



































Jan 01, 1970
2,145 讀數
法学硕士正在改变人工智能应用程序:方法如下
太長; 讀書
人工智能是自 1994 年互联网诞生以来最具变革性的范式转变。企业正争先恐后地将人工智能融入到他们的业务方式中。发生这种情况的最重要方式之一是通过生成人工智能和大型语言模型。法学硕士正在迅速成为应用程序堆栈中不可或缺的一部分。人工智能是自 1994 年互联网诞生以来最具变革性的范式转变。可以理解的是,许多公司都在争先恐后地将人工智能融入到他们的业务方式中。
发生这种情况的最重要方式之一是通过生成式人工智能和大型语言模型 (LLM),这远远超出了要求 ChatGPT 为企业博客撰写有关特定主题的帖子甚至帮助编写代码的范围。
事实上,法学硕士正在迅速成为应用程序堆栈中不可或缺的一部分。
在包含所有必要数据并且可以“讲 LLM 语言”的数据库之上构建像 ChatGPT(“代理”)这样的生成式 AI 界面是移动应用程序的未来(并且越来越多地是现在)。
动态交互的水平、对大量公共和专有数据的访问以及适应特定情况的能力使得基于法学硕士构建的应用程序变得强大并且以一种直到最近才可用的方式参与。
这项技术已经迅速发展到几乎任何拥有正确数据库和正确 API 的人都可以构建这些体验。我们来看看其中涉及哪些内容。
生成式人工智能如何彻底改变应用程序的工作方式
当有些人在同一个句子中听到“代理”和“人工智能”时,他们会想到他们所体验过的简单聊天机器人,它会弹出一个窗口,询问当他们访问电子商务网站时它可以如何提供帮助。
但法学硕士可以做的不仅仅是通过简单的对话提示和从常见问题解答中提取的答案进行回应。
当他们能够访问正确的数据时,基于法学硕士构建的应用程序可以推动更先进的方式与我们互动,提供经过专业策划的更有用、更具体、更丰富的信息,而且往往具有惊人的先见之明。
这是一个例子。
您想在后院建造一个甲板,因此您打开家居装修商店的移动应用程序并要求它为您建立一个购物清单。
由于该应用程序连接到像 GPT-4 这样的 LLM 和多个数据源(公司自己的产品目录、商店库存、客户信息和订单历史记录,以及许多其他数据源),因此它可以轻松地告诉您您想要做什么。需要完成您的 DIY 项目。
但它还可以做更多的事情。
如果您描述了想要纳入套牌中的尺寸和功能,该应用程序可以提供可视化工具和设计辅助工具。因为它知道您的邮政编码,所以它可以告诉您附近的哪些商店有您需要的库存商品。
它还可以根据您的购买历史记录中的数据,建议您可能需要承包商来帮助您完成这项工作,并提供您附近的专业人员的联系信息。
然后它可以根据变量告诉您,例如甲板污渍干燥所需的时间(甚至结合您居住地的季节性气候趋势)以及您需要多长时间才能真正在甲板上举办生日派对你一直在计划。
该应用程序还可以协助并提供许多其他相关领域的信息,包括项目许可要求的详细信息以及施工对您的财产价值的影响。还有其他问题吗?
该应用程序可以作为有用的助手在每一步为您提供帮助,带您到达您想去的地方。
在您的申请中使用法学硕士很难,对吗?
这不是科幻小说。许多组织,包括一些最大的 DataStax 客户,目前正在开展多个包含生成式 AI 的项目。
但这些项目不仅仅是大型、成熟企业的领域;它们也是大型企业的领域。他们不需要有关机器学习或数据科学或 ML 模型训练的大量知识。
事实上,构建基于 LLM 的应用程序只需要一个能够进行数据库调用和 API 调用的开发人员。
构建可以提供直到最近闻所未闻的个性化上下文级别的应用程序已经成为现实,任何拥有正确数据库、几行代码和 GPT-4 等 LLM 的人都可以实现这一点。
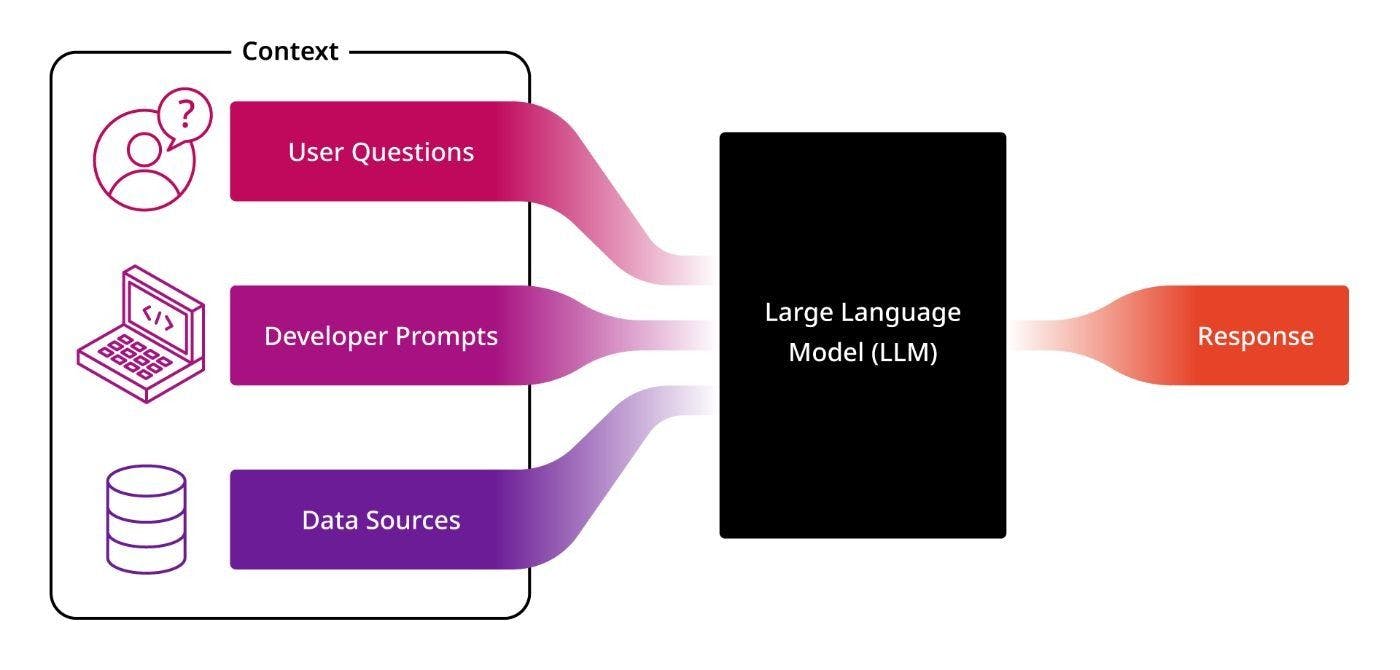
LLM 的使用非常简单。他们获取上下文(通常称为“提示”)并产生响应。因此,构建代理首先要考虑如何向 LLM 提供正确的上下文以获得所需的响应。
一般来说,此上下文来自三个地方:用户的问题、代理开发人员创建的预定义提示以及来自数据库或其他来源的数据(参见下图)。
用户提供的上下文通常只是他们输入到应用程序中的问题。
第二部分可以由与开发人员合作的产品经理提供,描述代理应扮演的角色(例如,“您是一位乐于助人的销售代理,正在努力帮助客户规划项目;请包括您的回复中的相关产品列表”)。
最后,提供的第三个上下文包括从数据库和其他数据源中提取的外部数据,LLM 在构建响应时应使用这些数据。
一些代理应用程序可能会在向用户输出响应之前多次调用 LLM,以便构建更详细的响应。
这就是 ChatGPT 插件和 LangChain 等技术所促进的(更多内容见下文)。
赋予法学硕士记忆……
人工智能代理需要知识来源,但这些知识必须是法学硕士可以理解的。让我们快速退一步思考一下法学硕士是如何运作的。当您向 ChatGPT 询问问题时,它的内存或“上下文窗口”非常有限。
如果您与 ChatGPT 进行扩展对话,它会打包您之前的查询和相应的响应,并将其发送回模型,但它开始“忘记”上下文。
这就是为什么将代理连接到数据库对于想要在法学硕士之上构建基于代理的应用程序的公司如此重要。但数据库必须以法学硕士能够理解的方式存储信息:作为向量。
简而言之,向量使您能够将句子、概念或图像简化为一组维度。您可以采用概念或上下文(例如产品描述),并将其转换为多个维度:向量的表示。
记录这些维度可以实现矢量搜索:能够搜索多维概念而不是关键字。
这有助于法学硕士生成更准确且适合上下文的响应,同时还为模型提供某种形式的长期记忆。从本质上讲,向量搜索是法学硕士与其接受培训的庞大知识库之间的重要桥梁。
向量是法学硕士的“语言”;矢量搜索是数据库所需的功能,为数据库提供上下文。
因此,能够为法学硕士提供适当数据的关键组成部分是矢量数据库,该数据库具有吞吐量、可扩展性和可靠性,可以处理促进代理体验所需的海量数据集。
...使用正确的数据库
可扩展性和性能是为任何 AI/ML 应用程序选择数据库时需要考虑的两个关键因素。代理需要访问大量实时数据并需要高速处理,尤其是在部署可能被每个访问您的网站或使用您的移动应用程序的客户使用的代理时。
在存储为代理应用程序提供数据的数据时,在需要时快速扩展的能力对于成功至关重要。
随着参与变得由代理驱动,Cassandra 通过提供水平可扩展性、速度和坚如磐石的稳定性而变得至关重要,这使其成为存储驱动基于代理的应用程序所需的数据的自然选择。
为此,Cassandra 社区开发了关键的
进展如何?
正如我们之前提到的,组织可以通过几种途径来创建代理应用程序体验。
您会听到开发人员谈论诸如
但推进构建此类体验的最重要方法是利用目前全球最受欢迎的代理:ChatGPT。
它成为了社交网络平台,拥有一个庞大的生态系统,由构建可以插入其中的游戏、内容和新闻源的组织组成。 ChatGPT 已经成为这样的平台:“超级代理”。
您的开发人员可能正在致力于使用像 LangChain 这样的框架来构建您自己的专有的基于代理的应用程序体验,但仅仅专注于这一点将带来巨大的机会成本。
如果他们不开发 ChatGPT 插件,您的组织将错过大量分发机会,将特定于您的业务的上下文集成到 ChatGPT 可以提供的可能信息或可以向用户推荐的操作范围中。
一系列公司,包括 Instacart、Expedia、OpenTable 和 Slack
变革的触手可及的推动者
构建 ChatGPT 插件将是企业希望参与的人工智能代理项目的关键部分。
拥有正确的数据架构(特别是矢量数据库)可以更轻松地构建非常高性能的代理体验,可以快速检索正确的信息来支持这些响应。
所有应用都将成为AI应用。 LLM 和 ChatGPT 插件等功能的兴起使这个未来变得更加容易实现。
要了解有关矢量搜索和生成人工智能的更多信息?欢迎加入我们的 Agent X:构建 Agent AI 体验,这是 7 月 11 日举行的免费数字活动。
作者:Ed Anuff,DataStax
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
標籤
Languages
这篇文章刊登在...
相關故事
关于 Promises、Thenables 和惰性求值你需要知道的一切
#web-development

Apple 客户将 Vision Pro 退回 #apple
Jan 01, 1970

疯狂埃迪的疯狂崛起:80 年代的电子商店如何欺骗投资者 #future-of-finance
Jan 01, 1970

