



































Jan 01, 1970
2,133 lectures
Les LLM transforment les applications d'IA : voici comment
Trop long; Pour lire
L'intelligence artificielle est le changement de paradigme le plus transformateur depuis l'arrivée d'Internet en 1994. Les entreprises s'efforcent d'intégrer l'IA dans leur façon de faire des affaires. L'IA générative et les grands modèles de langage sont l'un des moyens les plus importants d'y parvenir. Les LLM deviennent rapidement partie intégrante de la pile d'applications.L'intelligence artificielle est le changement de paradigme le plus transformateur depuis l'arrivée d'Internet en 1994. Et il y a beaucoup d'entreprises, naturellement, qui se bousculent pour insuffler l'IA dans leur façon de faire des affaires.
L'une des façons les plus importantes d'y parvenir est l'IA générative et les grands modèles de langage (LLM), et cela va bien au-delà de demander à ChatGPT d'écrire un article sur un sujet particulier pour un blog d'entreprise ou même d'aider à écrire du code.
En fait, les LLM deviennent rapidement partie intégrante de la pile d'applications.
Construire des interfaces IA génératives comme ChatGPT - "agents" - au-dessus d'une base de données qui contient toutes les données nécessaires et peut "parler le langage" des LLM est l'avenir (et, de plus en plus, le présent ) des applications mobiles.
Le niveau d'interaction dynamique, l'accès à de vastes quantités de données publiques et exclusives et la capacité à s'adapter à des situations spécifiques rendent les applications basées sur les LLM puissantes et engageantes d'une manière qui n'était pas disponible jusqu'à récemment.
Et la technologie a rapidement évolué au point que pratiquement n'importe qui disposant de la bonne base de données et des bonnes API peut créer ces expériences. Jetons un coup d'œil à ce qui est impliqué.
Comment l'IA générative révolutionne le fonctionnement des applications
Lorsque certaines personnes entendent « agent » et « IA » dans la même phrase, elles pensent au simple chatbot qu'elles ont expérimenté comme une fenêtre contextuelle qui leur demande comment cela peut les aider lorsqu'elles visitent un site de commerce électronique.
Mais les LLM peuvent faire bien plus que répondre avec de simples invites conversationnelles et des réponses tirées d'une FAQ.
Lorsqu'elles ont accès aux bonnes données, les applications basées sur les LLM peuvent conduire à des moyens beaucoup plus avancés d'interagir avec nous qui fournissent des informations organisées par des experts qui sont plus utiles, spécifiques, riches et souvent étrangement prémonitoires.
Voici un exemple.
Vous souhaitez construire une terrasse dans votre jardin, vous ouvrez donc l'application mobile de votre magasin de rénovation domiciliaire et lui demandez de vous créer une liste de courses.
Étant donné que l'application est connectée à un LLM tel que GPT-4 et à plusieurs sources de données (le catalogue de produits de l'entreprise, l'inventaire du magasin, les informations sur les clients et l'historique des commandes, ainsi qu'une multitude d'autres sources de données), elle peut facilement vous dire ce que vous aurez besoin pour terminer votre projet de bricolage.
Mais il peut faire beaucoup plus.
Si vous décrivez les dimensions et les fonctionnalités que vous souhaitez intégrer à votre terrasse, l'application peut proposer des outils de visualisation et des aides à la conception. Parce qu'il connaît votre code postal, il peut vous dire quels magasins à proximité ont les articles dont vous avez besoin en stock.
Il peut également, sur la base des données de votre historique d'achat, suggérer que vous pourriez avoir besoin d'un entrepreneur pour vous aider dans le travail - et fournir les coordonnées des professionnels près de chez vous.
Ensuite, il peut vous dire, en fonction de variables telles que le temps qu'il faut pour sécher la tache de terrasse (même en incorporant les tendances climatiques saisonnières où vous vivez) et combien de temps il vous faudra jusqu'à ce que vous puissiez réellement organiser cette fête d'anniversaire sur votre terrasse qui vous avez planifié.
L'application pourrait également aider et fournir des informations sur une foule d'autres domaines connexes, y compris des détails sur les exigences de permis de projet et l'effet de la construction sur la valeur de votre propriété. Vous avez d'autres questions ?
L'application peut vous aider à chaque étape du chemin en tant qu'assistant utile qui vous amène là où vous voulez aller.
L'utilisation de LLM dans votre application est difficile, n'est-ce pas ?
Ce n'est pas de la science-fiction. De nombreuses organisations, y compris certains des plus gros clients de DataStax, travaillent actuellement sur plusieurs projets qui intègrent l'IA générative.
Mais ces projets ne sont pas seulement le domaine des grandes entreprises établies ; ils ne nécessitent pas de vastes connaissances sur l'apprentissage automatique ou la science des données, ou la formation de modèles ML.
En fait, la création d'applications basées sur LLM ne nécessite guère plus qu'un développeur capable d'effectuer un appel de base de données et un appel d'API.
La création d'applications capables de fournir des niveaux de contexte personnalisés inédits jusqu'à récemment est une réalité qui peut être réalisée avec toute personne disposant de la bonne base de données, de quelques lignes de code et d'un LLM comme GPT-4.
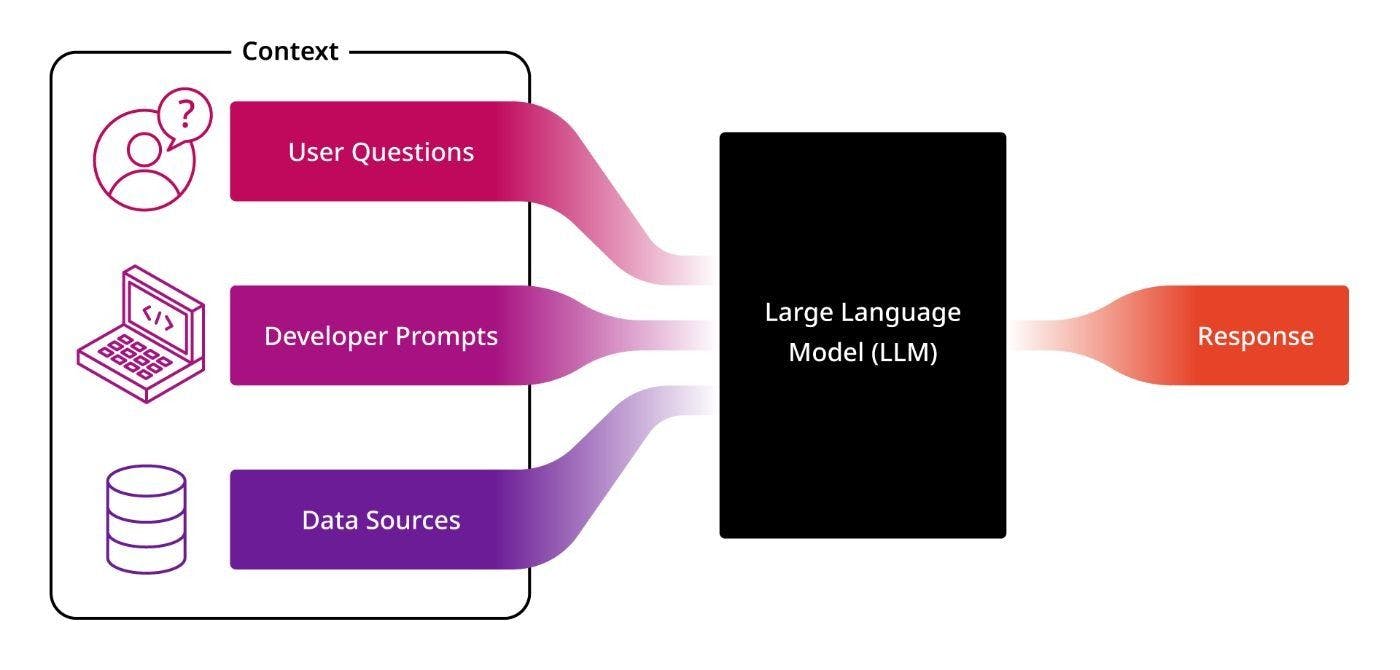
Les LLM sont très simples à utiliser. Ils prennent le contexte (souvent appelé « invite ») et produisent une réponse. Ainsi, la construction d'un agent commence par réfléchir à la manière de fournir le bon contexte au LLM pour obtenir la réponse souhaitée.
D'une manière générale, ce contexte provient de trois endroits : la question de l'utilisateur, les invites prédéfinies créées par le développeur de l'agent et les données provenant d'une base de données ou d'autres sources (voir le schéma ci-dessous).
Le contexte fourni par l'utilisateur est généralement simplement la question qu'il a saisie dans l'application.
Le deuxième élément peut être fourni par un chef de produit qui a travaillé avec un développeur pour décrire le rôle que l'agent doit jouer (par exemple, "Vous êtes un agent commercial utile qui essaie d'aider les clients à planifier leurs projets ; veuillez inclure un liste des produits pertinents dans vos réponses »).
Enfin, le troisième compartiment de contexte fourni comprend des données externes extraites de vos bases de données et d'autres sources de données que le LLM doit utiliser pour construire la réponse.
Certaines applications d'agent peuvent effectuer plusieurs appels au LLM avant de fournir la réponse à l'utilisateur afin de construire des réponses plus détaillées.
C'est ce que facilitent les technologies telles que les plug-ins ChatGPT et LangChain (plus d'informations ci-dessous).
Donner de la mémoire aux LLM…
Les agents d'IA ont besoin d'une source de connaissances, mais ces connaissances doivent être compréhensibles par un LLM. Prenons un peu de recul et réfléchissons au fonctionnement des LLM. Lorsque vous posez une question à ChatGPT, sa mémoire ou "fenêtre contextuelle" est très limitée.
Si vous avez une conversation prolongée avec ChatGPT, il regroupe vos requêtes précédentes et les réponses correspondantes et les renvoie au modèle, mais il commence à "oublier" le contexte.
C'est pourquoi la connexion d'un agent à une base de données est si importante pour les entreprises qui souhaitent créer des applications basées sur des agents au-dessus des LLM. Mais la base de données doit stocker les informations d'une manière qu'un LLM comprend : sous forme de vecteurs.
En termes simples, les vecteurs vous permettent de réduire une phrase, un concept ou une image en un ensemble de dimensions. Vous pouvez prendre un concept ou un contexte, comme une description de produit, et le transformer en plusieurs dimensions : une représentation d'un vecteur.
L'enregistrement de ces dimensions permet la recherche vectorielle : la possibilité de rechercher des concepts multidimensionnels plutôt que des mots-clés.
Cela aide les LLM à générer des réponses plus précises et adaptées au contexte tout en fournissant une forme de mémoire à long terme pour les modèles. Essentiellement, la recherche vectorielle est un pont vital entre les LLM et les vastes bases de connaissances sur lesquelles ils sont formés.
Les vecteurs sont le « langage » des LLM ; La recherche vectorielle est une capacité requise des bases de données qui leur fournit un contexte.
Par conséquent, un élément clé pour pouvoir servir les LLM avec les données appropriées est une base de données vectorielle qui a le débit, l'évolutivité et la fiabilité nécessaires pour gérer les énormes ensembles de données nécessaires pour alimenter les expériences des agents.
… Avec la bonne base de données
L'évolutivité et les performances sont deux facteurs essentiels à prendre en compte lors du choix d'une base de données pour toute application AI/ML. Les agents ont besoin d'accéder à de grandes quantités de données en temps réel et nécessitent un traitement à grande vitesse, en particulier lors du déploiement d'agents susceptibles d'être utilisés par chaque client qui visite votre site Web ou utilise votre application mobile.
La capacité à évoluer rapidement en cas de besoin est primordiale pour réussir lorsqu'il s'agit de stocker des données qui alimentent les applications d'agent.
À mesure que l'engagement devient propulsé par l'agent, Cassandra devient essentielle en offrant l'évolutivité horizontale, la vitesse et la stabilité à toute épreuve qui en font un choix naturel pour stocker les données nécessaires pour alimenter les applications basées sur l'agent.
Pour cette raison, la communauté Cassandra a développé la critique
Comment ça se fait ?
Les organisations disposent de plusieurs voies pour créer des expériences d'application d'agent, comme nous l'avons évoqué précédemment.
Vous entendrez des développeurs parler de frameworks comme
Mais le moyen le plus important d'aller de l'avant avec la création de ce type d'expériences est de puiser dans l'agent le plus populaire au monde à l'heure actuelle : ChatGPT.
C'est devenu la plate-forme de réseau social, avec un vaste écosystème d'organisations créant des jeux, du contenu et des flux d'actualités qui pourraient s'y connecter. ChatGPT est devenu ce genre de plateforme : un "super agent".
Vos développeurs travaillent peut-être à créer votre propre expérience d'application basée sur un agent propriétaire en utilisant un framework comme LangChain, mais se concentrer uniquement sur cela entraînera un coût d'opportunité énorme.
S'ils ne travaillent pas sur un plugin ChatGPT, votre organisation manquera une opportunité de distribution massive d'intégrer le contexte spécifique à votre entreprise dans la gamme d'informations possibles que ChatGPT peut fournir ou d'actions qu'il peut recommander à ses utilisateurs.
Une gamme d'entreprises, y compris Instacart, Expedia, OpenTable et Slack
Un agent de changement accessible
La création de plug-ins ChatGPT sera un élément essentiel des projets d'agents d'IA dans lesquels les entreprises chercheront à s'engager.
Disposer de la bonne architecture de données, en particulier une base de données vectorielle, facilite considérablement la création d'expériences d'agents très performantes capables de récupérer rapidement les bonnes informations pour alimenter ces réponses.
Toutes les applications deviendront des applications d'IA. La montée en puissance des LLM et des fonctionnalités telles que les plugins ChatGPT rend cet avenir beaucoup plus accessible.
Pour en savoir plus sur la recherche vectorielle et l'IA générative ? Rejoignez-nous pour Agent X : Build the Agent AI Experience, un événement numérique gratuit le 11 juillet.
Par Ed Anuff, DataStax
L O A D I N G
. . . comments & more!
. . . comments & more!



