



































Jan 01, 1970
2,133 lecturas
Los LLM están transformando las aplicaciones de IA: así es como
Demasiado Largo; Para Leer
La inteligencia artificial es el cambio de paradigma más transformador desde que Internet se afianzó en 1994. Las corporaciones se esfuerzan por incorporar la IA en la forma en que hacen negocios. Una de las formas más importantes en que esto sucede es a través de la IA generativa y los grandes modelos de lenguaje. Los LLM se están convirtiendo rápidamente en una parte integral de la pila de aplicaciones.La inteligencia artificial es el cambio de paradigma más transformador desde que Internet se afianzó en 1994. Y es comprensible que muchas corporaciones se esfuercen por infundir la IA en la forma en que hacen negocios.
Una de las formas más importantes en que esto sucede es a través de la IA generativa y los modelos de lenguaje extenso (LLM), y va mucho más allá de pedirle a ChatGPT que escriba una publicación sobre un tema en particular para un blog corporativo o incluso que ayude a escribir código.
De hecho, los LLM se están convirtiendo rápidamente en una parte integral de la pila de aplicaciones.
La creación de interfaces de IA generativas como ChatGPT, "agentes", sobre una base de datos que contiene todos los datos necesarios y puede "hablar el idioma" de los LLM es el futuro (y, cada vez más, el presente ) de las aplicaciones móviles.
El nivel de interacción dinámica, el acceso a grandes cantidades de datos públicos y propietarios, y la capacidad de adaptarse a situaciones específicas hacen que las aplicaciones basadas en LLM sean poderosas y atractivas de una manera que no estaba disponible hasta hace poco.
Y la tecnología ha evolucionado rápidamente hasta el punto de que prácticamente cualquier persona con la base de datos adecuada y las API adecuadas puede crear estas experiencias. Echemos un vistazo a lo que está involucrado.
Cómo la IA generativa revoluciona la forma en que funcionan las aplicaciones
Cuando algunas personas escuchan "agente" y "IA" en la misma oración, piensan en el chatbot simple que han experimentado como una ventana emergente que pregunta cómo puede ayudar cuando visitan un sitio de comercio electrónico.
Pero los LLM pueden hacer mucho más que responder con simples indicaciones de conversación y respuestas extraídas de preguntas frecuentes.
Cuando tienen acceso a los datos correctos, las aplicaciones creadas en LLM pueden impulsar formas mucho más avanzadas de interactuar con nosotros que brindan información curada por expertos que es más útil, específica, rica y, a menudo, asombrosamente profética.
Aquí hay un ejemplo.
Quiere construir una plataforma en su patio trasero, así que abre la aplicación móvil de su tienda de mejoras para el hogar y le pide que le haga una lista de compras.
Debido a que la aplicación está conectada a un LLM como GPT-4 y múltiples fuentes de datos (el propio catálogo de productos de la empresa, el inventario de la tienda, la información del cliente y el historial de pedidos, junto con una gran cantidad de otras fuentes de datos), puede decirle fácilmente lo que necesita. Tendrá que completar su proyecto de bricolaje.
Pero puede hacer mucho más.
Si describe las dimensiones y características que desea incorporar en su plataforma, la aplicación puede ofrecer herramientas de visualización y ayudas de diseño. Debido a que conoce su código postal, puede decirle qué tiendas cercanas tienen los artículos que necesita en stock.
También puede, en función de los datos de su historial de compras, sugerir que es posible que necesite un contratista que lo ayude con el trabajo y proporcionar información de contacto de profesionales cerca de usted.
Luego puede decirle, en función de variables como la cantidad de tiempo que tarda en secarse la mancha de la plataforma (incluso incorporando las tendencias climáticas estacionales donde vive) y cuánto tiempo pasará hasta que realmente pueda tener esa fiesta de cumpleaños en su plataforma que has estado planeando.
La solicitud también podría ayudar y proporcionar información sobre una serie de otras áreas relacionadas, incluidos detalles sobre los requisitos de permisos del proyecto y el efecto de la construcción en el valor de su propiedad. ¿Tienes más preguntas?
La aplicación puede ayudarlo en cada paso del camino como un asistente útil que lo lleva a donde quiere ir.
Usar LLM en su aplicación es difícil, ¿verdad?
Esto no es ciencia ficción. Muchas organizaciones, incluidos algunos de los clientes más grandes de DataStax, están trabajando en múltiples proyectos que incorporan IA generativa en este momento.
Pero estos proyectos no son solo el ámbito de las grandes empresas establecidas; no requieren un gran conocimiento sobre aprendizaje automático o ciencia de datos, o entrenamiento de modelos ML.
De hecho, la creación de aplicaciones basadas en LLM requiere poco más que un desarrollador que pueda realizar una llamada a la base de datos y una llamada a la API.
La creación de aplicaciones que pueden proporcionar niveles de contexto personalizado que no se conocían hasta hace poco es una realidad que puede realizarse con cualquier persona que tenga la base de datos adecuada, unas pocas líneas de código y un LLM como GPT-4.
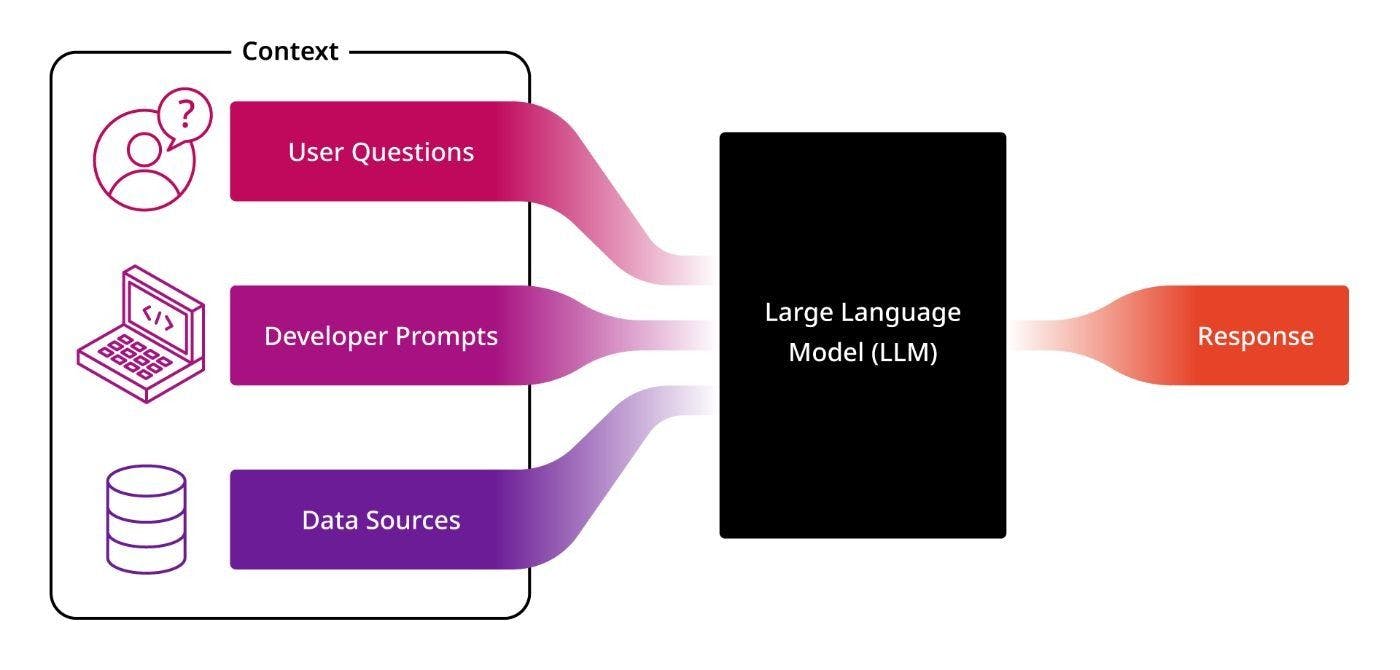
Los LLM son muy simples de usar. Toman contexto (a menudo denominado "indicador") y producen una respuesta. Entonces, construir un agente comienza pensando en cómo proporcionar el contexto adecuado al LLM para obtener la respuesta deseada.
En términos generales, este contexto proviene de tres lugares: la pregunta del usuario, las indicaciones predefinidas creadas por el desarrollador del agente y los datos obtenidos de una base de datos u otras fuentes (consulte el diagrama a continuación).
El contexto proporcionado por el usuario suele ser simplemente la pregunta que ingresa en la aplicación.
La segunda pieza podría ser proporcionada por un gerente de producto que trabajó con un desarrollador para describir el papel que debe desempeñar el agente (por ejemplo, "Usted es un agente de ventas útil que está tratando de ayudar a los clientes mientras planifican sus proyectos; incluya un lista de productos relevantes en sus respuestas”).
Finalmente, el tercer grupo de contexto provisto incluye datos externos extraídos de sus bases de datos y otras fuentes de datos que el LLM debería usar para construir la respuesta.
Algunas aplicaciones de agentes pueden realizar varias llamadas al LLM antes de enviar la respuesta al usuario para generar respuestas más detalladas.
Esto es lo que facilitan tecnologías como ChatGPT Plug-ins y LangChain (más sobre esto a continuación).
Dando memoria a los LLM…
Los agentes de IA necesitan una fuente de conocimiento, pero ese conocimiento debe ser comprensible para un LLM. Demos un paso atrás y pensemos cómo funcionan los LLM. Cuando le haces una pregunta a ChatGPT, tiene una memoria o "ventana de contexto" muy limitada.
Si tiene una conversación prolongada con ChatGPT, empaqueta sus consultas anteriores y las respuestas correspondientes y las envía de regreso al modelo, pero comienza a "olvidar" el contexto.
Esta es la razón por la que conectar un agente a una base de datos es tan importante para las empresas que desean crear aplicaciones basadas en agentes además de los LLM. Pero la base de datos tiene que almacenar información de una manera que un LLM entienda: como vectores.
En pocas palabras, los vectores le permiten reducir una oración, un concepto o una imagen a un conjunto de dimensiones. Puede tomar un concepto o contexto, como la descripción de un producto, y convertirlo en varias dimensiones: una representación de un vector.
El registro de esas dimensiones permite la búsqueda vectorial: la capacidad de buscar conceptos multidimensionales, en lugar de palabras clave.
Esto ayuda a los LLM a generar respuestas más precisas y contextualmente apropiadas al mismo tiempo que proporciona una forma de memoria a largo plazo para los modelos. En esencia, la búsqueda de vectores es un puente vital entre los LLM y las vastas bases de conocimiento en las que se capacitan.
Los vectores son el "lenguaje" de los LLM; La búsqueda vectorial es una capacidad requerida de las bases de datos que les proporciona contexto.
En consecuencia, un componente clave para poder servir a los LLM con los datos apropiados es una base de datos vectorial que tenga el rendimiento, la escalabilidad y la confiabilidad para manejar los conjuntos de datos masivos necesarios para impulsar las experiencias de los agentes.
… con la base de datos adecuada
La escalabilidad y el rendimiento son dos factores críticos a tener en cuenta al elegir una base de datos para cualquier aplicación de IA/ML. Los agentes requieren acceso a grandes cantidades de datos en tiempo real y requieren un procesamiento de alta velocidad, especialmente cuando se implementan agentes que pueden ser utilizados por todos los clientes que visitan su sitio web o usan su aplicación móvil.
La capacidad de escalar rápidamente cuando sea necesario es fundamental para el éxito cuando se trata de almacenar datos que alimentan las aplicaciones de los agentes.
A medida que el compromiso pasa a ser impulsado por agentes, Cassandra se vuelve esencial al proporcionar la escalabilidad horizontal, la velocidad y la estabilidad sólida que lo convierte en una opción natural para almacenar los datos necesarios para potenciar las aplicaciones basadas en agentes.
Por esta razón, la comunidad de Cassandra desarrolló la crítica
¿Cómo se hace?
Hay algunas rutas para que las organizaciones creen experiencias de aplicaciones de agentes, como mencionamos anteriormente.
Escuchará a los desarrolladores hablar sobre marcos como
Pero la forma más importante de avanzar en la creación de este tipo de experiencias es aprovechar el agente más popular del mundo en este momento: ChatGPT.
Se convirtió en la plataforma de la red social, con un enorme ecosistema de organizaciones que creaban juegos, contenido y fuentes de noticias que podían conectarse. ChatGPT se ha convertido en ese tipo de plataforma: un "súper agente".
Es posible que sus desarrolladores estén trabajando en la creación de su propia experiencia de aplicación basada en agentes patentados utilizando un marco como LangChain, pero centrarse únicamente en eso tendrá un gran costo de oportunidad.
Si no están trabajando en un complemento de ChatGPT, su organización perderá una oportunidad de distribución masiva para integrar el contexto que es específico de su negocio en el rango de información posible que ChatGPT puede proporcionar o acciones que puede recomendar a sus usuarios.
Una gama de empresas, incluidas Instacart, Expedia, OpenTable y Slack
Un agente accesible para el cambio
La creación de complementos de ChatGPT será una parte fundamental de los proyectos de agentes de IA en los que las empresas buscarán participar.
Tener la arquitectura de datos correcta, en particular, una base de datos vectorial, hace que sea sustancialmente más fácil crear experiencias de agente de muy alto rendimiento que puedan recuperar rápidamente la información correcta para impulsar esas respuestas.
Todas las aplicaciones se convertirán en aplicaciones de IA. El auge de los LLM y capacidades como los complementos de ChatGPT está haciendo que este futuro sea mucho más accesible.
¿Desea obtener más información sobre la búsqueda de vectores y la IA generativa? Únase a nosotros para Agent X: Build the Agent AI Experience, un evento digital gratuito el 11 de julio.
Por Ed Anuff, DataStax
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
ETIQUETAS
Languages
ESTE ARTÍCULO FUE PRESENTADO EN...
HISTORIAS RELACIONADAS

Slogging Insights: Why Did You Become a Writer? #slogging
Jan 01, 1970

552 Stories To Learn About Hackernoon #hackernoon
Jan 01, 1970

