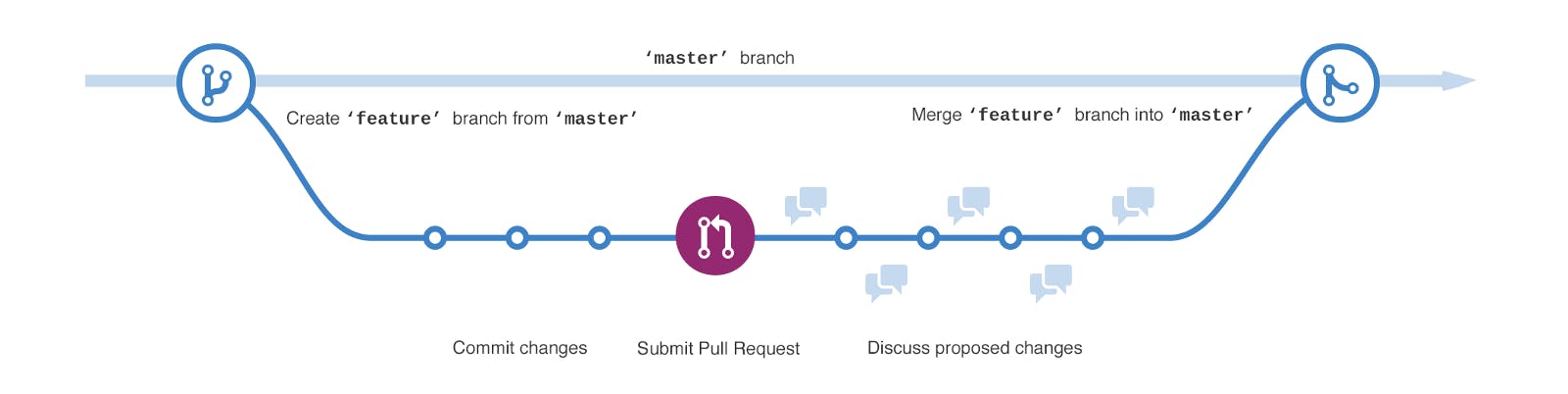
Ever since I learned Git, I’ve tried to follow . After all, it’s better than trying to wing it. It’s well-written. It even has a diagram, full of color and arrows—very stylish. the successful Git branching model However, I’ve found that it doesn’t fit perfectly with GitHub flow, where we use Pull Requests and Releases. I want our Git branching and merging to be simple, and have it work with our Github flow. Pull Requests We adopted Pull Requests, having each developer work in their own fork of the repo. This allows developers to create whatever branches they want without polluting the main fork of the repository. Before this, we had dozens of branches sitting in the main repository that belonged to no one. Now, each developer manages their own branches and does not confuse project newcomers with a pile of old or incomplete branches. Pull Requests , and even to enforce rules that require a review before a PR may be merged. include the ability to request a review from another developer GitHub Releases We use , and set our continuous deployment system to only deploy to production if we create a tag (like “v2.0.0”). When a release is created in GitHub, it creates that git tag pointing at the head of branch that you select. GitHub Releases Releases include documentation, which is usually a list of the PRs that have been merged. Hotfixes Hotfixes require their own process. the idea is that you need to patch something that is already in production, and it needs to go out right away. If there’s a new feature sitting in the “master” branch but not yet cleared for release, we need a patch to go to production without that. (No pushing of untested new features!) “Version bump” One of the reasons we switched to Github Releases was to get a more meaningful version number in our Rails project. (We use so that there’s a standard pattern to our releases.) semantic versioning By making some changes to our deployment process, I was able to get the Git tag to be available to the deployed application. Now our tools such as , , and include our real version number instead of the Git commit hash. Sentry New Relic Instrumental For our Ember development team, this was solved differently. They use the to bump the version stored inside the project. (The world has since moved on to Yarn, which I highly recommend, and which has the command.) npm version command yarn version What this means in practice is that after they merge pull requests into develop and merge develop into master, they check out master, “bump the version”, commit that, and then . This results in a deployment of the master branch with the new code and the old version number, followed by another deployment of the new code with the new version number. Not the cleanest workflow, but it does the job. merge it back into develop Goals The goals in general are to Deliver continuously! Be simple enough to remember. Be simple enough to easily follow without making mistakes. I suggest a new strategy If you use a separate “develop” branch, get rid of it. Just cut it out of the process. Having a single branch for changes makes things simpler, and tools will be better-behaved. All the diagrams you could ever want Here’s our example repository. I’m only showing the most recent commit in the master branch. We tagged it “v2.0.0”, so we know that, assuming the tests passed, commit “m” is live in production. Now an engineer creates a feature branch. A new feature branch has been added. The Key For the next section, I’ll use some visual aids to show an example Git repository and our use of pull requests and releases. Here’s the key to the following diagrams: Back in our story, more features branches are opened. We have lots of work happening in parallel. Two more feature branches. As the work is finished in “feature 1”, the engineer opens a pull request and it gets merged into the master branch. Feature 1 has been merged. And “feature 2” is also ready, so its pull request is also merged into the master branch. Feature 2 has been merged. We like to keep our repository clean, so once the pull request is merged, we hit the “Delete Branch” button in the pull request. Once merged, we delete the branch references to the feature branches. Now it’s time to release these new features. If this is one of our EmberCLI projects, we run “npm version”, which adds a commit bumping the version number. A new commit has been added to the master branch that changes the embedded version number. “npm version” also creates a tag for the version. But for non-npm projects, we create a Release using the GitHub website. Release tag v2.1.0 has been added, releasing the contents of the master branch. Our continuous deployment takes this and runs with it, placing version 2.1.0 into production. We continue working and we get “feature 3” merged into master. We don’t want to go live with too many things at once, so this feature has been waiting for v2.1.0 to go live. Feature 3 has been merged into the master branch and its branch reference has been deleted. Once feature 3 is merged, the master branch is deployed automatically to the staging site, where our team can start evaluating the new feature. But we just found a bug in production! According to Sentry, v2.1.0 is the first release where this bug appeared. An engineer creates a hotfix branch from the production release tag (v2.1.0) and writes a fix for the issue. A hotfix branch has been created using the most recent release tag as its base. The engineer adds a test for the issue (of course), and opens a pull request against “master”. Once the tests have run for this hotfix branch (we can see the result in the pull request), we know it’s safe to merge and release to production. For our npm-based project, it’s time to bump the version. The commit has been added to the hotfix branch, changing the embedded version number. We can merge the pull request, getting this hotfix in the master branch. Our hotfix branch has been merged into the master branch. But for this hotfix to get to production, it needs to be tagged. We don’t want to tag the master branch, because in addition to the hotfix, it has “feature 3” in it, which is pending acceptance testing. We need tag the head of the hotfix branch to get it into production. So we create a GitHub release. Side note: Because each of our developers opens branches in their own fork of the repository, the hotfix branch is in their fork, not in the main repository. (If we use “npm version” in this project, it will add a tag to the developer’s fork, not the main fork.) So to create a release pointing to the head of the hotfix branch, we must: First merge it into master. Select the commit that is the head of the hotfix branch from the “Recent Commits” list”. This is not the most recent commit, it’s likely the second one in the list. That is the biggest flaw I see in my proposal. This could be improved by GitHub, but I’m not sure exactly how. Now that a tag for v2.1.1 has been created, the hotfix gets deployed automatically. Release tag v2.1.1 has been added, releasing the contents of the hotfix branch. We can delete our hotfix branch. Its job is done, and we still have the v2.1.1 tag pointing to the same commit. The branch reference to the hotfix branch has been deleted. Since our hotfix was also merged into the master branch, it was already deployed to staging and is covered by our staging acceptance tests. Once our acceptance tests are done, we’re ready to release version 2.2.0. (If another hotfix has to be made before v2.2.0 is released, a new hotfix branch would be created from the v2.1.1 tag.) Release tag v2.2.0 has been added, releasing the contents of the master branch. That’s how I do it. I welcome any feedback!