hoc_backend_update.yml migrate Using in the definitions ignore_changes There is one more important point to make about Terraform before we conclude this discussion on updating backend code for existing ad hoc environments. Consider the scenario where a developer has launched an ad hoc environment with backend version . They make a small change to the backend code and push version . Next, the developer remembers that a backend environment variable needs to be changed. This can be done by updating their file. If they now re-run the ad hoc environment update pipeline file, then their code will be reverted from to . We would need to coordinate version changes between updating the backend with the pipelines that use Terraform commands and the pipelines that use the AWS CLI commands. v1.0.0 v1.0.1 *.tfvars without also updating the backend version in their *.tfvars v1.0.1 v1.0.0 There is a setting on the resource in Terraform we can can use to prevent this from happening. This setting is called and is defined under the resource's configuration block. With this setting, when we update the file with our new environment variable value, we will create another recent task definition with the same image, but the ECS service will not update in response to this change (that's what the is for). Once we make the file update and redeploy using the Terraform pipeline, nothing on our ad hoc changes, but we did get a new task definitions defined in our AWS account for each backend service. When we go to make the backend update with the pipeline that uses AWS CLI commands, the most recent task revision is used to create the new task definition, so it will include the environment variable change that we added earlier. aws_ecs_service ignore_changes lifecycle *.tfvars v1.0.0 ignore_changes *.tfvars Frontend updates The process described above is needed for updating the backend application. Updating the frontend application involves a similar process to the backend update. The main difference is that no task (such as the command on the backend) needs to run before the service is updated. Here's an overview of the frontend update process: migrate fetch the container definition JSON for the frontend tasks ( ) aws ecs describe-task-definition write new container definition JSON with the new frontend image tag (using ) jq register new task definitions with the new container definition JSON file for the frontend task ( ) aws ecs register-task-definition update the frontend service ( ) aws ecs update-service wait for the new backend services to be stable ( ) aws ecs wait services-stable Setting up everything from a new AWS account and GitHub Actions Here's a quick overview of initial setup steps that are needed in order to use the automation defined in the GitHub Actions for ad hoc environments. Configure AWS credentials locally There is one Terraform command that we will run on our local machine to setup a remote backend for storing our Terraform state. In order to run this, we need to configure AWS credentials locally. Run the command make tf-bootstrap This command will setup an S3 bucket and DynamoDB table for storing Terraform state. Running this command will also require that a file has been created from the template. This will define the AWS region and name to be used for creating resources. bootstrap.tfvars Build and push a backend and frontend image The command also creates ECR repositories for the backend and frontend images. We can use the and GitHub Actions workflows to build and push the backend and frontend images to the ECR repositories. These pipelines accept a single parameter which is a git tag that must exist in the repo. This git tag will then be used as the image tag for the backend and frontend images. tf-bootstrap ecr_backend.yml ecr_frontend.yml Purchase a domain name in Route 53 I use Route 53 to manage DNS records, and have purchased a domain name that I use for testing and debugging in this and other projects. Create a wildcard ACM certificate I chose to create this certificate outside of Terraform and import it via ARN. We need a wildcard certificate so that multiple ad hoc environments can be hosted on subdomains of the same domain. Create a new EC2 key pair The key pair should be created manually and it needs to be added to GitHub repository secrets so that it can be used in the ad hoc environment pipelines. Add secrets to GitHub The following secrets are needed for GitHub Actions to run. Add these as repository secrets: - ARN of the wildcard ACM certificate ACM_CERTIFICATE_ARN - AWS access key ID AWS_ACCESS_KEY_ID - AWS account ID AWS_ACCOUNT_ID - AWS default region (I use ) AWS_DEFAULT_REGION us-east-1 - AWS secret access key AWS_SECRET_ACCESS_KEY - domain name for the ad hoc environment (e.g. ) DOMAIN_NAME example.com - name of the EC2 key pair KEY_NAME - private key for the EC2 key pair SSH_PRIVATE_KEY - name of the S3 bucket used for storing Terraform state TF_BACKEND_BUCKET - name of the DynamoDB table used for locking the Terraform state file TF_BACKEND_DYNAMODB_TABLE - AWS region for the S3 bucket and DynamoDB table TF_BACKEND_REGION These secrets are referenced in the GitHub Actions workflows. Create shared resources Now that we have GitHub secrets configured, we can run the GitHub Actions workflow. This will create shared resources environment in which we can build our ad hoc environments. This workflow requires a name (e.g. ). This require that we create a file in directory. This usually takes between 5 and 7 minutes to complete since it needs to create an RDS instance which takes a few minutes to provision. shared_resources_create_update.yml dev dev.tfvars terraform/live/shared-resources Create an ad hoc environment We can now create an ad hoc environment. This requires the name of the shared resources environment (e.g. ) and the name of the ad hoc environment (e.g. ). The only thing we need to do before creating the ad hoc environment is to create the file in the directory. This will define the versions of the application and any other environment configuration that is needed. This pipeline usually takes about 3 minutes to finish. dev brian-test brian-test brian-test.tfvars terraform/live/ad-hoc/envs Update the backend version in an ad hoc environment Now that the backend is up and running and usable, we can update the backend version used in our ad hoc environment. This can be done by running the GitHub Actions workflow. To run this workflow you must specify: ad_hoc_backend_update.yml the shared resource workspace (e.g. ) dev the ad hoc environment name (e.g. ) brian-test the new version of the backend to be used (e.g. ) v1.0.2 The backend version should already have been built and pushed to the ECR repository using the GitHub Actions workflow. ecr_backend.yml Use ECS Exec to access a Django shell in a running container Instead of SSHing into the container, we can use the command to access a shell in the container. This is useful for debugging and testing. One of the outputs of the ad hoc environment terraform configuration contains the script needed to run the command: ecs-exec ecs-exec TASK_ARN=$(aws ecs list-tasks \ --cluster alpha-cluster \ --service-name alpha-gunicorn | jq -r '.taskArns | .[0]' \ ) aws ecs execute-command --cluster alpha-cluster \ --task $TASK_ARN \ --container gunicorn \ --interactive \ --command "/bin/bash" You will then have a shell in the container: The Session Manager plugin was installed successfully. Use the AWS CLI to start a session. Starting session with SessionId: ecs-execute-command-073d1947fa71c058c root@ip-10-0-2-167:/code# python manage.py shell Python 3.9.9 (main, Dec 21 2021, 10:03:34) [GCC 10.2.1 20210110] on linux Type "help", "copyright", "credits" or "license" for more information. (InteractiveConsole) >>> Destroy an ad hoc environment Use the GitHub Actions workflow to destroy an ad hoc environment. To run this workflow you need to specify the shared resource workspace (e.g. ) and the ad hoc environment name (e.g. ). ad_hoc_env_destroy.yml dev brian-test Destroy the shared resources environment Use the GitHub Actions workflow to destroy the shared resources environment. To run this workflow you need to specify the shared resource workspace (e.g. ). shared_resources_destroy.yml dev This defines the full lifecycle of creating and destroying ad hoc environments. Future improvements, open questions and next steps Enhanced Security The low hanging fruit here is to use least privilege (for roles used in automation) and to define all roles with IaC. Currently I am using Admin roles for the credentials I store in GitHub which is a shortcut to using IaC and is not a best practice. Keeping track of ad hoc environments We need to think about how we can keep track of our active ad hoc environments. Active environments will incur additional AWS costs, and we do not want developers or the product team to create lots of environments and then leave them running without actively using them. We may decide to have some long-lived ad hoc environments, but those would be managed primarily by the DevOps team and respective owners (e.g. QA, product team, etc.). One way to check the active ad hoc environments would be to use the AWS CLI. We could list the ECS clusters in our development account, and this would show the number of ad hoc environments running. We could go farther and list the ad hoc environments by when they were last updated. We could then request developers or team members to remove ad hoc environments that are not in use. Or we could have a policy that all ad-hoc environments are deleted automatically at the end of each week. Terraform Tooling Testing Terraform Code Testing GitHub Actions Using advanced Terraform frameworks like Terragrunt Using Terraform Cloud for more advanced Terraform features More secure way of defining RDS username and password Currently the postgres database does not have a secure password. It is both hardcoded in the module as a default value and it will also be saved in plaintext in the Terraform state file. Backend application update script The script used for updating the backend application could be improved or broken up into multiple scripts to better handle errors and failures that happen during the pipeline. The script runs several different commands and could potentially fail at any step, so it would be nice to improve the error messages so that both developers and DevOps teams can more quickly diagnose pipeline failures. Limiting traffic to ad hoc environments to a VPN Another good next step would be to show how we can limit traffic to ad hoc environments to a VPN. Figure out how many ad hoc environments we can create with the default quotas AWS accounts limit the number of resources you can create, but for most of this quota limits you can request an increase per account. I need to figure out how many ad hoc environments I can create with the default quotas. Code Repo Organization One minor improvement would be to move the directory out of the monorepo into a dedicated repo. We may also want to move GitHub Actions for creating, updating and destroying environments to this new repo. For early stage development, using a single repository that stores both application code and Terraform configuration works, but it would be better to keep these separate at the repository level as the project grows. terraform django-step-by-step Multiple AWS Accounts Everything shown here uses a single AWS account: ECR images, Terraform remote state storage, all shared resource environments and all ad hoc environments. Using one account keeps things simple for a demonstration of this workflow, but in practice it would be beneficial to use multiple AWS accounts for different purposes. This would also involve more carefully planned IAM roles for cross-account resource access. Modules for stable environments to be used for long-lived pre-production and production environments This article looked at how to make tradeoffs between costs, speed of deployment and production parity in ad hoc environments. I'm interested in building a new set of modules that can be used to set up environments that: are more stable and more long-lived have less resource sharing (dedicated RDS and ElastiCache resources) implement autoscaling for load-testing (or maybe implement autoscaling for ad hoc environments) can be used to perform load testing have enhanced observability tooling These environments might be used as part of a QA process that does a final sign-off on a new set of features scheduled for deployment to production environments, for example. Conclusion This wraps up the tour of my ad hoc environment infrastructure automation. Thank you for having a read through my article. If you have a similar (or different) approach to building ad hoc environments, I would love to hear about it. Also Published Here