147 reads
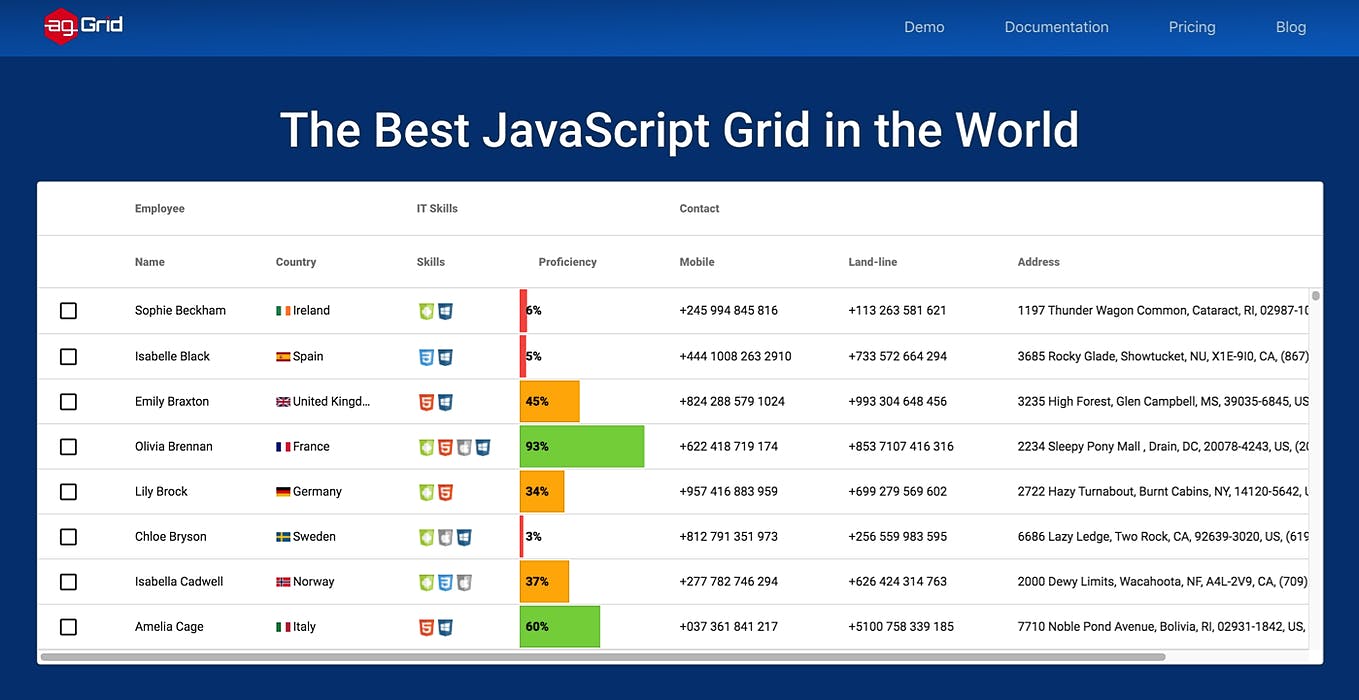
Operator Performance Tuning: Building a GUI for Prometheus Metrics Visualization in Kubernetes
by
December 15th, 2023






Audio Presented by

Story's Credibility


Story's Credibility
About Author

Senior Cloud Engineer at QuestDB
Comments

Senior Cloud Engineer at QuestDB